 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-shot 3D photoacoustic computed tomography with a densely packed array for transcranial functional imaging
Jun 26, 2023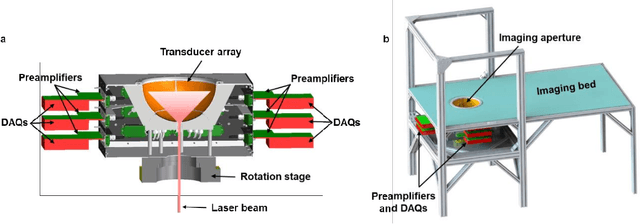
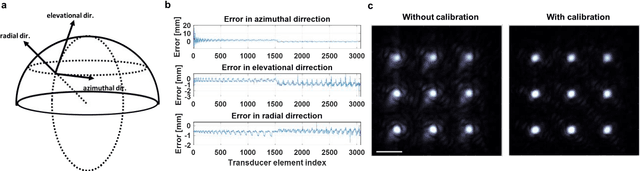

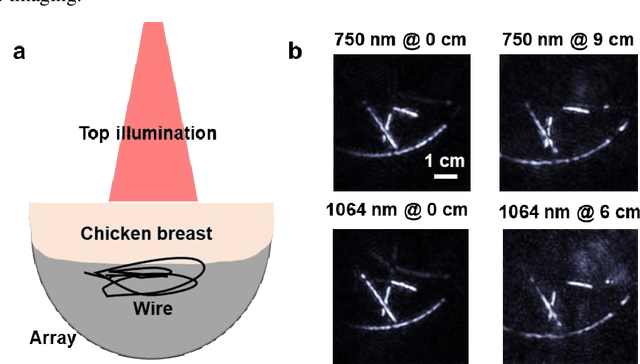
Photoacoustic computed tomography (PACT) is emerging as a new technique for functional brain imaging, primarily due to its capabilities in label-free hemodynamic imaging. Despite its potential, the transcranial application of PACT has encountered hurdles, such as acoustic attenuations and distortions by the skull and limited light penetration through the skull. To overcome these challenges, we have engineered a PACT system that features a densely packed hemispherical ultrasonic transducer array with 3072 channels, operating at a central frequency of 1 MHz. This system allows for single-shot 3D imaging at a rate equal to the laser repetition rate, such as 20 Hz. We have achieved a single-shot light penetration depth of approximately 9 cm in chicken breast tissue utilizing a 750 nm laser (withstanding 3295-fold light attenuation and still retaining an SNR of 74) and successfully performed transcranial imaging through an ex vivo human skull using a 1064 nm laser. Moreover, we have proven the capacity of our system to perform single-shot 3D PACT imaging in both tissue phantoms and human subjects. These results suggest that our PACT system is poised to unlock potential for real-time, in vivo transcranial functional imaging in humans.
Sequential Transformer for End-to-End Person Search
Nov 13, 2022



Person Search aims to simultaneously localize and recognize a target person from realistic and uncropped gallery images. One major challenge of person search comes from the contradictory goals of the two sub-tasks, i.e., person detection focuses on finding the commonness of all persons so as to distinguish persons from the background, while person re-identification (re-ID) focuses on the differences among different persons. In this paper, we propose a novel Sequential Transformer (SeqTR) for end-to-end person search to deal with this challenge. Our SeqTR contains a detection transformer and a novel re-ID transformer that sequentially addresses detection and re-ID tasks. The re-ID transformer comprises the self-attention layer that utilizes contextual information and the cross-attention layer that learns local fine-grained discriminative features of the human body. Moreover, the re-ID transformer is shared and supervised by multi-scale features to improve the robustness of learned person representations. Extensive experiments on two widely-used person search benchmarks, CUHK-SYSU and PRW, show that our proposed SeqTR not only outperforms all existing person search methods with a 59.3% mAP on PRW but also achieves comparable performance to the state-of-the-art results with an mAP of 94.8% on CUHK-SYSU.
LGT-Net: Indoor Panoramic Room Layout Estimation with Geometry-Aware Transformer Network
Mar 25, 2022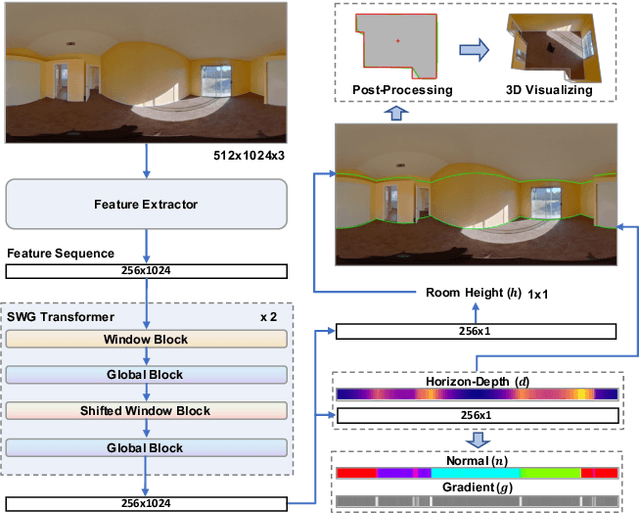
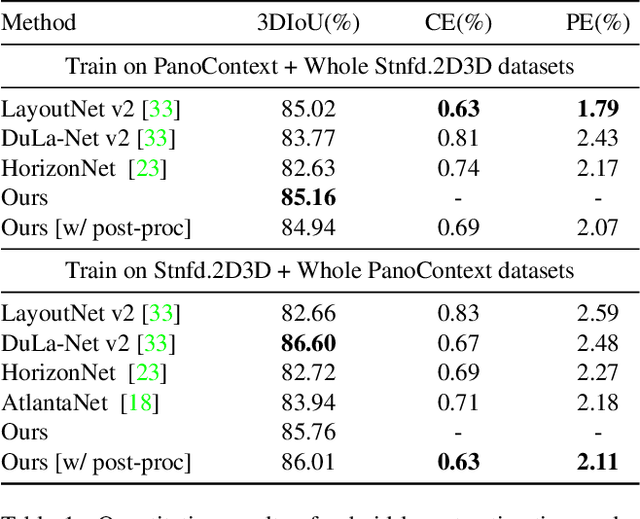
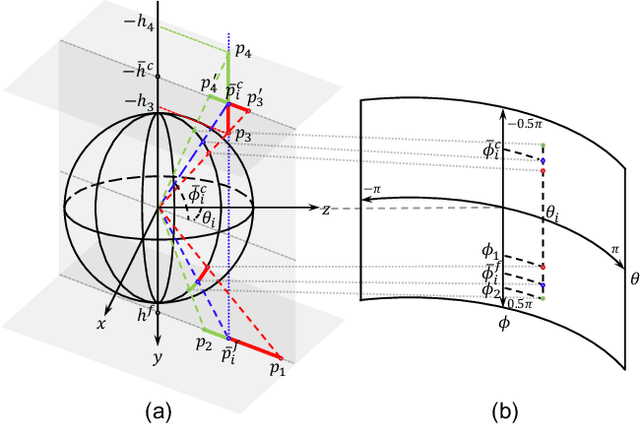
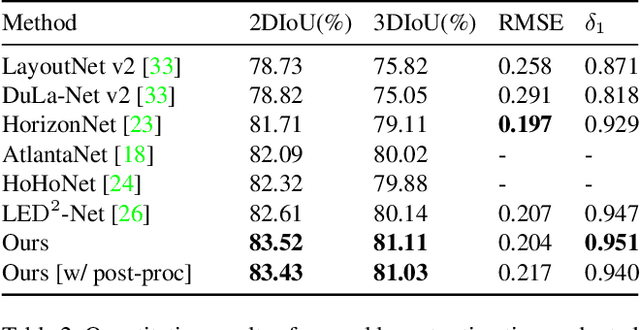
3D room layout estimation by a single panorama using deep neural networks has made great progress. However, previous approaches can not obtain efficient geometry awareness of room layout with the only latitude of boundaries or horizon-depth. We present that using horizon-depth along with room height can obtain omnidirectional-geometry awareness of room layout in both horizontal and vertical directions. In addition, we propose a planar-geometry aware loss function with normals and gradients of normals to supervise the planeness of walls and turning of corners. We propose an efficient network, LGT-Net, for room layout estimation, which contains a novel Transformer architecture called SWG-Transformer to model geometry relations. SWG-Transformer consists of (Shifted) Window Blocks and Global Blocks to combine the local and global geometry relations. Moreover, we design a novel relative position embedding of Transformer to enhance the spatial identification ability for the panorama. Experiments show that the proposed LGT-Net achieves better performance than current state-of-the-arts (SOTA) on benchmark datasets.