 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Chronicles of Foundation AI for Forensics of Multi-Agent Provenance
Apr 17, 2025Provenance is the chronology of things, resonating with the fundamental pursuit to uncover origins, trace connections, and situate entities within the flow of space and time. As artificial intelligence advances towards autonomous agents capable of interactive collaboration on complex tasks, the provenance of generated content becomes entangled in the interplay of collective creation, where contributions are continuously revised, extended or overwritten. In a multi-agent generative chain, content undergoes successive transformations, often leaving little, if any, trace of prior contributions. In this study, we investigates the problem of tracking multi-agent provenance across the temporal dimension of generation. We propose a chronological system for post hoc attribution of generative history from content alone, without reliance on internal memory states or external meta-information. At its core lies the notion of symbolic chronicles, representing signed and time-stamped records, in a form analogous to the chain of custody in forensic science. The system operates through a feedback loop, whereby each generative timestep updates the chronicle of prior interactions and synchronises it with the synthetic content in the very act of generation. This research seeks to develop an accountable form of collaborative artificial intelligence within evolving cyber ecosystems.
AnimeDL-2M: Million-Scale AI-Generated Anime Image Detection and Localization in Diffusion Era
Apr 15, 2025



Recent advances in image generation, particularly diffusion models, have significantly lowered the barrier for creating sophisticated forgeries, making image manipulation detection and localization (IMDL) increasingly challenging. While prior work in IMDL has focused largely on natural images, the anime domain remains underexplored-despite its growing vulnerability to AI-generated forgeries. Misrepresentations of AI-generated images as hand-drawn artwork, copyright violations, and inappropriate content modifications pose serious threats to the anime community and industry. To address this gap, we propose AnimeDL-2M, the first large-scale benchmark for anime IMDL with comprehensive annotations. It comprises over two million images including real, partially manipulated, and fully AI-generated samples. Experiments indicate that models trained on existing IMDL datasets of natural images perform poorly when applied to anime images, highlighting a clear domain gap between anime and natural images. To better handle IMDL tasks in anime domain, we further propose AniXplore, a novel model tailored to the visual characteristics of anime imagery. Extensive evaluations demonstrate that AniXplore achieves superior performance compared to existing methods. Dataset and code can be found in https://flytweety.github.io/AnimeDL2M/.
Steganography Beyond Space-Time With Chain of Multimodal AI Agents
Feb 25, 2025Steganography is the art and science of covert writing, with a broad range of applications interwoven within the realm of cybersecurity. As artificial intelligence continues to evolve, its ability to synthesise realistic content emerges as a threat in the hands of cybercriminals who seek to manipulate and misrepresent the truth. Such synthetic content introduces a non-trivial risk of overwriting the subtle changes made for the purpose of steganography. When the signals in both the spatial and temporal domains are vulnerable to unforeseen overwriting, it calls for reflection on what can remain invariant after all. This study proposes a paradigm in steganography for audiovisual media, where messages are concealed beyond both spatial and temporal domains. A chain of multimodal agents is developed to deconstruct audiovisual content into a cover text, embed a message within the linguistic domain, and then reconstruct the audiovisual content through synchronising both aural and visual modalities with the resultant stego text. The message is encoded by biasing the word sampling process of a language generation model and decoded by analysing the probability distribution of word choices. The accuracy of message transmission is evaluated under both zero-bit and multi-bit capacity settings. Fidelity is assessed through both biometric and semantic similarities, capturing the identities of the recorded face and voice, as well as the core ideas conveyed through the media. Secrecy is examined through statistical comparisons between cover and stego texts. Robustness is tested across various scenarios, including audiovisual compression, face-swapping, voice-cloning and their combinations.
Imitation Game for Adversarial Disillusion with Multimodal Generative Chain-of-Thought Role-Play
Jan 31, 2025



As the cornerstone of artificial intelligence, machine perception confronts a fundamental threat posed by adversarial illusions. These adversarial attacks manifest in two primary forms: deductive illusion, where specific stimuli are crafted based on the victim model's general decision logic, and inductive illusion, where the victim model's general decision logic is shaped by specific stimuli. The former exploits the model's decision boundaries to create a stimulus that, when applied, interferes with its decision-making process. The latter reinforces a conditioned reflex in the model, embedding a backdoor during its learning phase that, when triggered by a stimulus, causes aberrant behaviours. The multifaceted nature of adversarial illusions calls for a unified defence framework, addressing vulnerabilities across various forms of attack. In this study, we propose a disillusion paradigm based on the concept of an imitation game. At the heart of the imitation game lies a multimodal generative agent, steered by chain-of-thought reasoning, which observes, internalises and reconstructs the semantic essence of a sample, liberated from the classic pursuit of reversing the sample to its original state. As a proof of concept, we conduct experimental simulations using a multimodal generative dialogue agent and evaluates the methodology under a variety of attack scenarios.
GreedyPixel: Fine-Grained Black-Box Adversarial Attack Via Greedy Algorithm
Jan 24, 2025A critical requirement for deep learning models is ensuring their robustness against adversarial attacks. These attacks commonly introduce noticeable perturbations, compromising the visual fidelity of adversarial examples. Another key challenge is that while white-box algorithms can generate effective adversarial perturbations, they require access to the model gradients, limiting their practicality in many real-world scenarios. Existing attack mechanisms struggle to achieve similar efficacy without access to these gradients. In this paper, we introduce GreedyPixel, a novel pixel-wise greedy algorithm designed to generate high-quality adversarial examples using only query-based feedback from the target model. GreedyPixel improves computational efficiency in what is typically a brute-force process by perturbing individual pixels in sequence, guided by a pixel-wise priority map. This priority map is constructed by ranking gradients obtained from a surrogate model, providing a structured path for perturbation. Our results demonstrate that GreedyPixel achieves attack success rates comparable to white-box methods without the need for gradient information, and surpasses existing algorithms in black-box settings, offering higher success rates, reduced computational time, and imperceptible perturbations. These findings underscore the advantages of GreedyPixel in terms of attack efficacy, time efficiency, and visual quality.
Cyber-Physical Steganography in Robotic Motion Control
Jan 08, 2025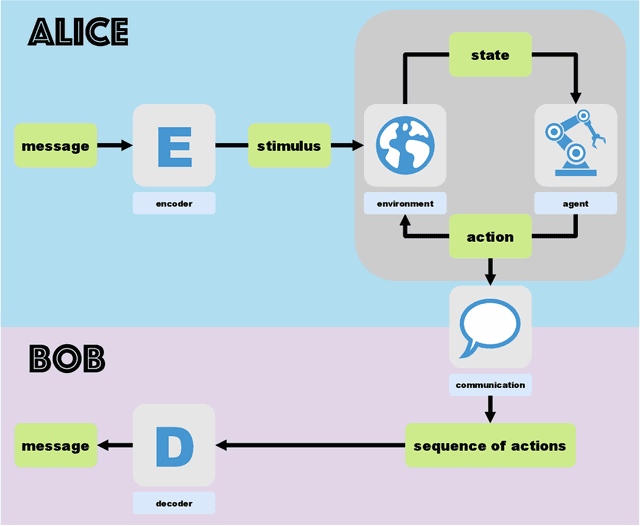

Steganography, the art of information hiding, has continually evolved across visual, auditory and linguistic domains, adapting to the ceaseless interplay between steganographic concealment and steganalytic revelation. This study seeks to extend the horizons of what constitutes a viable steganographic medium by introducing a steganographic paradigm in robotic motion control. Based on the observation of the robot's inherent sensitivity to changes in its environment, we propose a methodology to encode messages as environmental stimuli influencing the motions of the robotic agent and to decode messages from the resulting motion trajectory. The constraints of maximal robot integrity and minimal motion deviation are established as fundamental principles underlying secrecy. As a proof of concept, we conduct experiments in simulated environments across various manipulation tasks, incorporating robotic embodiments equipped with generalist multimodal policies.
Steganography in Game Actions
Dec 11, 2024The problem of subliminal communication has been addressed in various forms of steganography, primarily relying on visual, auditory and linguistic media. However, the field faces a fundamental paradox: as the art of concealment advances, so too does the science of revelation, leading to an ongoing evolutionary interplay. This study seeks to extend the boundaries of what is considered a viable steganographic medium. We explore a steganographic paradigm, where hidden information is communicated through the episodes of multiple agents interacting with an environment. Each agent, acting as an encoder, learns a policy to disguise the very existence of hidden messages within actions seemingly directed toward innocent objectives. Meanwhile, an observer, serving as a decoder, learns to associate behavioural patterns with their respective agents despite their dynamic nature, thereby unveiling the hidden messages. The interactions of agents are governed by the framework of multi-agent reinforcement learning and shaped by feedback from the observer. This framework encapsulates a game-theoretic dilemma, wherein agents face decisions between cooperating to create distinguishable behavioural patterns or defecting to pursue individually optimal yet potentially overlapping episodic actions. As a proof of concept, we exemplify action steganography through the game of labyrinth, a navigation task where subliminal communication is concealed within the act of steering toward a destination. The stego-system has been systematically validated through experimental evaluations, assessing its distortion and capacity alongside its secrecy and robustness when subjected to simulated passive and active adversaries.
Purification-Agnostic Proxy Learning for Agentic Copyright Watermarking against Adversarial Evidence Forgery
Sep 03, 2024With the proliferation of AI agents in various domains, protecting the ownership of AI models has become crucial due to the significant investment in their development. Unauthorized use and illegal distribution of these models pose serious threats to intellectual property, necessitating effective copyright protection measures. Model watermarking has emerged as a key technique to address this issue, embedding ownership information within models to assert rightful ownership during copyright disputes. This paper presents several contributions to model watermarking: a self-authenticating black-box watermarking protocol using hash techniques, a study on evidence forgery attacks using adversarial perturbations, a proposed defense involving a purification step to counter adversarial attacks, and a purification-agnostic proxy learning method to enhance watermark reliability and model performance. Experimental results demonstrate the effectiveness of these approaches in improving the security, reliability, and performance of watermarked models.
Enhancing Robustness of LLM-Synthetic Text Detectors for Academic Writing: A Comprehensive Analysis
Jan 16, 2024The emergence of large language models (LLMs), such as Generative Pre-trained Transformer 4 (GPT-4) used by ChatGPT, has profoundly impacted the academic and broader community. While these models offer numerous advantages in terms of revolutionizing work and study methods, they have also garnered significant attention due to their potential negative consequences. One example is generating academic reports or papers with little to no human contribution. Consequently, researchers have focused on developing detectors to address the misuse of LLMs. However, most existing methods prioritize achieving higher accuracy on restricted datasets, neglecting the crucial aspect of generalizability. This limitation hinders their practical application in real-life scenarios where reliability is paramount. In this paper, we present a comprehensive analysis of the impact of prompts on the text generated by LLMs and highlight the potential lack of robustness in one of the current state-of-the-art GPT detectors. To mitigate these issues concerning the misuse of LLMs in academic writing, we propose a reference-based Siamese detector named Synthetic-Siamese which takes a pair of texts, one as the inquiry and the other as the reference. Our method effectively addresses the lack of robustness of previous detectors (OpenAI detector and DetectGPT) and significantly improves the baseline performances in realistic academic writing scenarios by approximately 67% to 95%.
Nonlinear Discrete Optimisation of Reversible Steganographic Coding
Feb 26, 2022



Authentication mechanisms are at the forefront of defending the world from various types of cybercrime. Steganography can serve as an authentication solution by embedding a digital signature into a carrier object to ensure the integrity of the object and simultaneously lighten the burden of metadata management. However, steganographic distortion, albeit generally imperceptible to human sensory systems, might be inadmissible in fidelity-sensitive situations. This has led to the concept of reversible steganography. A fundamental element of reversible steganography is predictive analytics, for which powerful neural network models have been effectively deployed. As another core aspect, contemporary reversible steganographic coding is based primarily on heuristics and therefore worth further study. While attempts have been made to realise automatic coding with neural networks, perfect reversibility is still unreachable via such an unexplainable intelligent machinery. Instead of relying on deep learning, we aim to derive an optimal coding by means of mathematical optimisation. In this study, we formulate reversible steganographic coding as a nonlinear discrete optimisation problem with a logarithmic capacity constraint and a quadratic distortion objective. Linearisation techniques are developed to enable mixed-integer linear programming. Experimental results validate the near-optimality of the proposed optimisation algorithm benchmarked against a brute-force method.