 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeep Guessing? When Considering Inference Scaling, Mind the Baselines
Oct 20, 2024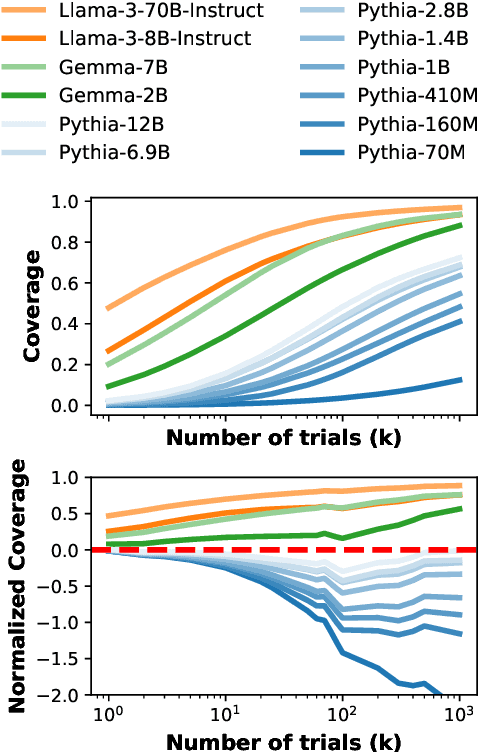
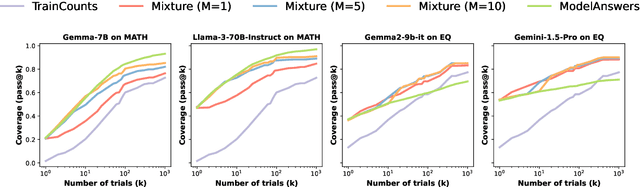

Scaling inference compute in large language models (LLMs) through repeated sampling consistently increases the coverage (fraction of problems solved) as the number of samples increases. We conjecture that this observed improvement is partially due to the answer distribution of standard evaluation benchmarks, which is skewed towards a relatively small set of common answers. To test this conjecture, we define a baseline that enumerates answers according to their prevalence in the training set. Experiments spanning two domains -- mathematical reasoning and factual knowledge -- reveal that this baseline outperforms repeated model sampling for some LLMs, while the coverage for others is on par with that of a mixture strategy that obtains $k$ answers by using only $10$ model samples and similarly guessing the remaining $k-10$ attempts via enumeration. Our baseline enables a more accurate measurement of how much repeated sampling improves coverage in such settings beyond prompt-agnostic guessing.
A Chain-of-Thought Is as Strong as Its Weakest Link: A Benchmark for Verifiers of Reasoning Chains
Feb 02, 2024
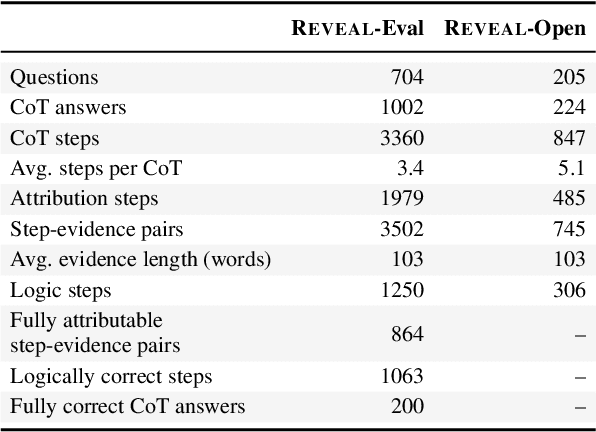
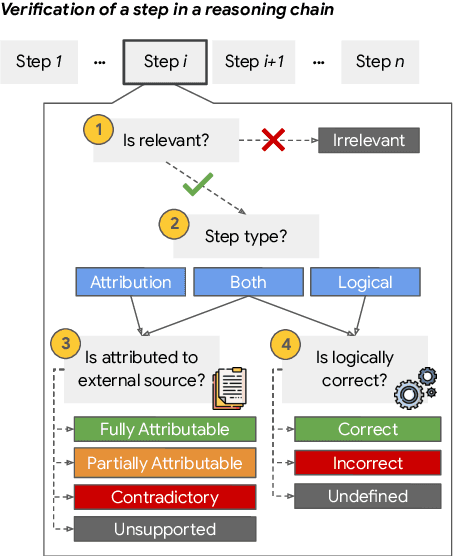
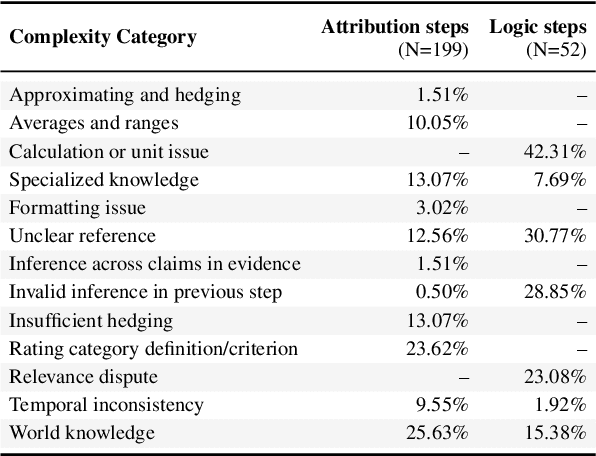
Prompting language models to provide step-by-step answers (e.g., "Chain-of-Thought") is the prominent approach for complex reasoning tasks, where more accurate reasoning chains typically improve downstream task performance. Recent literature discusses automatic methods to verify reasoning steps to evaluate and improve their correctness. However, no fine-grained step-level datasets are available to enable thorough evaluation of such verification methods, hindering progress in this direction. We introduce Reveal: Reasoning Verification Evaluation, a new dataset to benchmark automatic verifiers of complex Chain-of-Thought reasoning in open-domain question answering settings. Reveal includes comprehensive labels for the relevance, attribution to evidence passages, and logical correctness of each reasoning step in a language model's answer, across a wide variety of datasets and state-of-the-art language models.
Surfacing Biases in Large Language Models using Contrastive Input Decoding
May 12, 2023Ensuring that large language models (LMs) are fair, robust and useful requires an understanding of how different modifications to their inputs impact the model's behaviour. In the context of open-text generation tasks, however, such an evaluation is not trivial. For example, when introducing a model with an input text and a perturbed, "contrastive" version of it, meaningful differences in the next-token predictions may not be revealed with standard decoding strategies. With this motivation in mind, we propose Contrastive Input Decoding (CID): a decoding algorithm to generate text given two inputs, where the generated text is likely given one input but unlikely given the other. In this way, the contrastive generations can highlight potentially subtle differences in how the LM output differs for the two inputs in a simple and interpretable manner. We use CID to highlight context-specific biases that are hard to detect with standard decoding strategies and quantify the effect of different input perturbations.
Unnatural Instructions: Tuning Language Models with (Almost) No Human Labor
Dec 19, 2022



Instruction tuning enables pretrained language models to perform new tasks from inference-time natural language descriptions. These approaches rely on vast amounts of human supervision in the form of crowdsourced datasets or user interactions. In this work, we introduce Unnatural Instructions: a large dataset of creative and diverse instructions, collected with virtually no human labor. We collect 64,000 examples by prompting a language model with three seed examples of instructions and eliciting a fourth. This set is then expanded by prompting the model to rephrase each instruction, creating a total of approximately 240,000 examples of instructions, inputs, and outputs. Experiments show that despite containing a fair amount of noise, training on Unnatural Instructions rivals the effectiveness of training on open-source manually-curated datasets, surpassing the performance of models such as T0++ and Tk-Instruct across various benchmarks. These results demonstrate the potential of model-generated data as a cost-effective alternative to crowdsourcing for dataset expansion and diversification.
DisentQA: Disentangling Parametric and Contextual Knowledge with Counterfactual Question Answering
Nov 10, 2022Question answering models commonly have access to two sources of "knowledge" during inference time: (1) parametric knowledge - the factual knowledge encoded in the model weights, and (2) contextual knowledge - external knowledge (e.g., a Wikipedia passage) given to the model to generate a grounded answer. Having these two sources of knowledge entangled together is a core issue for generative QA models as it is unclear whether the answer stems from the given non-parametric knowledge or not. This unclarity has implications on issues of trust, interpretability and factuality. In this work, we propose a new paradigm in which QA models are trained to disentangle the two sources of knowledge. Using counterfactual data augmentation, we introduce a model that predicts two answers for a given question: one based on given contextual knowledge and one based on parametric knowledge. Our experiments on the Natural Questions dataset show that this approach improves the performance of QA models by making them more robust to knowledge conflicts between the two knowledge sources, while generating useful disentangled answers.
LMentry: A Language Model Benchmark of Elementary Language Tasks
Nov 03, 2022As the performance of large language models rapidly improves, benchmarks are getting larger and more complex as well. We present LMentry, a benchmark that avoids this "arms race" by focusing on a compact set of tasks that are trivial to humans, e.g. writing a sentence containing a specific word, identifying which words in a list belong to a specific category, or choosing which of two words is longer. LMentry is specifically designed to provide quick and interpretable insights into the capabilities and robustness of large language models. Our experiments reveal a wide variety of failure cases that, while immediately obvious to humans, pose a considerable challenge for large language models, including OpenAI's latest 175B-parameter instruction-tuned model, TextDavinci002. LMentry complements contemporary evaluation approaches of large language models, providing a quick, automatic, and easy-to-run "unit test", without resorting to large benchmark suites of complex tasks.
Instruction Induction: From Few Examples to Natural Language Task Descriptions
May 22, 2022
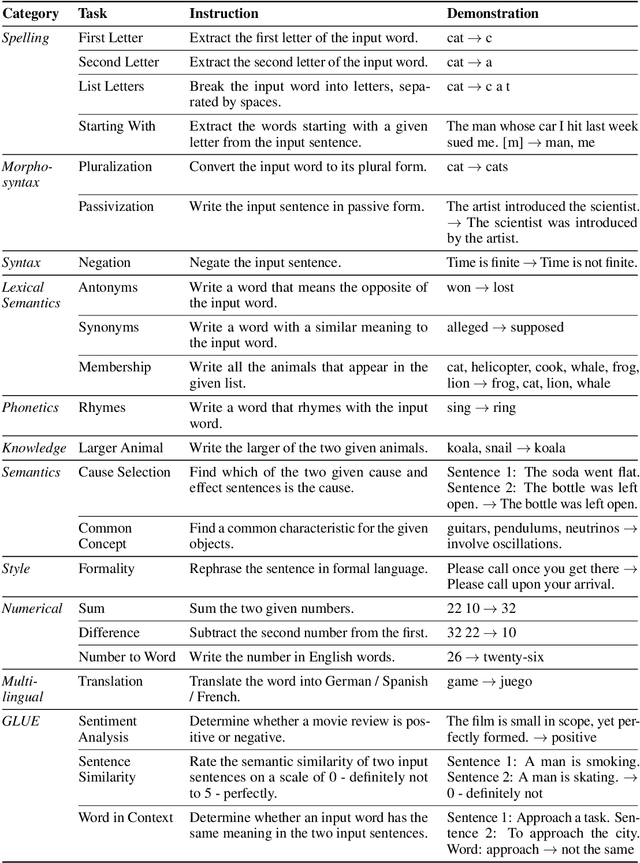


Large language models are able to perform a task by conditioning on a few input-output demonstrations - a paradigm known as in-context learning. We show that language models can explicitly infer an underlying task from a few demonstrations by prompting them to generate a natural language instruction that fits the examples. To explore this ability, we introduce the instruction induction challenge, compile a dataset consisting of 24 tasks, and define a novel evaluation metric based on executing the generated instruction. We discover that, to a large extent, the ability to generate instructions does indeed emerge when using a model that is both large enough and aligned to follow instructions; InstructGPT achieves 65.7% of human performance in our execution-based metric, while the original GPT-3 model reaches only 9.8% of human performance. This surprising result suggests that instruction induction might be a viable learning paradigm in and of itself, where instead of fitting a set of latent continuous parameters to the data, one searches for the best description in the natural language hypothesis space.
TRUE: Re-evaluating Factual Consistency Evaluation
Apr 11, 2022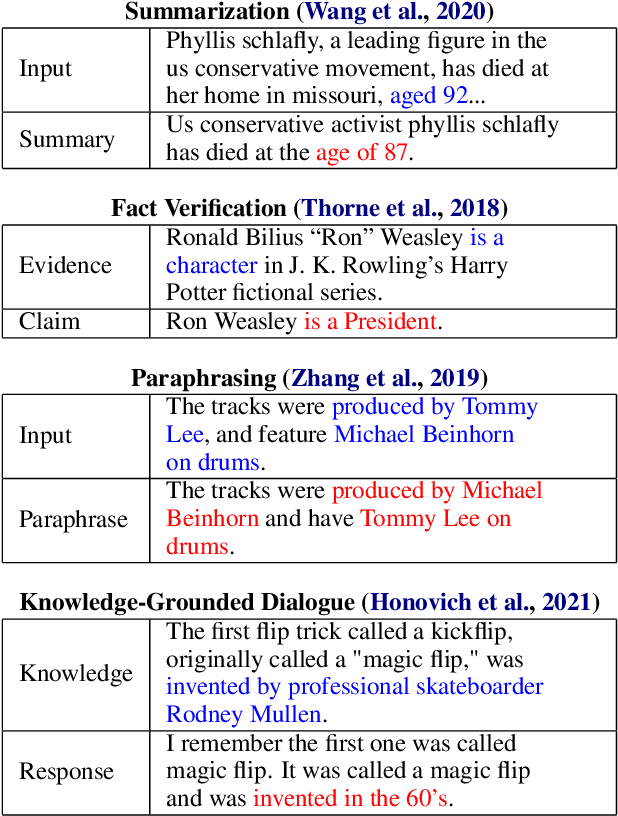
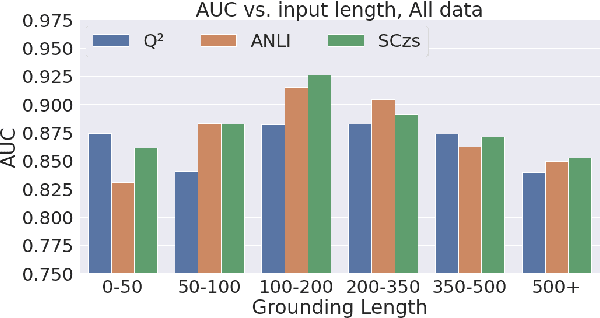
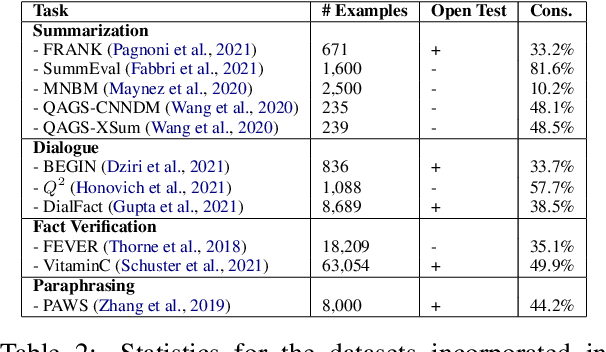
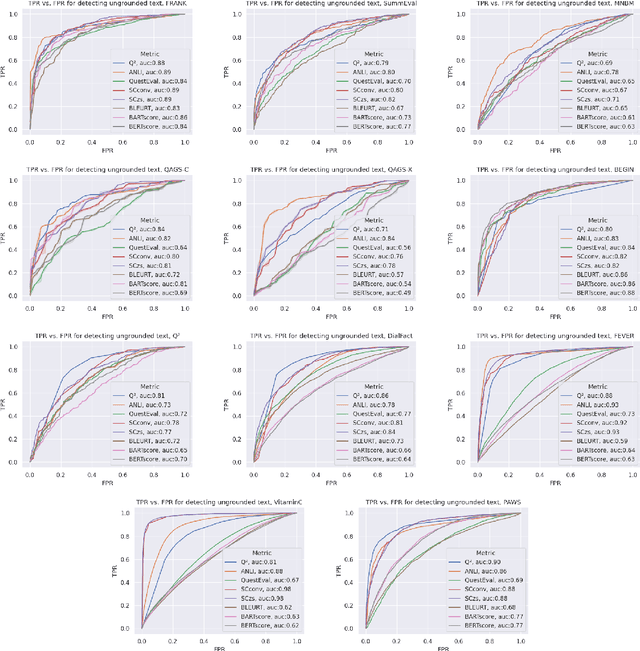
Grounded text generation systems often generate text that contains factual inconsistencies, hindering their real-world applicability. Automatic factual consistency evaluation may help alleviate this limitation by accelerating evaluation cycles, filtering inconsistent outputs and augmenting training data. While attracting increasing attention, such evaluation metrics are usually developed and evaluated in silo for a single task or dataset, slowing their adoption. Moreover, previous meta-evaluation protocols focused on system-level correlations with human annotations, which leave the example-level accuracy of such metrics unclear. In this work, we introduce TRUE: a comprehensive study of factual consistency metrics on a standardized collection of existing texts from diverse tasks, manually annotated for factual consistency. Our standardization enables an example-level meta-evaluation protocol that is more actionable and interpretable than previously reported correlations, yielding clearer quality measures. Across diverse state-of-the-art metrics and 11 datasets we find that large-scale NLI and question generation-and-answering-based approaches achieve strong and complementary results. We recommend those methods as a starting point for model and metric developers, and hope TRUE will foster progress towards even better methods.
$Q^{2}$: Evaluating Factual Consistency in Knowledge-Grounded Dialogues via Question Generation and Question Answering
Apr 16, 2021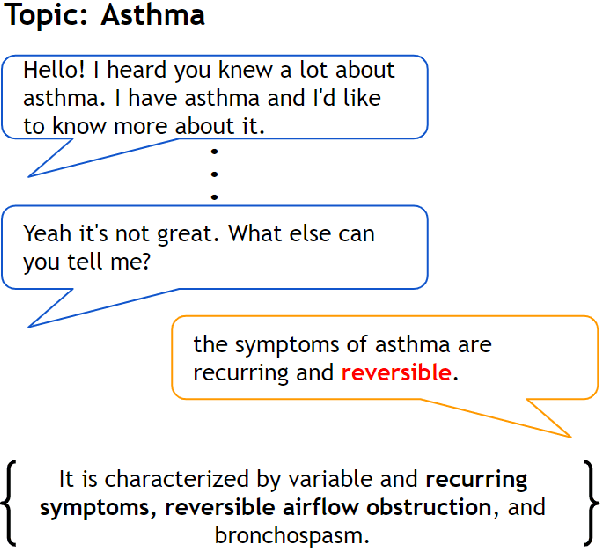

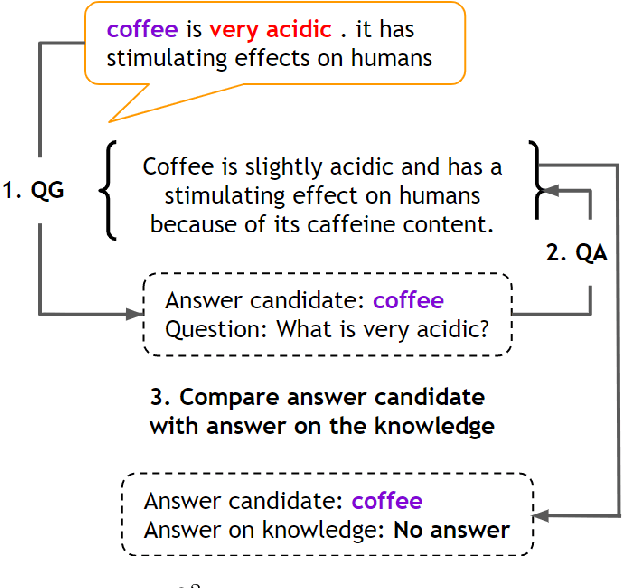
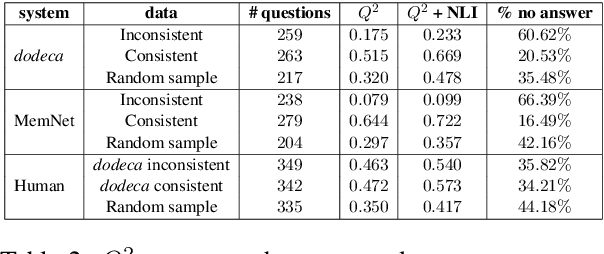
Neural knowledge-grounded generative models for dialogue often produce content that is factually inconsistent with the source text they rely on. As a consequence, such models are unreliable, limiting their real-world applicability. Inspired by recent work on evaluating factual consistency in abstractive summarization (Durmus et al., 2020; Wang et al., 2020), we propose an automatic evaluation metric for factual consistency in knowledge-grounded dialogue models using automatic question generation and question answering. Unlike previous works which use naive token-based comparison of answer spans, our metric makes use of co-reference resolution and natural language inference capabilities which greatly improve its performance. To foster proper evaluation, we curate a novel dataset of state-of-the-art dialogue system outputs for the Wizard-of-Wikipedia dataset (Dinan et al., 2019), which we manually annotate for factual consistency. We perform a thorough meta-evaluation of our metric against other metrics using the new dataset and two others, where it greatly outperforms the baselines.