 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe FACTS Leaderboard: A Comprehensive Benchmark for Large Language Model Factuality
Dec 11, 2025We introduce The FACTS Leaderboard, an online leaderboard suite and associated set of benchmarks that comprehensively evaluates the ability of language models to generate factually accurate text across diverse scenarios. The suite provides a holistic measure of factuality by aggregating the performance of models on four distinct sub-leaderboards: (1) FACTS Multimodal, which measures the factuality of responses to image-based questions; (2) FACTS Parametric, which assesses models' world knowledge by answering closed-book factoid questions from internal parameters; (3) FACTS Search, which evaluates factuality in information-seeking scenarios, where the model must use a search API; and (4) FACTS Grounding (v2), which evaluates whether long-form responses are grounded in provided documents, featuring significantly improved judge models. Each sub-leaderboard employs automated judge models to score model responses, and the final suite score is an average of the four components, designed to provide a robust and balanced assessment of a model's overall factuality. The FACTS Leaderboard Suite will be actively maintained, containing both public and private splits to allow for external participation while guarding its integrity. It can be found at https://www.kaggle.com/benchmarks/google/facts .
DRAGged into Conflicts: Detecting and Addressing Conflicting Sources in Search-Augmented LLMs
Jun 10, 2025Retrieval Augmented Generation (RAG) is a commonly used approach for enhancing large language models (LLMs) with relevant and up-to-date information. However, the retrieved sources can often contain conflicting information and it remains unclear how models should address such discrepancies. In this work, we first propose a novel taxonomy of knowledge conflict types in RAG, along with the desired model behavior for each type. We then introduce CONFLICTS, a high-quality benchmark with expert annotations of conflict types in a realistic RAG setting. CONFLICTS is the first benchmark that enables tracking progress on how models address a wide range of knowledge conflicts. We conduct extensive experiments on this benchmark, showing that LLMs often struggle to appropriately resolve conflicts between sources. While prompting LLMs to explicitly reason about the potential conflict in the retrieved documents significantly improves the quality and appropriateness of their responses, substantial room for improvement in future research remains.
ConSim: Measuring Concept-Based Explanations' Effectiveness with Automated Simulatability
Jan 13, 2025



Concept-based explanations work by mapping complex model computations to human-understandable concepts. Evaluating such explanations is very difficult, as it includes not only the quality of the induced space of possible concepts but also how effectively the chosen concepts are communicated to users. Existing evaluation metrics often focus solely on the former, neglecting the latter. We introduce an evaluation framework for measuring concept explanations via automated simulatability: a simulator's ability to predict the explained model's outputs based on the provided explanations. This approach accounts for both the concept space and its interpretation in an end-to-end evaluation. Human studies for simulatability are notoriously difficult to enact, particularly at the scale of a wide, comprehensive empirical evaluation (which is the subject of this work). We propose using large language models (LLMs) as simulators to approximate the evaluation and report various analyses to make such approximations reliable. Our method allows for scalable and consistent evaluation across various models and datasets. We report a comprehensive empirical evaluation using this framework and show that LLMs provide consistent rankings of explanation methods. Code available at https://github.com/AnonymousConSim/ConSim.
The FACTS Grounding Leaderboard: Benchmarking LLMs' Ability to Ground Responses to Long-Form Input
Jan 06, 2025



We introduce FACTS Grounding, an online leaderboard and associated benchmark that evaluates language models' ability to generate text that is factually accurate with respect to given context in the user prompt. In our benchmark, each prompt includes a user request and a full document, with a maximum length of 32k tokens, requiring long-form responses. The long-form responses are required to be fully grounded in the provided context document while fulfilling the user request. Models are evaluated using automated judge models in two phases: (1) responses are disqualified if they do not fulfill the user request; (2) they are judged as accurate if the response is fully grounded in the provided document. The automated judge models were comprehensively evaluated against a held-out test-set to pick the best prompt template, and the final factuality score is an aggregate of multiple judge models to mitigate evaluation bias. The FACTS Grounding leaderboard will be actively maintained over time, and contains both public and private splits to allow for external participation while guarding the integrity of the leaderboard. It can be found at https://www.kaggle.com/facts-leaderboard.
CoverBench: A Challenging Benchmark for Complex Claim Verification
Aug 06, 2024
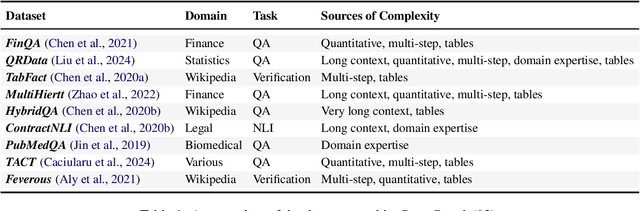
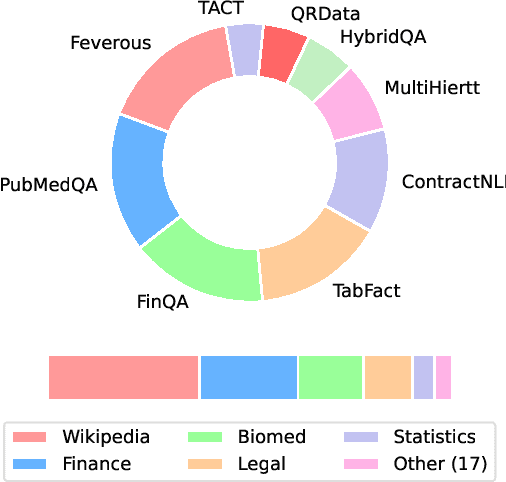
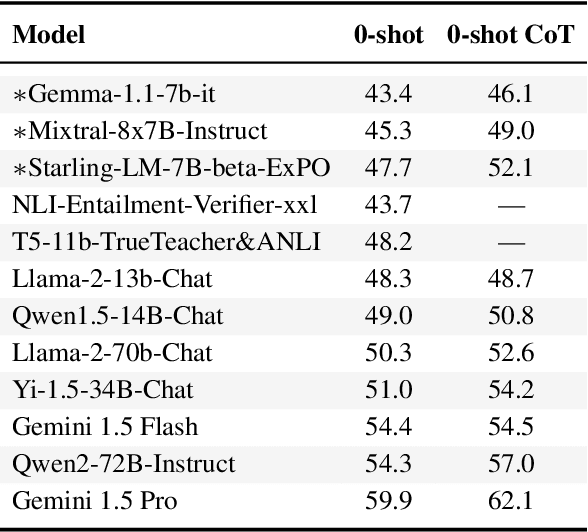
There is a growing line of research on verifying the correctness of language models' outputs. At the same time, LMs are being used to tackle complex queries that require reasoning. We introduce CoverBench, a challenging benchmark focused on verifying LM outputs in complex reasoning settings. Datasets that can be used for this purpose are often designed for other complex reasoning tasks (e.g., QA) targeting specific use-cases (e.g., financial tables), requiring transformations, negative sampling and selection of hard examples to collect such a benchmark. CoverBench provides a diversified evaluation for complex claim verification in a variety of domains, types of reasoning, relatively long inputs, and a variety of standardizations, such as multiple representations for tables where available, and a consistent schema. We manually vet the data for quality to ensure low levels of label noise. Finally, we report a variety of competitive baseline results to show CoverBench is challenging and has very significant headroom. The data is available at https://huggingface.co/datasets/google/coverbench .
Data Contamination Report from the 2024 CONDA Shared Task
Jul 31, 2024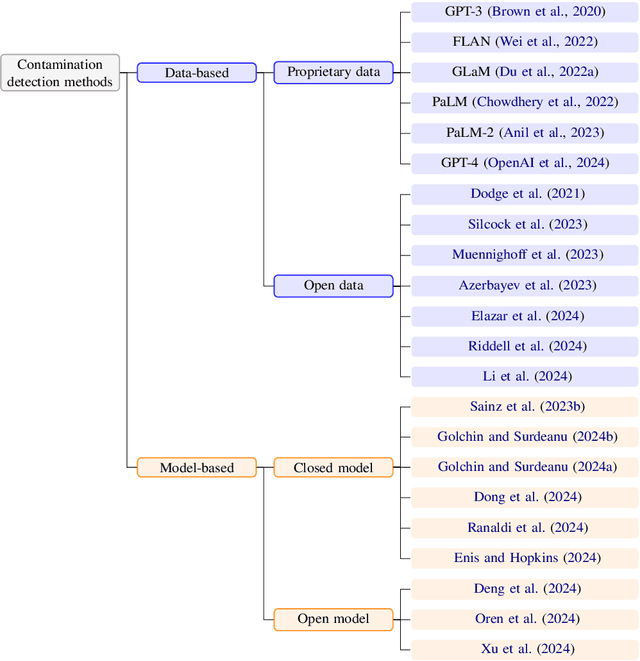
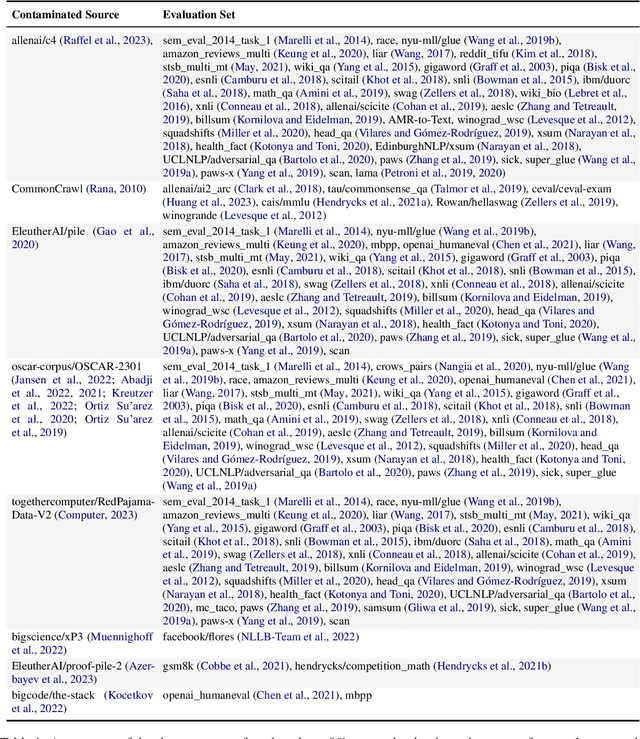
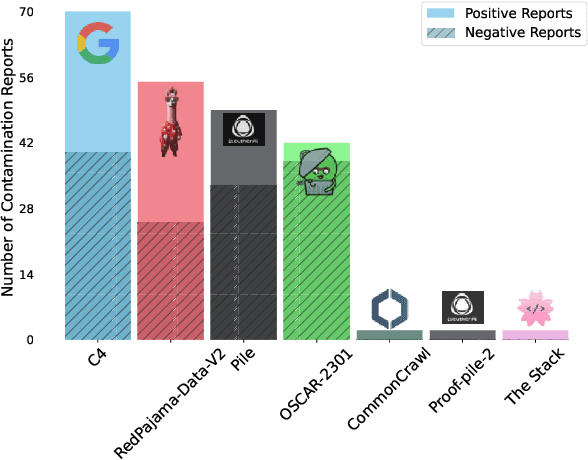
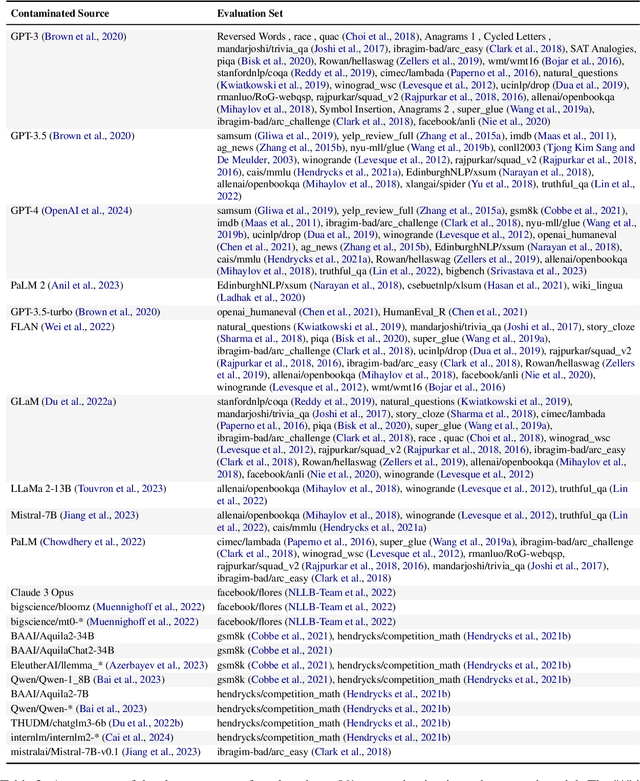
The 1st Workshop on Data Contamination (CONDA 2024) focuses on all relevant aspects of data contamination in natural language processing, where data contamination is understood as situations where evaluation data is included in pre-training corpora used to train large scale models, compromising evaluation results. The workshop fostered a shared task to collect evidence on data contamination in current available datasets and models. The goal of the shared task and associated database is to assist the community in understanding the extent of the problem and to assist researchers in avoiding reporting evaluation results on known contaminated resources. The shared task provides a structured, centralized public database for the collection of contamination evidence, open to contributions from the community via GitHub pool requests. This first compilation paper is based on 566 reported entries over 91 contaminated sources from a total of 23 contributors. The details of the individual contamination events are available in the platform. The platform continues to be online, open to contributions from the community.
Is It Really Long Context if All You Need Is Retrieval? Towards Genuinely Difficult Long Context NLP
Jun 29, 2024Improvements in language models' capabilities have pushed their applications towards longer contexts, making long-context evaluation and development an active research area. However, many disparate use-cases are grouped together under the umbrella term of "long-context", defined simply by the total length of the model's input, including - for example - Needle-in-a-Haystack tasks, book summarization, and information aggregation. Given their varied difficulty, in this position paper we argue that conflating different tasks by their context length is unproductive. As a community, we require a more precise vocabulary to understand what makes long-context tasks similar or different. We propose to unpack the taxonomy of long-context based on the properties that make them more difficult with longer contexts. We propose two orthogonal axes of difficulty: (I) Diffusion: How hard is it to find the necessary information in the context? (II) Scope: How much necessary information is there to find? We survey the literature on long-context, provide justification for this taxonomy as an informative descriptor, and situate the literature with respect to it. We conclude that the most difficult and interesting settings, whose necessary information is very long and highly diffused within the input, is severely under-explored. By using a descriptive vocabulary and discussing the relevant properties of difficulty in long-context, we can implement more informed research in this area. We call for a careful design of tasks and benchmarks with distinctly long context, taking into account the characteristics that make it qualitatively different from shorter context.
Can Few-shot Work in Long-Context? Recycling the Context to Generate Demonstrations
Jun 19, 2024Despite recent advancements in Large Language Models (LLMs), their performance on tasks involving long contexts remains sub-optimal. In-Context Learning (ICL) with few-shot examples may be an appealing solution to enhance LLM performance in this scenario; However, naively adding ICL examples with long context introduces challenges, including substantial token overhead added for each few-shot example and context mismatch between the demonstrations and the target query. In this work, we propose to automatically generate few-shot examples for long context QA tasks by recycling contexts. Specifically, given a long input context (1-3k tokens) and a query, we generate additional query-output pairs from the given context as few-shot examples, while introducing the context only once. This ensures that the demonstrations are leveraging the same context as the target query while only adding a small number of tokens to the prompt. We further enhance each demonstration by instructing the model to explicitly identify the relevant paragraphs before the answer, which improves performance while providing fine-grained attribution to the answer source. We apply our method on multiple LLMs and obtain substantial improvements on various QA datasets with long context, especially when the answer lies within the middle of the context. Surprisingly, despite introducing only single-hop ICL examples, LLMs also successfully generalize to multi-hop long-context QA using our approach.
TACT: Advancing Complex Aggregative Reasoning with Information Extraction Tools
Jun 05, 2024



Large Language Models (LLMs) often do not perform well on queries that require the aggregation of information across texts. To better evaluate this setting and facilitate modeling efforts, we introduce TACT - Text And Calculations through Tables, a dataset crafted to evaluate LLMs' reasoning and computational abilities using complex instructions. TACT contains challenging instructions that demand stitching information scattered across one or more texts, and performing complex integration on this information to generate the answer. We construct this dataset by leveraging an existing dataset of texts and their associated tables. For each such tables, we formulate new queries, and gather their respective answers. We demonstrate that all contemporary LLMs perform poorly on this dataset, achieving an accuracy below 38\%. To pinpoint the difficulties and thoroughly dissect the problem, we analyze model performance across three components: table-generation, Pandas command-generation, and execution. Unexpectedly, we discover that each component presents substantial challenges for current LLMs. These insights lead us to propose a focused modeling framework, which we refer to as IE as a tool. Specifically, we propose to add "tools" for each of the above steps, and implement each such tool with few-shot prompting. This approach shows an improvement over existing prompting techniques, offering a promising direction for enhancing model capabilities in these tasks.
A Chain-of-Thought Is as Strong as Its Weakest Link: A Benchmark for Verifiers of Reasoning Chains
Feb 02, 2024
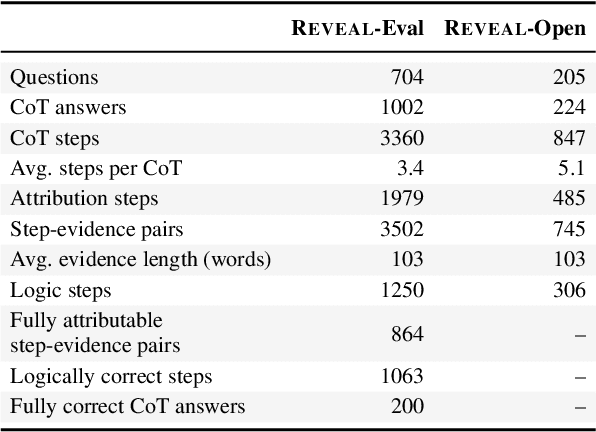
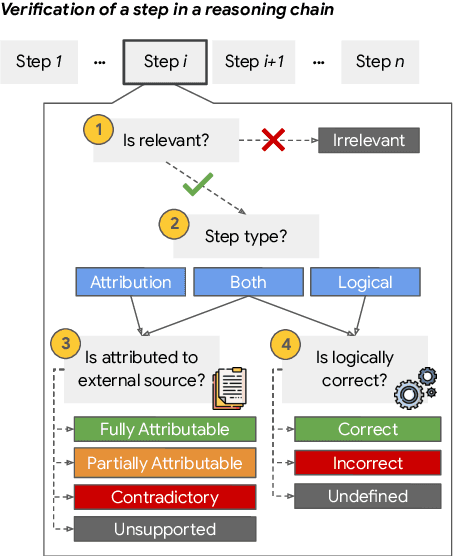
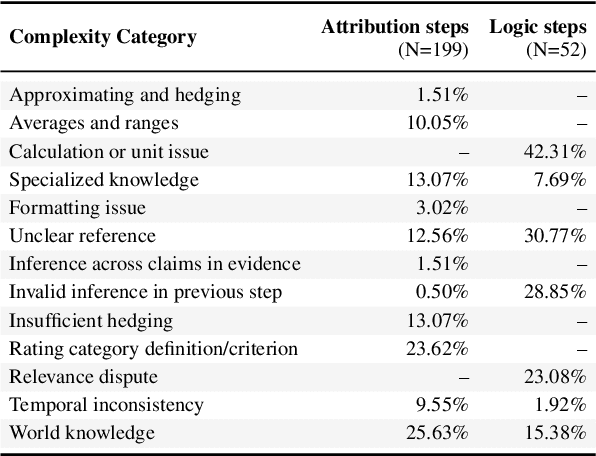
Prompting language models to provide step-by-step answers (e.g., "Chain-of-Thought") is the prominent approach for complex reasoning tasks, where more accurate reasoning chains typically improve downstream task performance. Recent literature discusses automatic methods to verify reasoning steps to evaluate and improve their correctness. However, no fine-grained step-level datasets are available to enable thorough evaluation of such verification methods, hindering progress in this direction. We introduce Reveal: Reasoning Verification Evaluation, a new dataset to benchmark automatic verifiers of complex Chain-of-Thought reasoning in open-domain question answering settings. Reveal includes comprehensive labels for the relevance, attribution to evidence passages, and logical correctness of each reasoning step in a language model's answer, across a wide variety of datasets and state-of-the-art language models.