 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$Q^{2}$: Evaluating Factual Consistency in Knowledge-Grounded Dialogues via Question Generation and Question Answering
Paper and Code
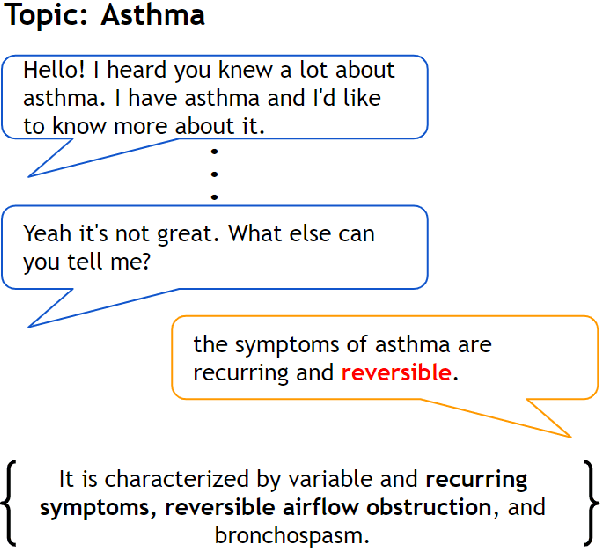

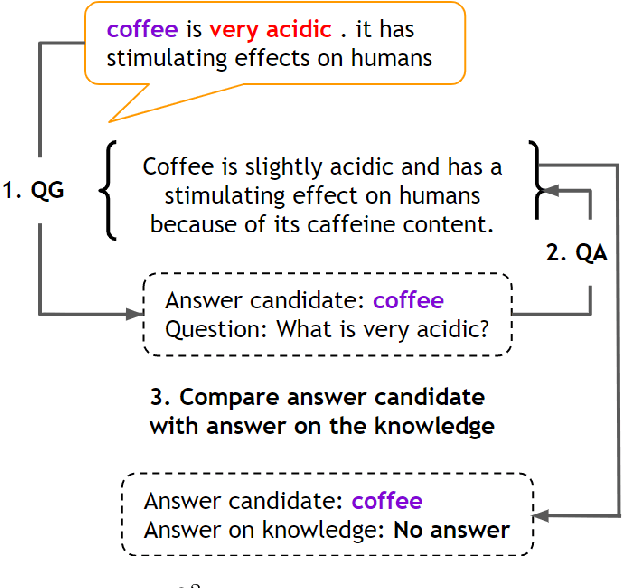
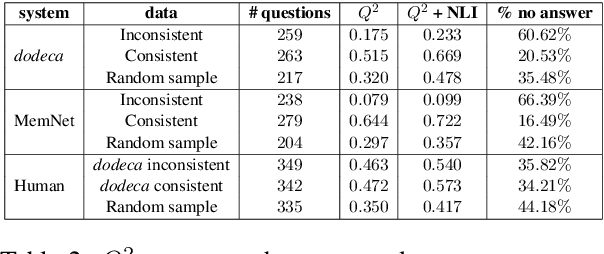
Neural knowledge-grounded generative models for dialogue often produce content that is factually inconsistent with the source text they rely on. As a consequence, such models are unreliable, limiting their real-world applicability. Inspired by recent work on evaluating factual consistency in abstractive summarization (Durmus et al., 2020; Wang et al., 2020), we propose an automatic evaluation metric for factual consistency in knowledge-grounded dialogue models using automatic question generation and question answering. Unlike previous works which use naive token-based comparison of answer spans, our metric makes use of co-reference resolution and natural language inference capabilities which greatly improve its performance. To foster proper evaluation, we curate a novel dataset of state-of-the-art dialogue system outputs for the Wizard-of-Wikipedia dataset (Dinan et al., 2019), which we manually annotate for factual consistency. We perform a thorough meta-evaluation of our metric against other metrics using the new dataset and two others, where it greatly outperforms the baselines.