 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliable Thinking with Images
Feb 16, 2026As a multimodal extension of Chain-of-Thought (CoT), Thinking with Images (TWI) has recently emerged as a promising avenue to enhance the reasoning capability of Multi-modal Large Language Models (MLLMs), which generates interleaved CoT by incorporating visual cues into the textual reasoning process. However, the success of existing TWI methods heavily relies on the assumption that interleaved image-text CoTs are faultless, which is easily violated in real-world scenarios due to the complexity of multimodal understanding. In this paper, we reveal and study a highly-practical yet under-explored problem in TWI, termed Noisy Thinking (NT). Specifically, NT refers to the imperfect visual cues mining and answer reasoning process. As the saying goes, ``One mistake leads to another'', erroneous interleaved CoT would cause error accumulation, thus significantly degrading the performance of MLLMs. To solve the NT problem, we propose a novel method dubbed Reliable Thinking with Images (RTWI). In brief, RTWI estimates the reliability of visual cues and textual CoT in a unified text-centric manner and accordingly employs robust filtering and voting modules to prevent NT from contaminating the final answer. Extensive experiments on seven benchmarks verify the effectiveness of RTWI against NT.
ARK: A Dual-Axis Multimodal Retrieval Benchmark along Reasoning and Knowledge
Feb 10, 2026Existing multimodal retrieval benchmarks largely emphasize semantic matching on daily-life images and offer limited diagnostics of professional knowledge and complex reasoning. To address this gap, we introduce ARK, a benchmark designed to analyze multimodal retrieval from two complementary perspectives: (i) knowledge domains (five domains with 17 subtypes), which characterize the content and expertise retrieval relies on, and (ii) reasoning skills (six categories), which characterize the type of inference over multimodal evidence required to identify the correct candidate. Specifically, ARK evaluates retrieval with both unimodal and multimodal queries and candidates, covering 16 heterogeneous visual data types. To avoid shortcut matching during evaluation, most queries are paired with targeted hard negatives that require multi-step reasoning. We evaluate 23 representative text-based and multimodal retrievers on ARK and observe a pronounced gap between knowledge-intensive and reasoning-intensive retrieval, with fine-grained visual and spatial reasoning emerging as persistent bottlenecks. We further show that simple enhancements such as re-ranking and rewriting yield consistent improvements, but substantial headroom remains.
Toward Robust and Harmonious Adaptation for Cross-modal Retrieval
Nov 18, 2025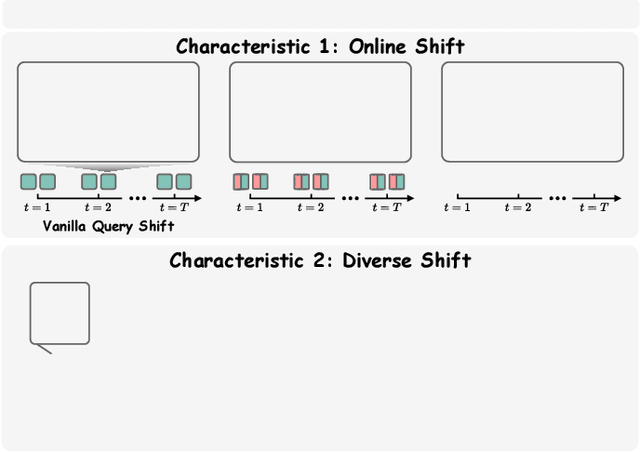
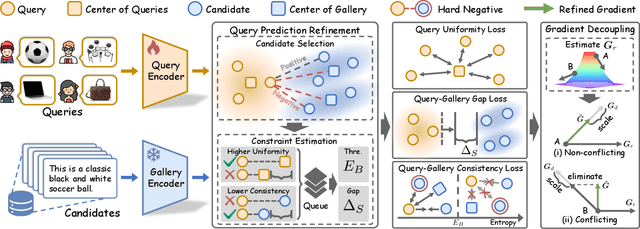

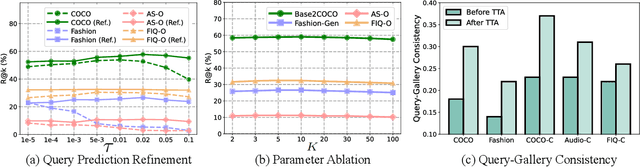
Recently, the general-to-customized paradigm has emerged as the dominant approach for Cross-Modal Retrieval (CMR), which reconciles the distribution shift problem between the source domain and the target domain. However, existing general-to-customized CMR methods typically assume that the entire target-domain data is available, which is easily violated in real-world scenarios and thus inevitably suffer from the query shift (QS) problem. Specifically, query shift embraces the following two characteristics and thus poses new challenges to CMR. i) Online Shift: real-world queries always arrive in an online manner, rendering it impractical to access the entire query set beforehand for customization approaches; ii) Diverse Shift: even with domain customization, the CMR models struggle to satisfy queries from diverse users or scenarios, leaving an urgent need to accommodate diverse queries. In this paper, we observe that QS would not only undermine the well-structured common space inherited from the source model, but also steer the model toward forgetting the indispensable general knowledge for CMR. Inspired by the observations, we propose a novel method for achieving online and harmonious adaptation against QS, dubbed Robust adaptation with quEry ShifT (REST). To deal with online shift, REST first refines the retrieval results to formulate the query predictions and accordingly designs a QS-robust objective function on these predictions to preserve the well-established common space in an online manner. As for tackling the more challenging diverse shift, REST employs a gradient decoupling module to dexterously manipulate the gradients during the adaptation process, thus preventing the CMR model from forgetting the general knowledge. Extensive experiments on 20 benchmarks across three CMR tasks verify the effectiveness of our method against QS.
Test-time Adaptation for Cross-modal Retrieval with Query Shift
Oct 21, 2024



The success of most existing cross-modal retrieval methods heavily relies on the assumption that the given queries follow the same distribution of the source domain. However, such an assumption is easily violated in real-world scenarios due to the complexity and diversity of queries, thus leading to the query shift problem. Specifically, query shift refers to the online query stream originating from the domain that follows a different distribution with the source one. In this paper, we observe that query shift would not only diminish the uniformity (namely, within-modality scatter) of the query modality but also amplify the gap between query and gallery modalities. Based on the observations, we propose a novel method dubbed Test-time adaptation for Cross-modal Retrieval (TCR). In brief, TCR employs a novel module to refine the query predictions (namely, retrieval results of the query) and a joint objective to prevent query shift from disturbing the common space, thus achieving online adaptation for the cross-modal retrieval models with query shift. Expensive experiments demonstrate the effectiveness of the proposed TCR against query shift. The code will be released upon acceptance.
A Survey on Deep Clustering: From the Prior Perspective
Jun 28, 2024Facilitated by the powerful feature extraction ability of neural networks, deep clustering has achieved great success in analyzing high-dimensional and complex real-world data. The performance of deep clustering methods is affected by various factors such as network structures and learning objectives. However, as pointed out in this survey, the essence of deep clustering lies in the incorporation and utilization of prior knowledge, which is largely ignored by existing works. From pioneering deep clustering methods based on data structure assumptions to recent contrastive clustering methods based on data augmentation invariances, the development of deep clustering intrinsically corresponds to the evolution of prior knowledge. In this survey, we provide a comprehensive review of deep clustering methods by categorizing them into six types of prior knowledge. We find that in general the prior innovation follows two trends, namely, i) from mining to constructing, and ii) from internal to external. Besides, we provide a benchmark on five widely-used datasets and analyze the performance of methods with diverse priors. By providing a novel prior knowledge perspective, we hope this survey could provide some novel insights and inspire future research in the deep clustering community.
Incomplete Multi-view Clustering via Prototype-based Imputation
Jan 30, 2023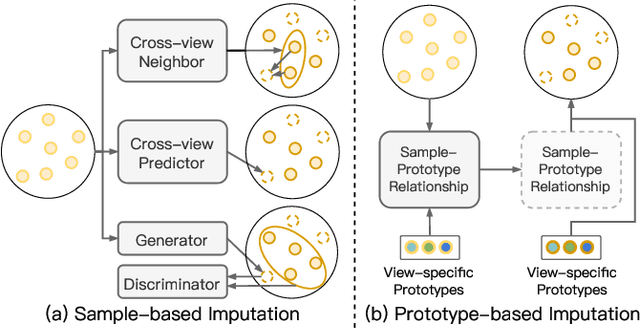
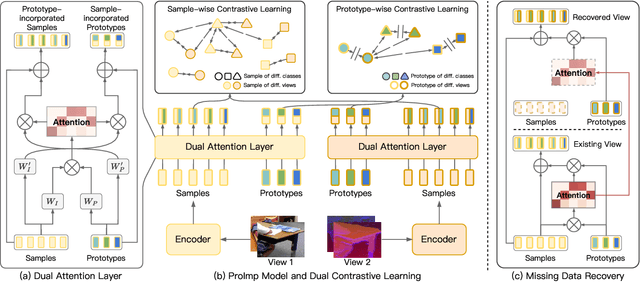
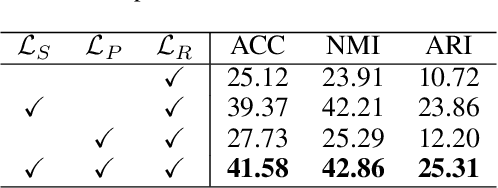
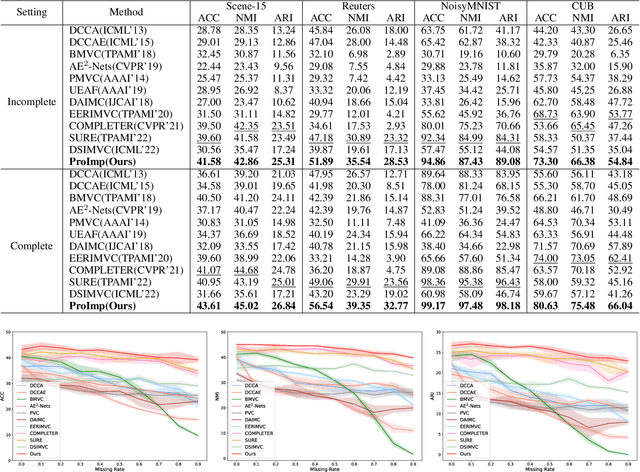
In this paper, we study how to achieve two characteristics highly-expected by incomplete multi-view clustering (IMvC). Namely, i) instance commonality refers to that within-cluster instances should share a common pattern, and ii) view versatility refers to that cross-view samples should own view-specific patterns. To this end, we design a novel dual-stream model which employs a dual attention layer and a dual contrastive learning loss to learn view-specific prototypes and model the sample-prototype relationship. When the view is missed, our model performs data recovery using the prototypes in the missing view and the sample-prototype relationship inherited from the observed view. Thanks to our dual-stream model, both cluster- and view-specific information could be captured, and thus the instance commonality and view versatility could be preserved to facilitate IMvC. Extensive experiments demonstrate the superiority of our method on six challenging benchmarks compared with 11 approaches. The code will be released.