 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Space Object Detection with Multi-Satellite Viewpoints in LEO Constellations
Jun 01, 2026With the growing number of satellites in low Earth orbit (LEO) constellations, the near-Earth space environment has become increasingly congested, making space object detection (SOD) a pressing challenge for space safety and sustainability. To mitigate collision risks and ensure the continuity of space operations, SOD systems must deliver fast and accurate detection under stringent onboard constraints. In this paper, we investigate the potential of multi-viewpoint observation fusion within a deep learning (DL) framework to enhance SOD performance. We design a practical multi-view pipeline and several input representations for feeding multi-view data into YOLO-based detectors. Our experiments show that using multi-view inputs is feasible in most cases and typically produces better results for mAP50 and mAP50-95. For example, in model YOLOv9-m, single-view compared to a three-view fused RGB setting, mAP50 increases from 0.638 to 0.732, while mAP50-95 improves from 0.227 to 0.276. Compared with the single-view setting, the best three-view grayscale configuration improves mAP50 by 36.3% and mAP50-95 by 46.5%. These findings establish multi-view fusion as a viable and effective strategy for SOD, with broad implications for space situational awareness in LEO constellation deployments.
MoRE: A Mixture-of-Experts-Based Task-Adaptive End-to-End Network for Multimodal MRI Reconstruction
Jun 01, 2026Although accelerated MRI reconstruction has advanced rapidly through end-to-end learning, deploying a single unified network that generalizes across diverse anatomies and contrasts under constrained computational resources remains challenging. In this paper, we introduce MoRE, a sparsely activated mixture-of-experts (MoE) module integrated into an end-to-end variational network. MoRE couples a shared encoder with sample-wise, unsupervised routing to activate a minimal subset of expert decoders while strictly preserving physics-based data consistency. Evaluated on the fastMRI multi-coil brain and knee datasets under 8x undersampling, MoRE achieves highly stable SSIM and PSNR performance across multi-contrast datasets. Furthermore, t-SNE visualization of the routing embeddings reveals interpretable, modality-aware expert specialization. The sparse conditional computation mechanism ensures that the architectural overhead remains modest. These results demonstrate that MoE-style capacity scaling can significantly enhance general-purpose MRI reconstruction without requiring proportional increases in computational power.
Robust Fuzzy Multi-view Learning under View Conflict
May 23, 2026Trusted multi-view classification aims to deliver reliable fusion for accurate predictions and has recently attracted substantial attention in both academia and industry. However, existing TMVC methods typically assume strict alignment across different views during both training and testing phases, which is often impractical in real-world scenarios. This limitation motivates us to revisit TMVC and extend it to a more challenging setting: how to mitigate the impact of view conflict (VC) during both training and inference. To tackle this setting, existing TMVC methods suffer from three critical limitations: underestimated uncertainty, misleading decisions, and overfitting to VC. To address these issues, this paper proposes a novel Robust Fuzzy Multi-View Learning (R-FUML) framework grounded in Fuzzy Set Theory. Specifically, R-FUML models network outputs as fuzzy memberships to quantify category credibility and uses an entropy-based method for reliable multi-view fusion. To this end, we present a Robust Multi-view Fusion (RMF) strategy that accounts for both view-specific uncertainty and inter-view conflicts, thereby alleviating the adverse impacts of VC on decision-making. To identify and conquer VC during training, we further design a Robust Learning Against VC (RLVC) framework. RLVC isolates conflicting samples by leveraging neural networks' memory effects and then retrains the model by applying a penalty to these conflicting views. Extensive experiments across eight public datasets demonstrate that R-FUML consistently outperforms 15 state-of-the-art baselines in robustness and uncertainty estimation. The code will be released upon acceptance.
Beyond Loss Values: Robust Dynamic Pruning via Loss Trajectory Alignment
Apr 08, 2026Existing dynamic data pruning methods often fail under noisy-label settings, as they typically rely on per-sample loss as the ranking criterion. This could mistakenly lead to preserving noisy samples due to their high loss values, resulting in significant performance drop. To address this, we propose AlignPrune, a noise-robust module designed to enhance the reliability of dynamic pruning under label noise. Specifically, AlignPrune introduces the Dynamic Alignment Score (DAS), which is a loss-trajectory-based criterion that enables more accurate identification of noisy samples, thereby improving pruning effectiveness. As a simple yet effective plug-and-play module, AlignPrune can be seamlessly integrated into state-of-the-art dynamic pruning frameworks, consistently outperforming them without modifying either the model architecture or the training pipeline. Extensive experiments on five widely-used benchmarks across various noise types and pruning ratios demonstrate the effectiveness of AlignPrune, boosting accuracy by up to 6.3\% over state-of-the-art baselines. Our results offer a generalizable solution for pruning under noisy data, encouraging further exploration of learning in real-world scenarios. Code is available at: https://github.com/leonqin430/AlignPrune.
Beyond Ground-Truth: Leveraging Image Quality Priors for Real-World Image Restoration
Mar 31, 2026Real-world image restoration aims to restore high-quality (HQ) images from degraded low-quality (LQ) inputs captured under uncontrolled conditions. Existing methods typically depend on ground-truth (GT) supervision, assuming that GT provides perfect reference quality. However, GT can still contain images with inconsistent perceptual fidelity, causing models to converge to the average quality level of the training data rather than achieving the highest perceptual quality attainable. To address these problems, we propose a novel framework, termed IQPIR, that introduces an Image Quality Prior (IQP)-extracted from pre-trained No-Reference Image Quality Assessment (NR-IQA) models-to guide the restoration process toward perceptually optimal outputs explicitly. Our approach synergistically integrates IQP with a learned codebook prior through three key mechanisms: (1) a quality-conditioned Transformer, where NR-IQA-derived scores serve as conditioning signals to steer the predicted representation toward maximal perceptual quality. This design provides a plug-and-play enhancement compatible with existing restoration architectures without structural modification; and (2) a dual-branch codebook structure, which disentangles common and HQ-specific features, ensuring a comprehensive representation of both generic structural information and quality-sensitive attributes; and (3) a discrete representation-based quality optimization strategy, which mitigates over-optimization effects commonly observed in continuous latent spaces. Extensive experiments on real-world image restoration demonstrate that our method not only surpasses cutting-edge methods but also serves as a generalizable quality-guided enhancement strategy for existing methods. The code is available.
Personalized Federated Learning via Gaussian Generative Modeling
Mar 12, 2026Federated learning has emerged as a paradigm to train models collaboratively on inherently distributed client data while safeguarding privacy. In this context, personalized federated learning tackles the challenge of data heterogeneity by equipping each client with a dedicated model. A prevalent strategy decouples the model into a shared feature extractor and a personalized classifier head, where the latter actively guides the representation learning. However, previous works have focused on classifier head-guided personalization, neglecting the potential personalized characteristics in the representation distribution. Building on this insight, we propose pFedGM, a method based on Gaussian generative modeling. The approach begins by training a Gaussian generator that models client heterogeneity via weighted re-sampling. A balance between global collaboration and personalization is then struck by employing a dual objective: a shared objective that maximizes inter-class distance across clients, and a local objective that minimizes intra-class distance within them. To achieve this, we decouple the conventional Gaussian classifier into a navigator for global optimization, and a statistic extractor for capturing distributional statistics. Inspired by the Kalman gain, the algorithm then employs a dual-scale fusion framework at global and local levels to equip each client with a personalized classifier head. In this framework, we model the global representation distribution as a prior and the client-specific data as the likelihood, enabling Bayesian inference for class probability estimation. The evaluation covers a comprehensive range of scenarios: heterogeneity in class counts, environmental corruption, and multiple benchmark datasets and configurations. pFedGM achieves superior or competitive performance compared to state-of-the-art methods.
QualiTeacher: Quality-Conditioned Pseudo-Labeling for Real-World Image Restoration
Mar 09, 2026Real-world image restoration (RWIR) is a highly challenging task due to the absence of clean ground-truth images. Many recent methods resort to pseudo-label (PL) supervision, often within a Mean-Teacher (MT) framework. However, these methods face a critical paradox: unconditionally trusting the often imperfect, low-quality PLs forces the student model to learn undesirable artifacts, while discarding them severely limits data diversity and impairs model generalization. In this paper, we propose QualiTeacher, a novel framework that transforms pseudo-label quality from a noisy liability into a conditional supervisory signal. Instead of filtering, QualiTeacher explicitly conditions the student model on the quality of the PLs, estimated by an ensemble of complementary non-reference image quality assessment (NR-IQA) models spanning low-level distortion and semantic-level assessment. This strategy teaches the student network to learn a quality-graded restoration manifold, enabling it to understand what constitutes different quality levels. Consequently, it can not only avoid mimicking artifacts from low-quality labels but also extrapolate to generate results of higher quality than the teacher itself. To ensure the robustness and accuracy of this quality-driven learning, we further enhance the process with a multi-augmentation scheme to diversify the PL quality spectrum, a score-based preference optimization strategy inspired by Direct Preference Optimization (DPO) to enforce a monotonically ordered quality separation, and a cropped consistency loss to prevent adversarial over-optimization (reward hacking) of the IQA models. Experiments on standard RWIR benchmarks demonstrate that QualiTeacher can serve as a plug-and-play strategy to improve the quality of the existing pseudo-labeling framework, establishing a new paradigm for learning from imperfect supervision. Code will be released.
Next-Scale Prediction: A Self-Supervised Approach for Real-World Image Denoising
Dec 24, 2025Self-supervised real-world image denoising remains a fundamental challenge, arising from the antagonistic trade-off between decorrelating spatially structured noise and preserving high-frequency details. Existing blind-spot network (BSN) methods rely on pixel-shuffle downsampling (PD) to decorrelate noise, but aggressive downsampling fragments fine structures, while milder downsampling fails to remove correlated noise. To address this, we introduce Next-Scale Prediction (NSP), a novel self-supervised paradigm that decouples noise decorrelation from detail preservation. NSP constructs cross-scale training pairs, where BSN takes low-resolution, fully decorrelated sub-images as input to predict high-resolution targets that retain fine details. As a by-product, NSP naturally supports super-resolution of noisy images without retraining or modification. Extensive experiments demonstrate that NSP achieves state-of-the-art self-supervised denoising performance on real-world benchmarks, significantly alleviating the long-standing conflict between noise decorrelation and detail preservation.
Branch Learning in MRI: More Data, More Models, More Training
Dec 23, 2025We investigated two complementary strategies for multicontrast cardiac MR reconstruction: physics-consistent data-space augmentation (DualSpaceCMR) and parameter-efficient capacity scaling via VQPrompt and Moero. DualSpaceCMR couples image-level transforms with kspace noise and motion simulations while preserving forwardmodel consistency. VQPrompt adds a lightweight bottleneck prompt; Moero embeds a sparse mixture of experts within a deep unrolled network with histogram-based routing. In the multivendor, multisite CMRxRecon25 benchmark, we evaluate fewshot and out-of-distribution generalization. On small datasets, k-space motion-plus-noise improves reconstruction; on the large benchmark it degrades performance, revealing sensitivity to augmentation ratio and schedule. VQPrompt produces modest and consistent gains with negligible memory overhead. Moero continues to improve after early plateaus and maintains baseline-like fewshot and out-of-distribution behavior despite mild overfitting, but sparse routing lowers PyTorch throughput and makes wall clock time the main bottleneck. These results motivate scale-aware augmentation and suggest prompt-based capacity scaling as a practical path, while efficiency improvements are crucial for sparse expert models.
Conditional Representation Learning for Customized Tasks
Oct 06, 2025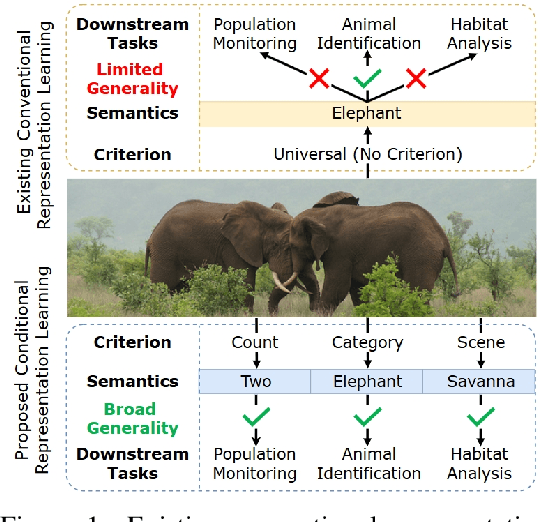

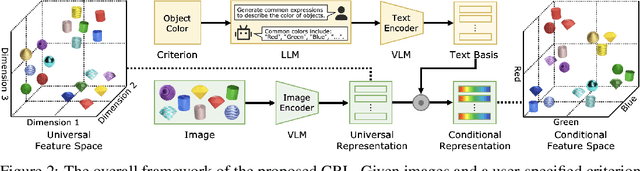
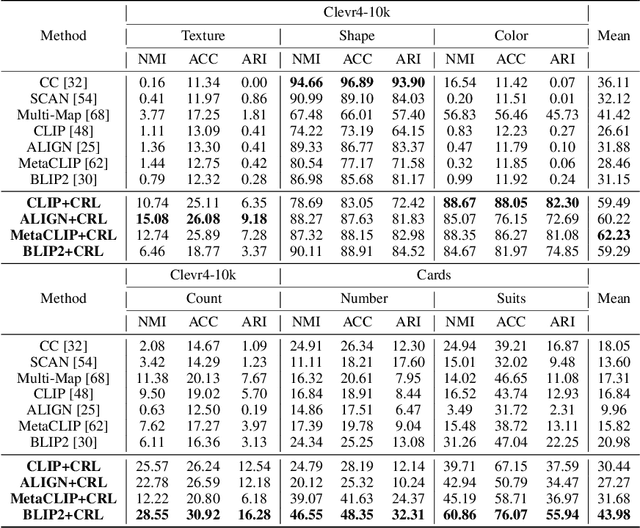
Conventional representation learning methods learn a universal representation that primarily captures dominant semantics, which may not always align with customized downstream tasks. For instance, in animal habitat analysis, researchers prioritize scene-related features, whereas universal embeddings emphasize categorical semantics, leading to suboptimal results. As a solution, existing approaches resort to supervised fine-tuning, which however incurs high computational and annotation costs. In this paper, we propose Conditional Representation Learning (CRL), aiming to extract representations tailored to arbitrary user-specified criteria. Specifically, we reveal that the semantics of a space are determined by its basis, thereby enabling a set of descriptive words to approximate the basis for a customized feature space. Building upon this insight, given a user-specified criterion, CRL first employs a large language model (LLM) to generate descriptive texts to construct the semantic basis, then projects the image representation into this conditional feature space leveraging a vision-language model (VLM). The conditional representation better captures semantics for the specific criterion, which could be utilized for multiple customized tasks. Extensive experiments on classification and retrieval tasks demonstrate the superiority and generality of the proposed CRL. The code is available at https://github.com/XLearning-SCU/2025-NeurIPS-CRL.