 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaVA-ReID: Selective Multi-image Questioner for Interactive Person Re-Identification
Apr 15, 2025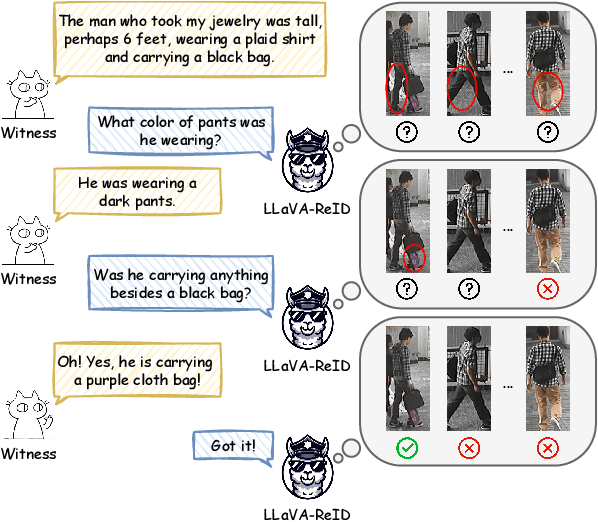
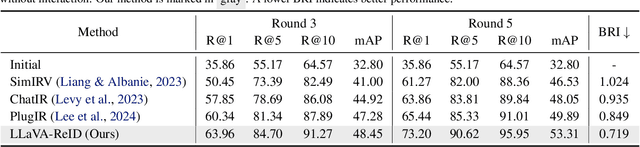
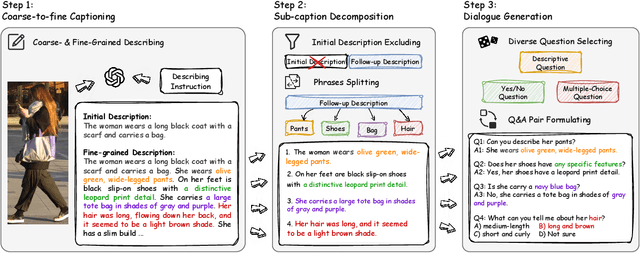
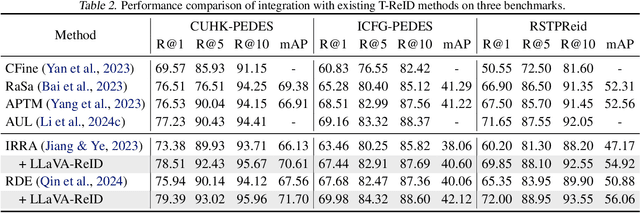
Traditional text-based person ReID assumes that person descriptions from witnesses are complete and provided at once. However, in real-world scenarios, such descriptions are often partial or vague. To address this limitation, we introduce a new task called interactive person re-identification (Inter-ReID). Inter-ReID is a dialogue-based retrieval task that iteratively refines initial descriptions through ongoing interactions with the witnesses. To facilitate the study of this new task, we construct a dialogue dataset that incorporates multiple types of questions by decomposing fine-grained attributes of individuals. We further propose LLaVA-ReID, a question model that generates targeted questions based on visual and textual contexts to elicit additional details about the target person. Leveraging a looking-forward strategy, we prioritize the most informative questions as supervision during training. Experimental results on both Inter-ReID and text-based ReID benchmarks demonstrate that LLaVA-ReID significantly outperforms baselines.
Cyber-Physical Steganography in Robotic Motion Control
Jan 08, 2025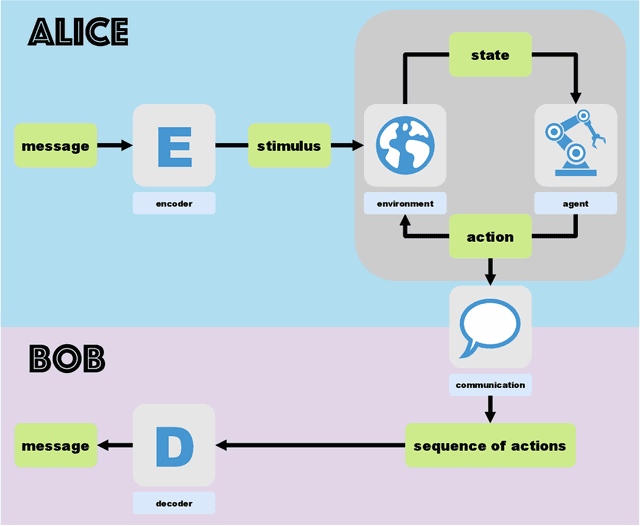

Steganography, the art of information hiding, has continually evolved across visual, auditory and linguistic domains, adapting to the ceaseless interplay between steganographic concealment and steganalytic revelation. This study seeks to extend the horizons of what constitutes a viable steganographic medium by introducing a steganographic paradigm in robotic motion control. Based on the observation of the robot's inherent sensitivity to changes in its environment, we propose a methodology to encode messages as environmental stimuli influencing the motions of the robotic agent and to decode messages from the resulting motion trajectory. The constraints of maximal robot integrity and minimal motion deviation are established as fundamental principles underlying secrecy. As a proof of concept, we conduct experiments in simulated environments across various manipulation tasks, incorporating robotic embodiments equipped with generalist multimodal policies.
A Survey on Deep Clustering: From the Prior Perspective
Jun 28, 2024Facilitated by the powerful feature extraction ability of neural networks, deep clustering has achieved great success in analyzing high-dimensional and complex real-world data. The performance of deep clustering methods is affected by various factors such as network structures and learning objectives. However, as pointed out in this survey, the essence of deep clustering lies in the incorporation and utilization of prior knowledge, which is largely ignored by existing works. From pioneering deep clustering methods based on data structure assumptions to recent contrastive clustering methods based on data augmentation invariances, the development of deep clustering intrinsically corresponds to the evolution of prior knowledge. In this survey, we provide a comprehensive review of deep clustering methods by categorizing them into six types of prior knowledge. We find that in general the prior innovation follows two trends, namely, i) from mining to constructing, and ii) from internal to external. Besides, we provide a benchmark on five widely-used datasets and analyze the performance of methods with diverse priors. By providing a novel prior knowledge perspective, we hope this survey could provide some novel insights and inspire future research in the deep clustering community.
Multi-granularity Correspondence Learning from Long-term Noisy Videos
Jan 30, 2024



Existing video-language studies mainly focus on learning short video clips, leaving long-term temporal dependencies rarely explored due to over-high computational cost of modeling long videos. To address this issue, one feasible solution is learning the correspondence between video clips and captions, which however inevitably encounters the multi-granularity noisy correspondence (MNC) problem. To be specific, MNC refers to the clip-caption misalignment (coarse-grained) and frame-word misalignment (fine-grained), hindering temporal learning and video understanding. In this paper, we propose NOise Robust Temporal Optimal traNsport (Norton) that addresses MNC in a unified optimal transport (OT) framework. In brief, Norton employs video-paragraph and clip-caption contrastive losses to capture long-term dependencies based on OT. To address coarse-grained misalignment in video-paragraph contrast, Norton filters out the irrelevant clips and captions through an alignable prompt bucket and realigns asynchronous clip-caption pairs based on transport distance. To address the fine-grained misalignment, Norton incorporates a soft-maximum operator to identify crucial words and key frames. Additionally, Norton exploits the potential faulty negative samples in clip-caption contrast by rectifying the alignment target with OT assignment to ensure precise temporal modeling. Extensive experiments on video retrieval, videoQA, and action segmentation verify the effectiveness of our method. Code is available at https://lin-yijie.github.io/projects/Norton.
Decoupled Contrastive Multi-view Clustering with High-order Random Walks
Aug 22, 2023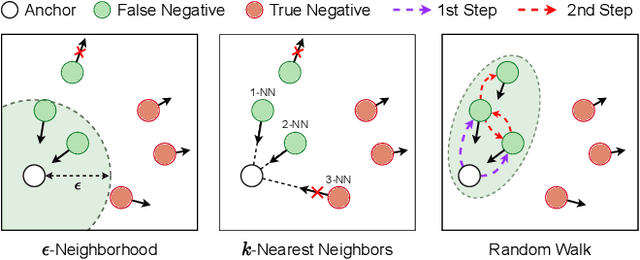
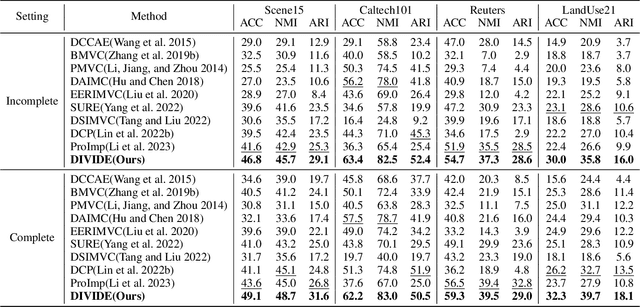
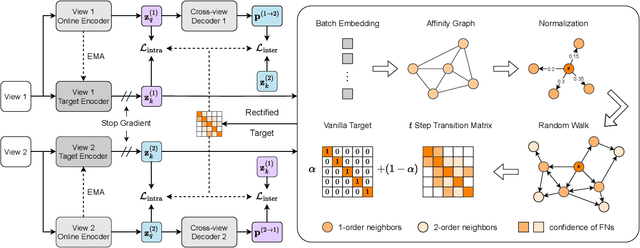
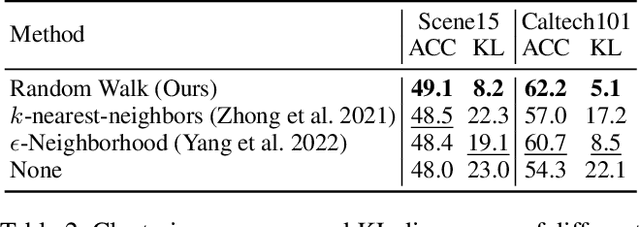
In recent, some robust contrastive multi-view clustering (MvC) methods have been proposed, which construct data pairs from neighborhoods to alleviate the false negative issue, i.e., some intra-cluster samples are wrongly treated as negative pairs. Although promising performance has been achieved by these methods, the false negative issue is still far from addressed and the false positive issue emerges because all in- and out-of-neighborhood samples are simply treated as positive and negative, respectively. To address the issues, we propose a novel robust method, dubbed decoupled contrastive multi-view clustering with high-order random walks (DIVIDE). In brief, DIVIDE leverages random walks to progressively identify data pairs in a global instead of local manner. As a result, DIVIDE could identify in-neighborhood negatives and out-of-neighborhood positives. Moreover, DIVIDE embraces a novel MvC architecture to perform inter- and intra-view contrastive learning in different embedding spaces, thus boosting clustering performance and embracing the robustness against missing views. To verify the efficacy of DIVIDE, we carry out extensive experiments on four benchmark datasets comparing with nine state-of-the-art MvC methods in both complete and incomplete MvC settings.
Graph Matching with Bi-level Noisy Correspondence
Dec 22, 2022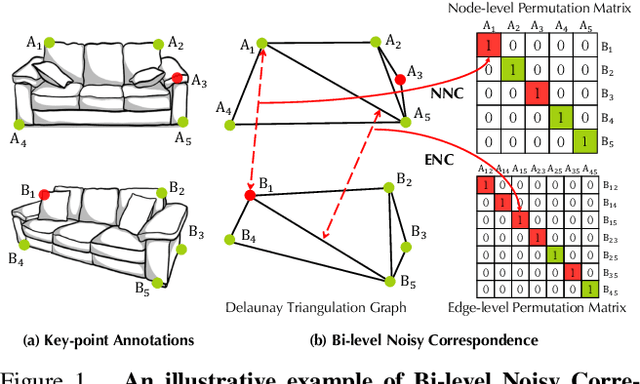
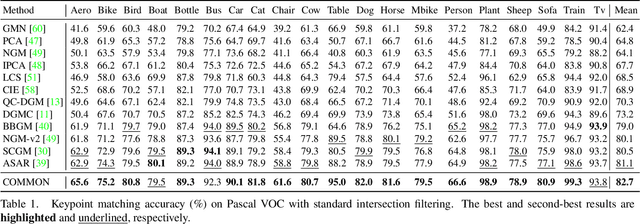
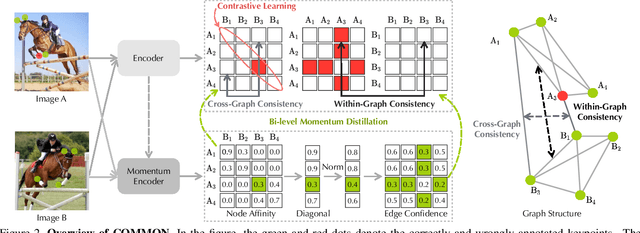
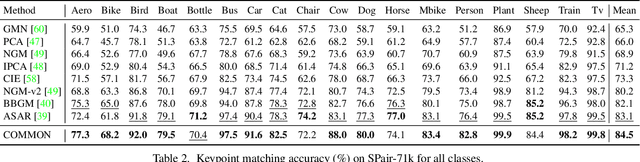
In this paper, we study a novel and widely existing problem in graph matching (GM), namely, Bi-level Noisy Correspondence (BNC), which refers to node-level noisy correspondence (NNC) and edge-level noisy correspondence (ENC). In brief, on the one hand, due to the poor recognizability and viewpoint differences between images, it is inevitable to inaccurately annotate some keypoints with offset and confusion, leading to the mismatch between two associated nodes, i.e., NNC. On the other hand, the noisy node-to-node correspondence will further contaminate the edge-to-edge correspondence, thus leading to ENC. For the BNC challenge, we propose a novel method termed Contrastive Matching with Momentum Distillation. Specifically, the proposed method is with a robust quadratic contrastive loss which enjoys the following merits: i) better exploring the node-to-node and edge-to-edge correlations through a GM customized quadratic contrastive learning paradigm; ii) adaptively penalizing the noisy assignments based on the confidence estimated by the momentum teacher. Extensive experiments on three real-world datasets show the robustness of our model compared with 12 competitive baselines.
Unsupervised Neural Rendering for Image Hazing
Jul 14, 2021


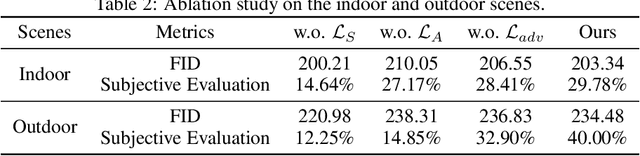
Image hazing aims to render a hazy image from a given clean one, which could be applied to a variety of practical applications such as gaming, filming, photographic filtering, and image dehazing. To generate plausible haze, we study two less-touched but challenging problems in hazy image rendering, namely, i) how to estimate the transmission map from a single image without auxiliary information, and ii) how to adaptively learn the airlight from exemplars, i.e., unpaired real hazy images. To this end, we propose a neural rendering method for image hazing, dubbed as HazeGEN. To be specific, HazeGEN is a knowledge-driven neural network which estimates the transmission map by leveraging a new prior, i.e., there exists the structure similarity (e.g., contour and luminance) between the transmission map and the input clean image. To adaptively learn the airlight, we build a neural module based on another new prior, i.e., the rendered hazy image and the exemplar are similar in the airlight distribution. To the best of our knowledge, this could be the first attempt to deeply rendering hazy images in an unsupervised fashion. Comparing with existing haze generation methods, HazeGEN renders the hazy images in an unsupervised, learnable, and controllable manner, thus avoiding the labor-intensive efforts in paired data collection and the domain-shift issue in haze generation. Extensive experiments show the promising performance of our method comparing with some baselines in both qualitative and quantitative comparisons. The code will be released on GitHub after acceptance.