 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRotational ultrasound and photoacoustic tomography of the human body
Apr 22, 2025Imaging the human body's morphological and angiographic information is essential for diagnosing, monitoring, and treating medical conditions. Ultrasonography performs the morphological assessment of the soft tissue based on acoustic impedance variations, whereas photoacoustic tomography (PAT) can visualize blood vessels based on intrinsic hemoglobin absorption. Three-dimensional (3D) panoramic imaging of the vasculature is generally not practical in conventional ultrasonography with limited field-of-view (FOV) probes, and PAT does not provide sufficient scattering-based soft tissue morphological contrast. Complementing each other, fast panoramic rotational ultrasound tomography (RUST) and PAT are integrated for hybrid rotational ultrasound and photoacoustic tomography (RUS-PAT), which obtains 3D ultrasound structural and PAT angiographic images of the human body quasi-simultaneously. The RUST functionality is achieved in a cost-effective manner using a single-element ultrasonic transducer for ultrasound transmission and rotating arc-shaped arrays for 3D panoramic detection. RUST is superior to conventional ultrasonography, which either has a limited FOV with a linear array or is high-cost with a hemispherical array that requires both transmission and receiving. By switching the acoustic source to a light source, the system is conveniently converted to PAT mode to acquire angiographic images in the same region. Using RUS-PAT, we have successfully imaged the human head, breast, hand, and foot with a 10 cm diameter FOV, submillimeter isotropic resolution, and 10 s imaging time for each modality. The 3D RUS-PAT is a powerful tool for high-speed, 3D, dual-contrast imaging of the human body with potential for rapid clinical translation.
Document-Level Event Extraction with Definition-Driven ICL
Aug 10, 2024



In the field of Natural Language Processing (NLP), Large Language Models (LLMs) have shown great potential in document-level event extraction tasks, but existing methods face challenges in the design of prompts. To address this issue, we propose an optimization strategy called "Definition-driven Document-level Event Extraction (DDEE)." By adjusting the length of the prompt and enhancing the clarity of heuristics, we have significantly improved the event extraction performance of LLMs. We used data balancing techniques to solve the long-tail effect problem, enhancing the model's generalization ability for event types. At the same time, we refined the prompt to ensure it is both concise and comprehensive, adapting to the sensitivity of LLMs to the style of prompts. In addition, the introduction of structured heuristic methods and strict limiting conditions has improved the precision of event and argument role extraction. These strategies not only solve the prompt engineering problems of LLMs in document-level event extraction but also promote the development of event extraction technology, providing new research perspectives for other tasks in the NLP field.
Single-shot 3D photoacoustic computed tomography with a densely packed array for transcranial functional imaging
Jun 26, 2023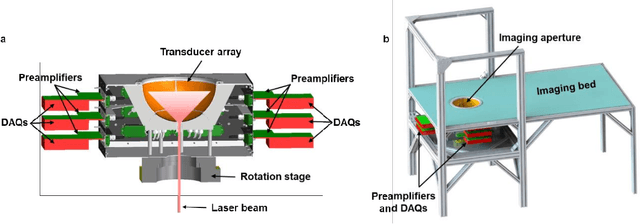
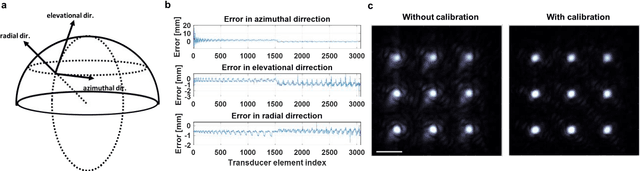

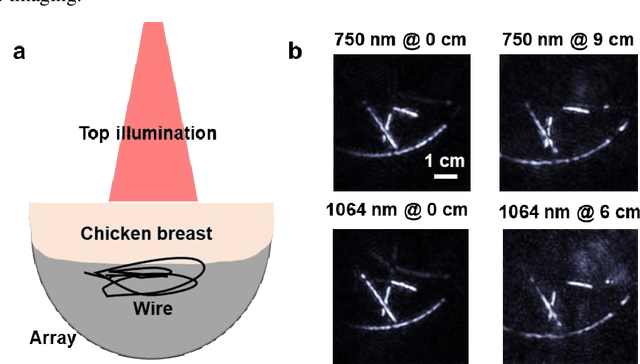
Photoacoustic computed tomography (PACT) is emerging as a new technique for functional brain imaging, primarily due to its capabilities in label-free hemodynamic imaging. Despite its potential, the transcranial application of PACT has encountered hurdles, such as acoustic attenuations and distortions by the skull and limited light penetration through the skull. To overcome these challenges, we have engineered a PACT system that features a densely packed hemispherical ultrasonic transducer array with 3072 channels, operating at a central frequency of 1 MHz. This system allows for single-shot 3D imaging at a rate equal to the laser repetition rate, such as 20 Hz. We have achieved a single-shot light penetration depth of approximately 9 cm in chicken breast tissue utilizing a 750 nm laser (withstanding 3295-fold light attenuation and still retaining an SNR of 74) and successfully performed transcranial imaging through an ex vivo human skull using a 1064 nm laser. Moreover, we have proven the capacity of our system to perform single-shot 3D PACT imaging in both tissue phantoms and human subjects. These results suggest that our PACT system is poised to unlock potential for real-time, in vivo transcranial functional imaging in humans.
Neural network-based image reconstruction in swept-source optical coherence tomography using undersampled spectral data
Mar 04, 2021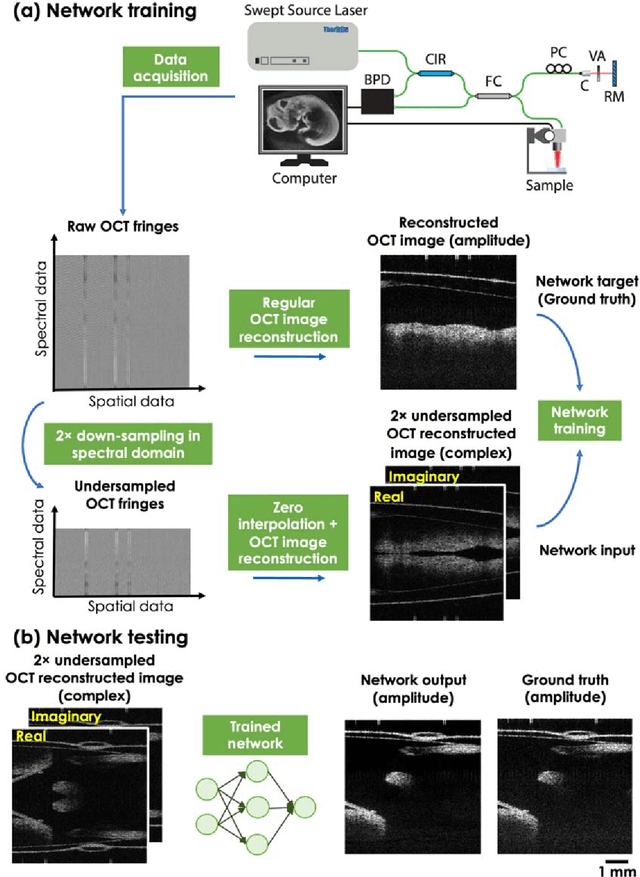
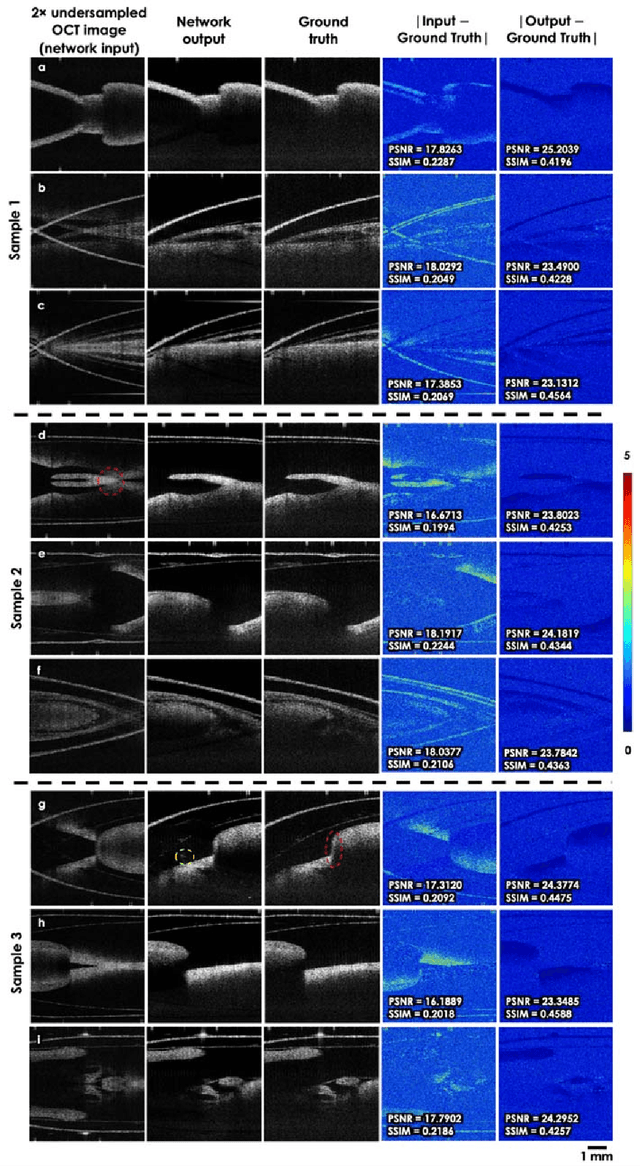
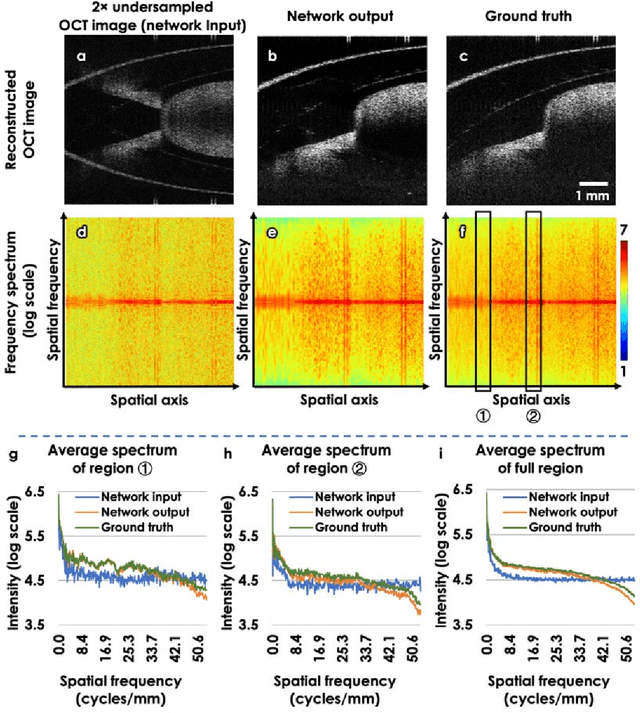
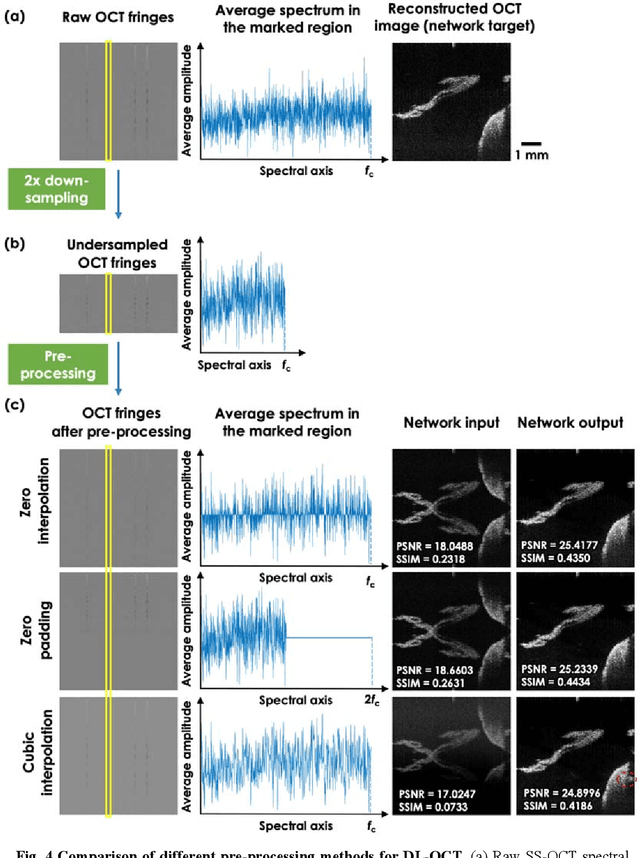
Optical Coherence Tomography (OCT) is a widely used non-invasive biomedical imaging modality that can rapidly provide volumetric images of samples. Here, we present a deep learning-based image reconstruction framework that can generate swept-source OCT (SS-OCT) images using undersampled spectral data, without any spatial aliasing artifacts. This neural network-based image reconstruction does not require any hardware changes to the optical set-up and can be easily integrated with existing swept-source or spectral domain OCT systems to reduce the amount of raw spectral data to be acquired. To show the efficacy of this framework, we trained and blindly tested a deep neural network using mouse embryo samples imaged by an SS-OCT system. Using 2-fold undersampled spectral data (i.e., 640 spectral points per A-line), the trained neural network can blindly reconstruct 512 A-lines in ~6.73 ms using a desktop computer, removing spatial aliasing artifacts due to spectral undersampling, also presenting a very good match to the images of the same samples, reconstructed using the full spectral OCT data (i.e., 1280 spectral points per A-line). We also successfully demonstrate that this framework can be further extended to process 3x undersampled spectral data per A-line, with some performance degradation in the reconstructed image quality compared to 2x spectral undersampling. This deep learning-enabled image reconstruction approach can be broadly used in various forms of spectral domain OCT systems, helping to increase their imaging speed without sacrificing image resolution and signal-to-noise ratio.
Deep learning-based virtual refocusing of images using an engineered point-spread function
Dec 22, 2020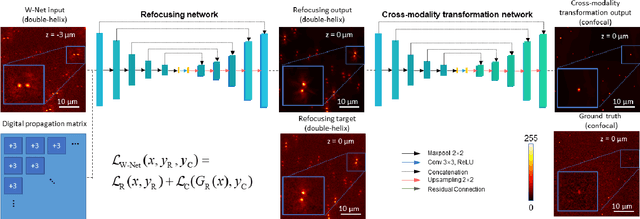

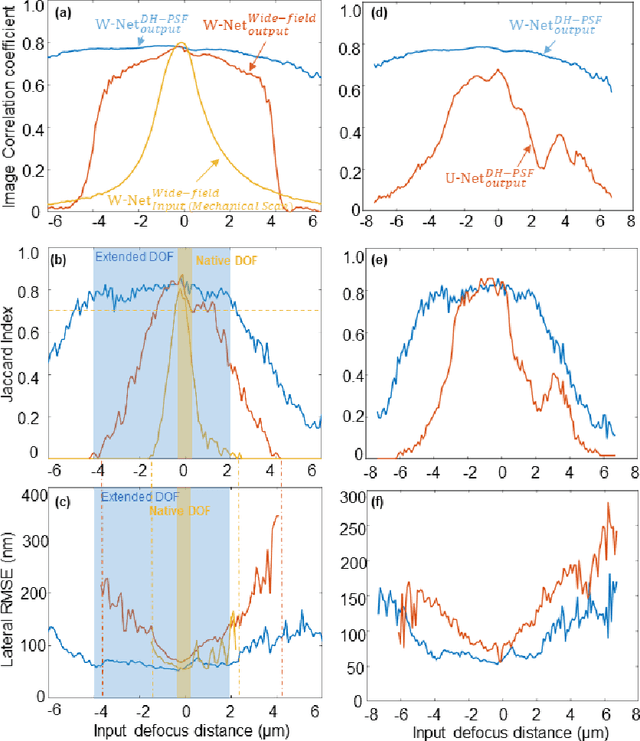
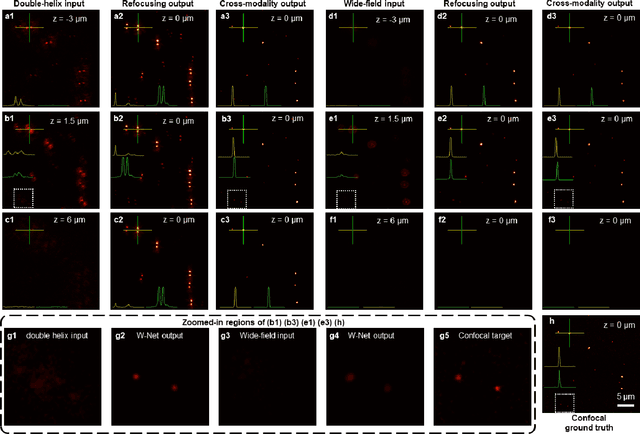
We present a virtual image refocusing method over an extended depth of field (DOF) enabled by cascaded neural networks and a double-helix point-spread function (DH-PSF). This network model, referred to as W-Net, is composed of two cascaded generator and discriminator network pairs. The first generator network learns to virtually refocus an input image onto a user-defined plane, while the second generator learns to perform a cross-modality image transformation, improving the lateral resolution of the output image. Using this W-Net model with DH-PSF engineering, we extend the DOF of a fluorescence microscope by ~20-fold. This approach can be applied to develop deep learning-enabled image reconstruction methods for localization microscopy techniques that utilize engineered PSFs to improve their imaging performance, including spatial resolution and volumetric imaging throughput.
Recurrent neural network-based volumetric fluorescence microscopy
Oct 21, 2020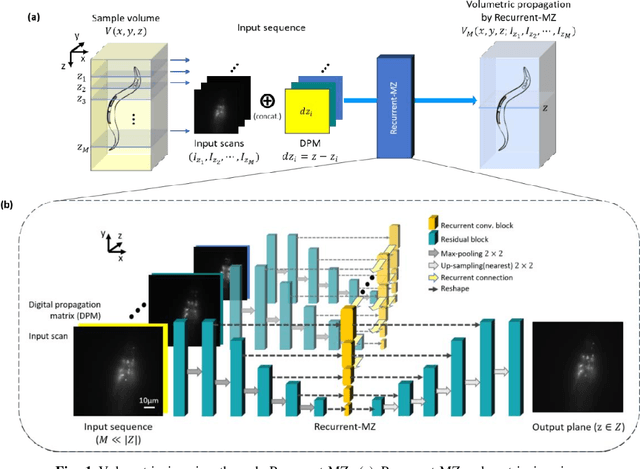
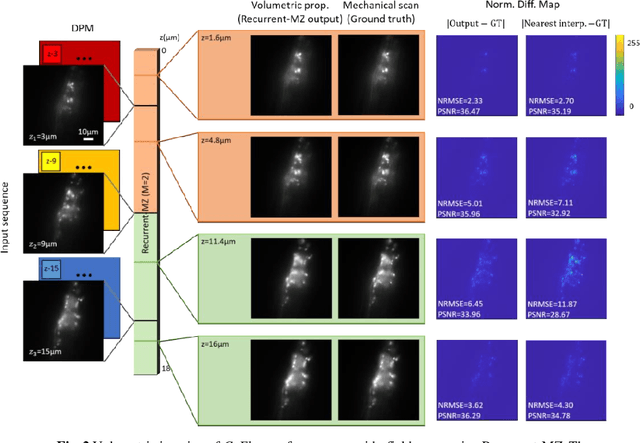
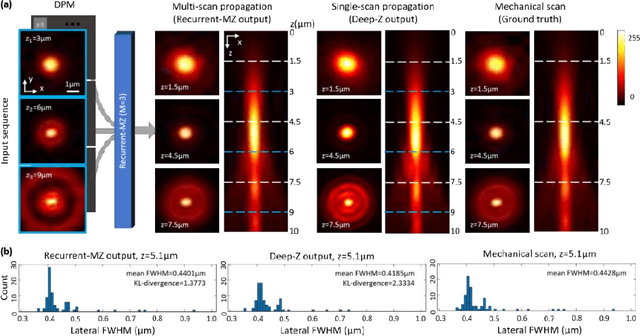
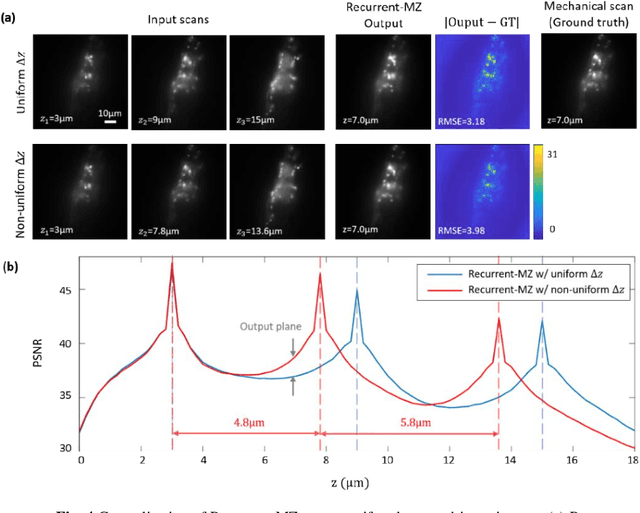
Volumetric imaging of samples using fluorescence microscopy plays an important role in various fields including physical, medical and life sciences. Here we report a deep learning-based volumetric image inference framework that uses 2D images that are sparsely captured by a standard wide-field fluorescence microscope at arbitrary axial positions within the sample volume. Through a recurrent convolutional neural network, which we term as Recurrent-MZ, 2D fluorescence information from a few axial planes within the sample is explicitly incorporated to digitally reconstruct the sample volume over an extended depth-of-field. Using experiments on C. Elegans and nanobead samples, Recurrent-MZ is demonstrated to increase the depth-of-field of a 63x/1.4NA objective lens by approximately 50-fold, also providing a 30-fold reduction in the number of axial scans required to image the same sample volume. We further illustrated the generalization of this recurrent network for 3D imaging by showing its resilience to varying imaging conditions, including e.g., different sequences of input images, covering various axial permutations and unknown axial positioning errors. Recurrent-MZ demonstrates the first application of recurrent neural networks in microscopic image reconstruction and provides a flexible and rapid volumetric imaging framework, overcoming the limitations of current 3D scanning microscopy tools.
Single-shot autofocusing of microscopy images using deep learning
Mar 21, 2020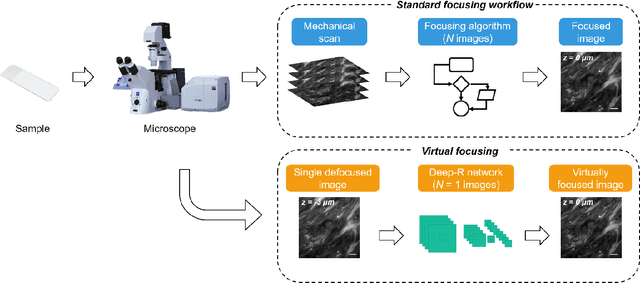
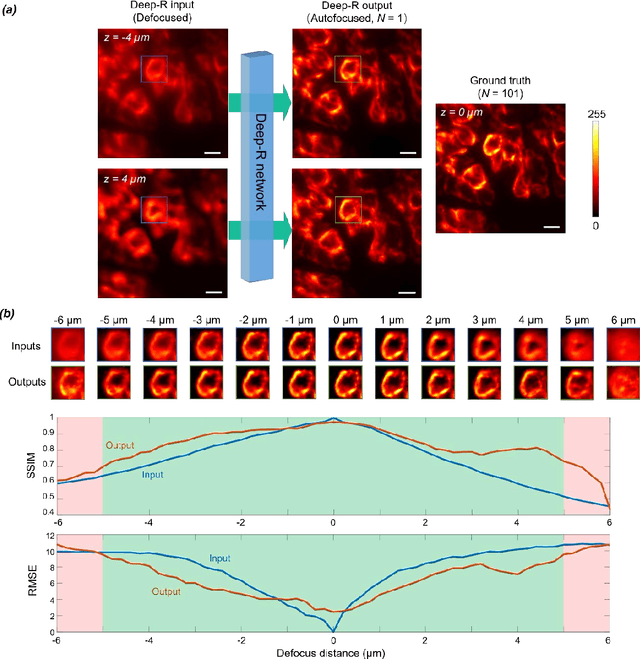
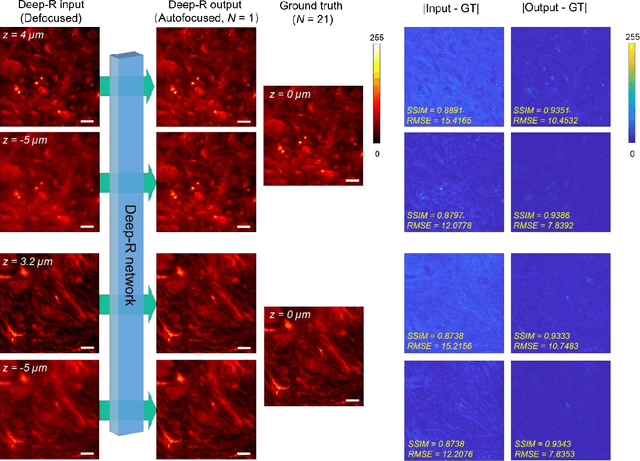
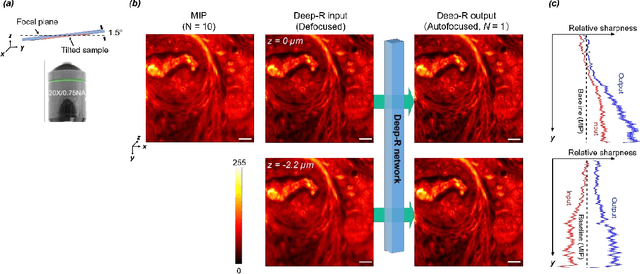
We demonstrate a deep learning-based offline autofocusing method, termed Deep-R, that is trained to rapidly and blindly autofocus a single-shot microscopy image of a specimen that is acquired at an arbitrary out-of-focus plane. We illustrate the efficacy of Deep-R using various tissue sections that were imaged using fluorescence and brightfield microscopy modalities and demonstrate snapshot autofocusing under different scenarios, such as a uniform axial defocus as well as a sample tilt within the field-of-view. Our results reveal that Deep-R is significantly faster when compared with standard online algorithmic autofocusing methods. This deep learning-based blind autofocusing framework opens up new opportunities for rapid microscopic imaging of large sample areas, also reducing the photon dose on the sample.
Three-dimensional propagation and time-reversal of fluorescence images
Jan 31, 2019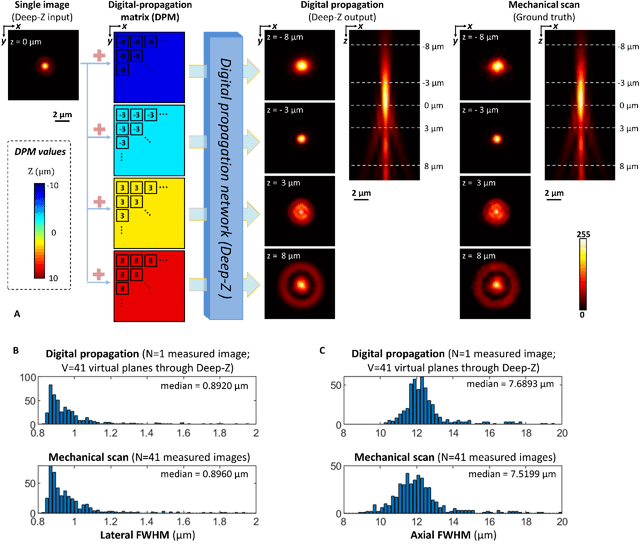
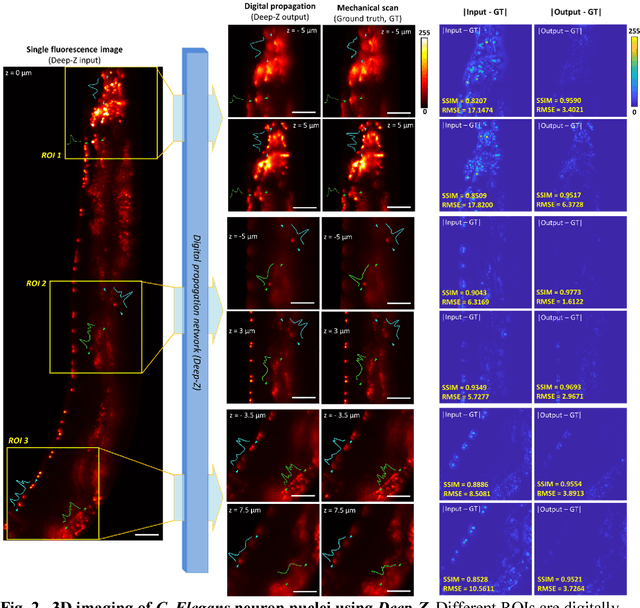
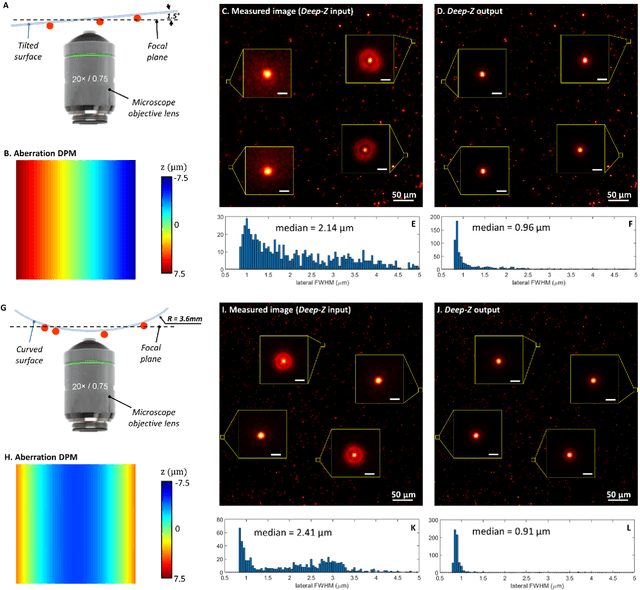
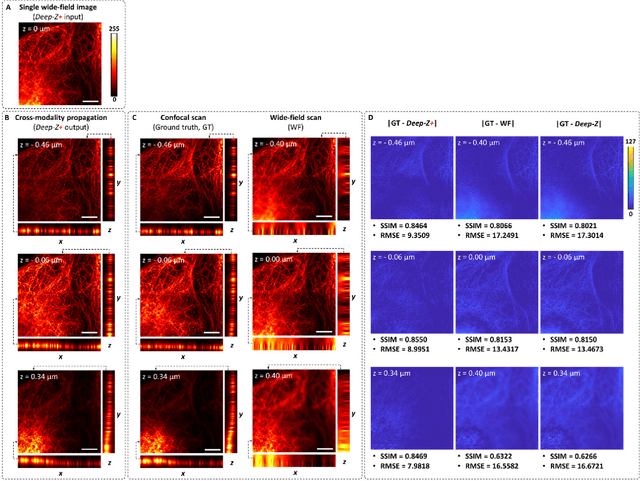
Unlike holography, fluorescence microscopy lacks an image propagation and time-reversal framework, which necessitates scanning of fluorescent objects to obtain 3D images. We demonstrate that a neural network can inherently learn the physical laws governing fluorescence wave propagation and time-reversal to enable 3D imaging of fluorescent samples using a single 2D image, without mechanical scanning, additional hardware, or a trade-off of resolution or speed. Using this data-driven framework, we increased the depth-of-field of a microscope by 20-fold, imaged Caenorhabditis elegans neurons in 3D using a single fluorescence image, and digitally propagated fluorescence images onto user-defined 3D surfaces, also correcting various aberrations. Furthermore, this learning-based approach cross-connects different imaging modalities, permitting 3D propagation of a wide-field fluorescence image to match confocal microscopy images acquired at different sample planes.
Cross-modality deep learning brings bright-field microscopy contrast to holography
Nov 17, 2018

Deep learning brings bright-field microscopy contrast to holographic images of a sample volume, bridging the volumetric imaging capability of holography with the speckle- and artifact-free image contrast of bright-field incoherent microscopy.