 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe FACTS Leaderboard: A Comprehensive Benchmark for Large Language Model Factuality
Dec 11, 2025We introduce The FACTS Leaderboard, an online leaderboard suite and associated set of benchmarks that comprehensively evaluates the ability of language models to generate factually accurate text across diverse scenarios. The suite provides a holistic measure of factuality by aggregating the performance of models on four distinct sub-leaderboards: (1) FACTS Multimodal, which measures the factuality of responses to image-based questions; (2) FACTS Parametric, which assesses models' world knowledge by answering closed-book factoid questions from internal parameters; (3) FACTS Search, which evaluates factuality in information-seeking scenarios, where the model must use a search API; and (4) FACTS Grounding (v2), which evaluates whether long-form responses are grounded in provided documents, featuring significantly improved judge models. Each sub-leaderboard employs automated judge models to score model responses, and the final suite score is an average of the four components, designed to provide a robust and balanced assessment of a model's overall factuality. The FACTS Leaderboard Suite will be actively maintained, containing both public and private splits to allow for external participation while guarding its integrity. It can be found at https://www.kaggle.com/benchmarks/google/facts .
CoverBench: A Challenging Benchmark for Complex Claim Verification
Aug 06, 2024
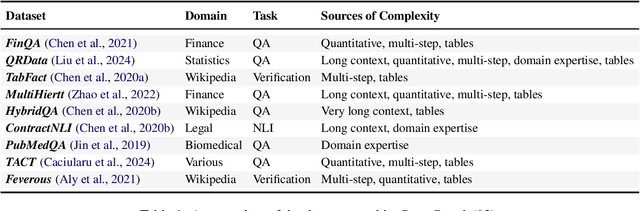
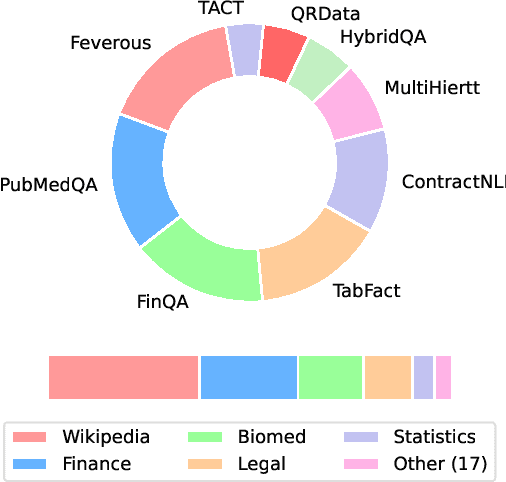
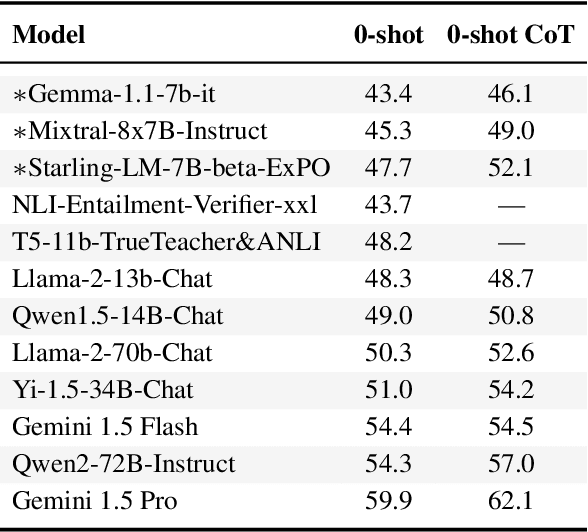
There is a growing line of research on verifying the correctness of language models' outputs. At the same time, LMs are being used to tackle complex queries that require reasoning. We introduce CoverBench, a challenging benchmark focused on verifying LM outputs in complex reasoning settings. Datasets that can be used for this purpose are often designed for other complex reasoning tasks (e.g., QA) targeting specific use-cases (e.g., financial tables), requiring transformations, negative sampling and selection of hard examples to collect such a benchmark. CoverBench provides a diversified evaluation for complex claim verification in a variety of domains, types of reasoning, relatively long inputs, and a variety of standardizations, such as multiple representations for tables where available, and a consistent schema. We manually vet the data for quality to ensure low levels of label noise. Finally, we report a variety of competitive baseline results to show CoverBench is challenging and has very significant headroom. The data is available at https://huggingface.co/datasets/google/coverbench .
TACT: Advancing Complex Aggregative Reasoning with Information Extraction Tools
Jun 05, 2024



Large Language Models (LLMs) often do not perform well on queries that require the aggregation of information across texts. To better evaluate this setting and facilitate modeling efforts, we introduce TACT - Text And Calculations through Tables, a dataset crafted to evaluate LLMs' reasoning and computational abilities using complex instructions. TACT contains challenging instructions that demand stitching information scattered across one or more texts, and performing complex integration on this information to generate the answer. We construct this dataset by leveraging an existing dataset of texts and their associated tables. For each such tables, we formulate new queries, and gather their respective answers. We demonstrate that all contemporary LLMs perform poorly on this dataset, achieving an accuracy below 38\%. To pinpoint the difficulties and thoroughly dissect the problem, we analyze model performance across three components: table-generation, Pandas command-generation, and execution. Unexpectedly, we discover that each component presents substantial challenges for current LLMs. These insights lead us to propose a focused modeling framework, which we refer to as IE as a tool. Specifically, we propose to add "tools" for each of the above steps, and implement each such tool with few-shot prompting. This approach shows an improvement over existing prompting techniques, offering a promising direction for enhancing model capabilities in these tasks.
Navigating Cultural Chasms: Exploring and Unlocking the Cultural POV of Text-To-Image Models
Oct 03, 2023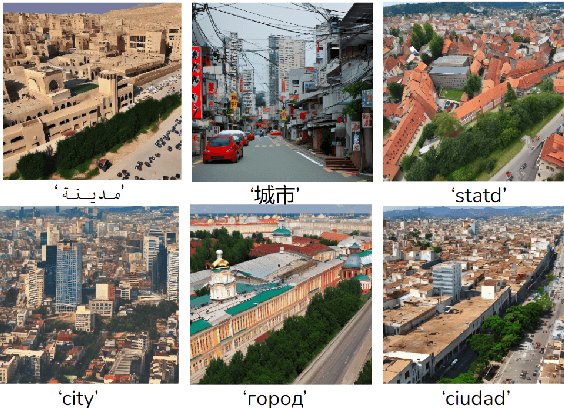


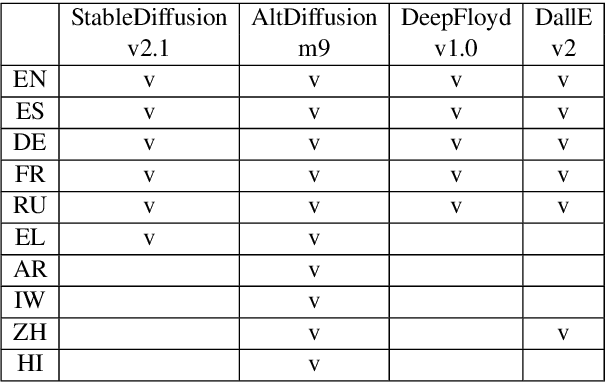
Text-To-Image (TTI) models, exemplified by DALL-E and StableDiffusion, have recently gained prominence for their remarkable zero-shot capabilities in generating images guided by textual prompts. Language, as a conduit of culture, plays a pivotal role in these models' multilingual capabilities, which in turn shape their cultural agency. In this study, we explore the cultural perception embedded in TTI models by characterizing culture across three hierarchical tiers: cultural dimensions, cultural domains, and cultural concepts. We propose a comprehensive suite of evaluation techniques, including intrinsic evaluations using the CLIP space, extrinsic evaluations with a Visual-Question-Answer (VQA) model, and human assessments, to discern TTI cultural perceptions. To facilitate our research, we introduce the CulText2I dataset, derived from four diverse TTI models and spanning ten languages. Our experiments reveal insights into these models' cultural awareness, cultural distinctions, and the unlocking of cultural features, releasing the potential for cross-cultural applications.
Measuring the Robustness of Natural Language Processing Models to Domain Shifts
May 31, 2023



Large Language Models have shown promising performance on various tasks, including fine-tuning, few-shot learning, and zero-shot learning. However, their performance on domains without labeled data still lags behind those with labeled data, which we refer as the Domain Robustness (DR) challenge. Existing research on DR suffers from disparate setups, lack of evaluation task variety, and reliance on challenge sets. In this paper, we explore the DR challenge of both fine-tuned and few-shot learning models in natural domain shift settings. We introduce a DR benchmark comprising diverse NLP tasks, including sentence and token-level classification, QA, and generation, each task consists of several domains. We propose two views of the DR challenge: Source Drop (SD) and Target Drop (TD), which alternate between the source and target in-domain performance as reference points. We find that in significant proportions of domain shifts, either SD or TD is positive, but not both, emphasizing the importance of considering both measures as diagnostic tools. Our experimental results demonstrate the persistent existence of the DR challenge in both fine-tuning and few-shot learning models, though it is less pronounced in the latter. We also find that increasing the fine-tuned model size improves performance, particularly in classification.
Text2Model: Model Induction for Zero-shot Generalization Using Task Descriptions
Oct 27, 2022



We study the problem of generating a training-free task-dependent visual classifier from text descriptions without visual samples. This \textit{Text-to-Model} (T2M) problem is closely related to zero-shot learning, but unlike previous work, a T2M model infers a model tailored to a task, taking into account all classes in the task. We analyze the symmetries of T2M, and characterize the equivariance and invariance properties of corresponding models. In light of these properties, we design an architecture based on hypernetworks that given a set of new class descriptions predicts the weights for an object recognition model which classifies images from those zero-shot classes. We demonstrate the benefits of our approach compared to zero-shot learning from text descriptions in image and point-cloud classification using various types of text descriptions: From single words to rich text descriptions.
Domain Adaptation from Scratch
Sep 02, 2022
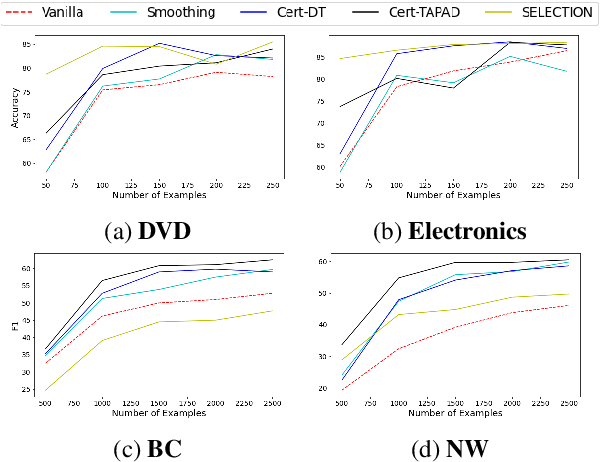
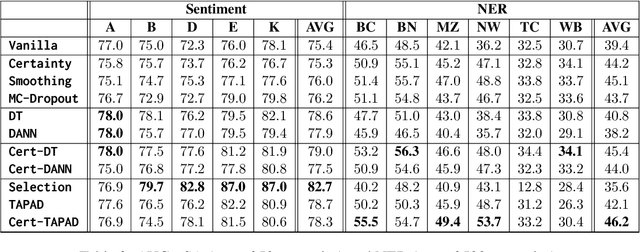

Natural language processing (NLP) algorithms are rapidly improving but often struggle when applied to out-of-distribution examples. A prominent approach to mitigate the domain gap is domain adaptation, where a model trained on a source domain is adapted to a new target domain. We present a new learning setup, ``domain adaptation from scratch'', which we believe to be crucial for extending the reach of NLP to sensitive domains in a privacy-preserving manner. In this setup, we aim to efficiently annotate data from a set of source domains such that the trained model performs well on a sensitive target domain from which data is unavailable for annotation. Our study compares several approaches for this challenging setup, ranging from data selection and domain adaptation algorithms to active learning paradigms, on two NLP tasks: sentiment analysis and Named Entity Recognition. Our results suggest that using the abovementioned approaches eases the domain gap, and combining them further improves the results.
IDANI: Inference-time Domain Adaptation via Neuron-level Interventions
Jun 01, 2022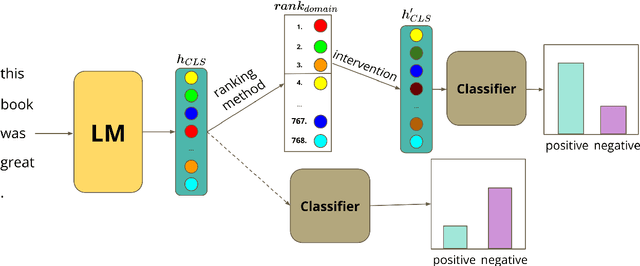

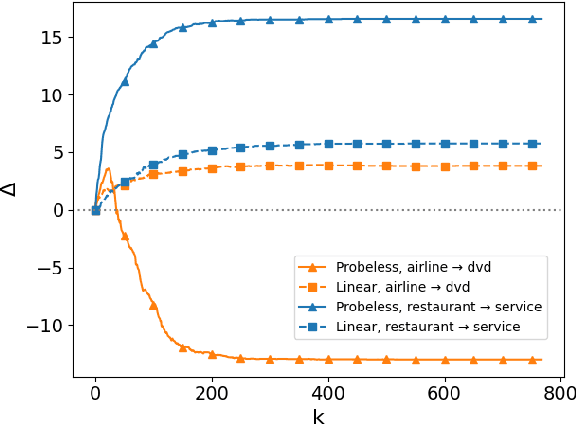

Large pre-trained models are usually fine-tuned on downstream task data, and tested on unseen data. When the train and test data come from different domains, the model is likely to struggle, as it is not adapted to the test domain. We propose a new approach for domain adaptation (DA), using neuron-level interventions: We modify the representation of each test example in specific neurons, resulting in a counterfactual example from the source domain, which the model is more familiar with. The modified example is then fed back into the model. While most other DA methods are applied during training time, ours is applied during inference only, making it more efficient and applicable. Our experiments show that our method improves performance on unseen domains.
Example-based Hypernetworks for Out-of-Distribution Generalization
Apr 02, 2022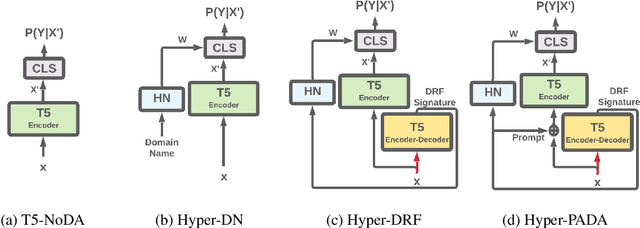



While Natural Language Processing (NLP) algorithms keep reaching unprecedented milestones, out-of-distribution generalization is still challenging. In this paper we address the problem of multi-source adaptation to unknown domains: Given labeled data from multiple source domains, we aim to generalize to data drawn from target domains that are unknown to the algorithm at training time. We present an algorithmic framework based on example-based Hypernetwork adaptation: Given an input example, a T5 encoder-decoder first generates a unique signature which embeds this example in the semantic space of the source domains, and this signature is then fed into a Hypernetwork which generates the weights of the task classifier. In an advanced version of our model, the learned signature also serves for improving the representation of the input example. In experiments with two tasks, sentiment classification and natural language inference, across 29 adaptation settings, our algorithms substantially outperform existing algorithms for this adaptation setup. To the best of our knowledge, this is the first time Hypernetworks are applied to domain adaptation or in example-based manner in NLP.
DoCoGen: Domain Counterfactual Generation for Low Resource Domain Adaptation
Mar 05, 2022
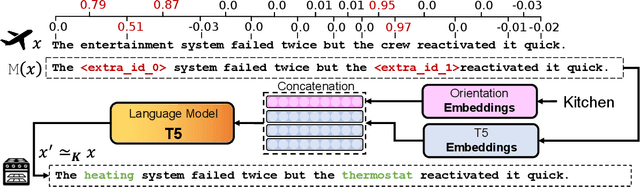
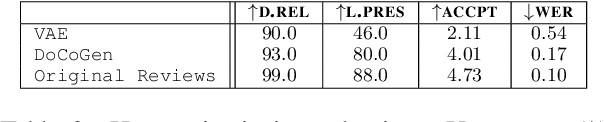
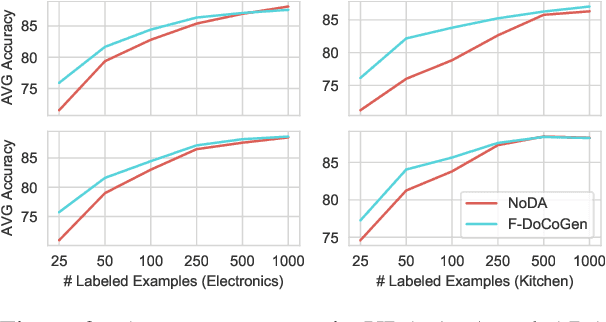
Natural language processing (NLP) algorithms have become very successful, but they still struggle when applied to out-of-distribution examples. In this paper we propose a controllable generation approach in order to deal with this domain adaptation (DA) challenge. Given an input text example, our DoCoGen algorithm generates a domain-counterfactual textual example (D-con) - that is similar to the original in all aspects, including the task label, but its domain is changed to a desired one. Importantly, DoCoGen is trained using only unlabeled examples from multiple domains - no NLP task labels or parallel pairs of textual examples and their domain-counterfactuals are required. We show that DoCoGen can generate coherent counterfactuals consisting of multiple sentences. We use the D-cons generated by DoCoGen to augment a sentiment classifier and a multi-label intent classifier in 20 and 78 DA setups, respectively, where source-domain labeled data is scarce. Our model outperforms strong baselines and improves the accuracy of a state-of-the-art unsupervised DA algorithm.