 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigating Cultural Chasms: Exploring and Unlocking the Cultural POV of Text-To-Image Models
Paper and Code
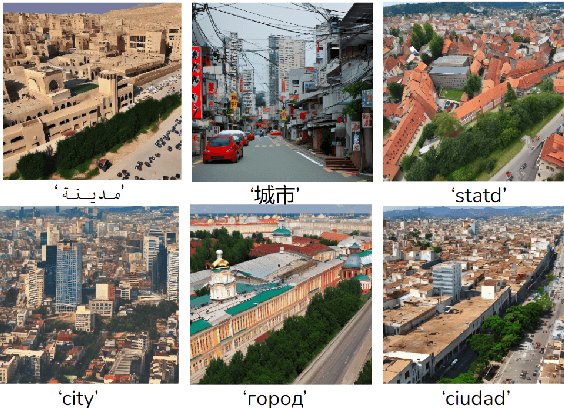


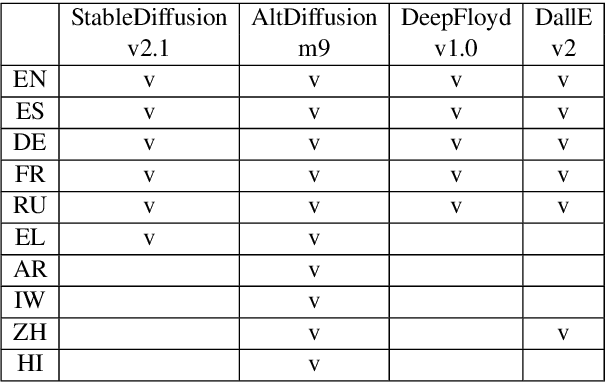
Text-To-Image (TTI) models, exemplified by DALL-E and StableDiffusion, have recently gained prominence for their remarkable zero-shot capabilities in generating images guided by textual prompts. Language, as a conduit of culture, plays a pivotal role in these models' multilingual capabilities, which in turn shape their cultural agency. In this study, we explore the cultural perception embedded in TTI models by characterizing culture across three hierarchical tiers: cultural dimensions, cultural domains, and cultural concepts. We propose a comprehensive suite of evaluation techniques, including intrinsic evaluations using the CLIP space, extrinsic evaluations with a Visual-Question-Answer (VQA) model, and human assessments, to discern TTI cultural perceptions. To facilitate our research, we introduce the CulText2I dataset, derived from four diverse TTI models and spanning ten languages. Our experiments reveal insights into these models' cultural awareness, cultural distinctions, and the unlocking of cultural features, releasing the potential for cross-cultural applications.