 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRAGged into Conflicts: Detecting and Addressing Conflicting Sources in Search-Augmented LLMs
Jun 10, 2025Retrieval Augmented Generation (RAG) is a commonly used approach for enhancing large language models (LLMs) with relevant and up-to-date information. However, the retrieved sources can often contain conflicting information and it remains unclear how models should address such discrepancies. In this work, we first propose a novel taxonomy of knowledge conflict types in RAG, along with the desired model behavior for each type. We then introduce CONFLICTS, a high-quality benchmark with expert annotations of conflict types in a realistic RAG setting. CONFLICTS is the first benchmark that enables tracking progress on how models address a wide range of knowledge conflicts. We conduct extensive experiments on this benchmark, showing that LLMs often struggle to appropriately resolve conflicts between sources. While prompting LLMs to explicitly reason about the potential conflict in the retrieved documents significantly improves the quality and appropriateness of their responses, substantial room for improvement in future research remains.
Keep Guessing? When Considering Inference Scaling, Mind the Baselines
Oct 20, 2024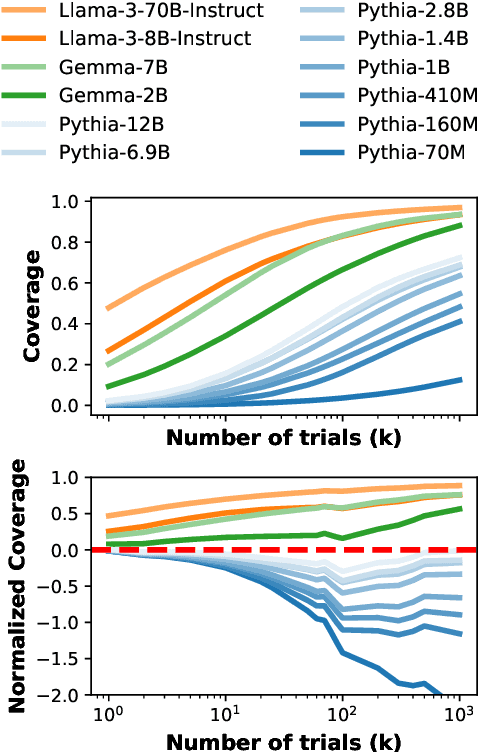
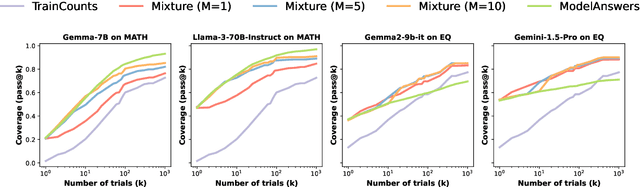

Scaling inference compute in large language models (LLMs) through repeated sampling consistently increases the coverage (fraction of problems solved) as the number of samples increases. We conjecture that this observed improvement is partially due to the answer distribution of standard evaluation benchmarks, which is skewed towards a relatively small set of common answers. To test this conjecture, we define a baseline that enumerates answers according to their prevalence in the training set. Experiments spanning two domains -- mathematical reasoning and factual knowledge -- reveal that this baseline outperforms repeated model sampling for some LLMs, while the coverage for others is on par with that of a mixture strategy that obtains $k$ answers by using only $10$ model samples and similarly guessing the remaining $k-10$ attempts via enumeration. Our baseline enables a more accurate measurement of how much repeated sampling improves coverage in such settings beyond prompt-agnostic guessing.
Localizing Factual Inconsistencies in Attributable Text Generation
Oct 09, 2024
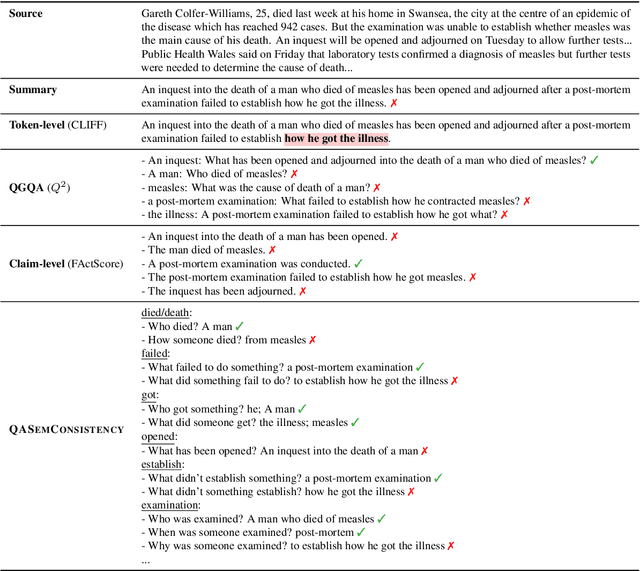

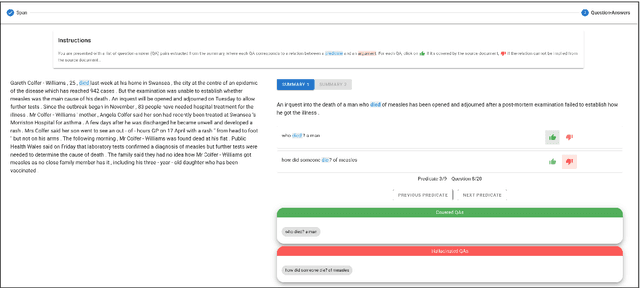
There has been an increasing interest in detecting hallucinations in model-generated texts, both manually and automatically, at varying levels of granularity. However, most existing methods fail to precisely pinpoint the errors. In this work, we introduce QASemConsistency, a new formalism for localizing factual inconsistencies in attributable text generation, at a fine-grained level. Drawing inspiration from Neo-Davidsonian formal semantics, we propose decomposing the generated text into minimal predicate-argument level propositions, expressed as simple question-answer (QA) pairs, and assess whether each individual QA pair is supported by a trusted reference text. As each QA pair corresponds to a single semantic relation between a predicate and an argument, QASemConsistency effectively localizes the unsupported information. We first demonstrate the effectiveness of the QASemConsistency methodology for human annotation, by collecting crowdsourced annotations of granular consistency errors, while achieving a substantial inter-annotator agreement ($\kappa > 0.7)$. Then, we implement several methods for automatically detecting localized factual inconsistencies, with both supervised entailment models and open-source LLMs.
Beneath the Surface of Consistency: Exploring Cross-lingual Knowledge Representation Sharing in LLMs
Aug 20, 2024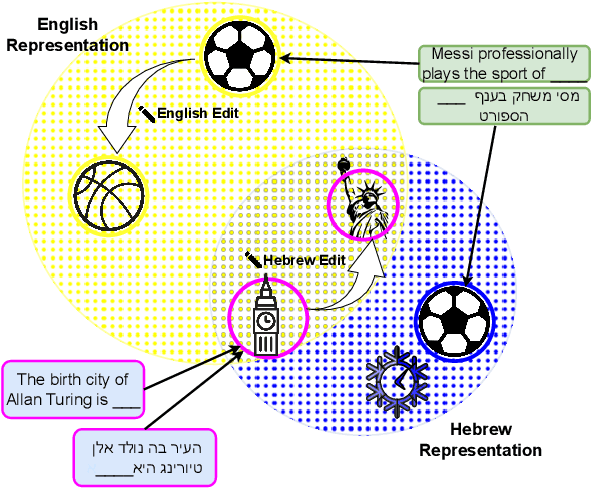
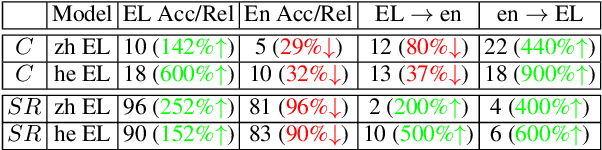
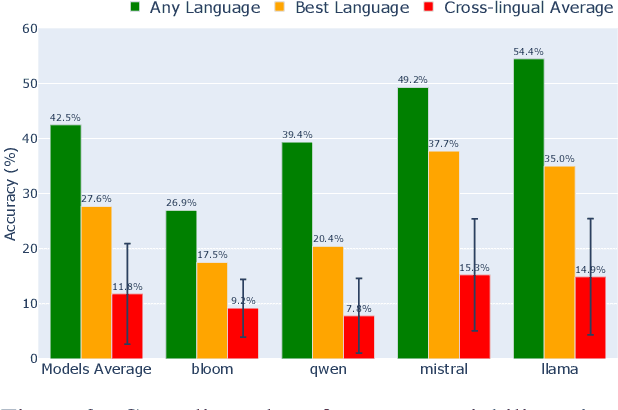
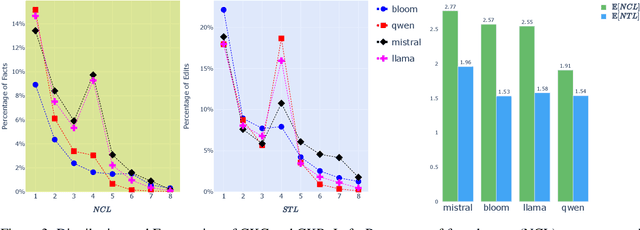
The veracity of a factoid is largely independent of the language it is written in. However, language models are inconsistent in their ability to answer the same factual question across languages. This raises questions about how LLMs represent a given fact across languages. We explore multilingual factual knowledge through two aspects: the model's ability to answer a query consistently across languages, and the ability to ''store'' answers in a shared representation for several languages. We propose a methodology to measure the extent of representation sharing across languages by repurposing knowledge editing methods. We examine LLMs with various multilingual configurations using a new multilingual dataset. We reveal that high consistency does not necessarily imply shared representation, particularly for languages with different scripts. Moreover, we find that script similarity is a dominant factor in representation sharing. Finally, we observe that if LLMs could fully share knowledge across languages, their accuracy in their best-performing language could benefit an increase of up to 150\% on average. These findings highlight the need for improved multilingual knowledge representation in LLMs and suggest a path for the development of more robust and consistent multilingual LLMs.
Can Few-shot Work in Long-Context? Recycling the Context to Generate Demonstrations
Jun 19, 2024Despite recent advancements in Large Language Models (LLMs), their performance on tasks involving long contexts remains sub-optimal. In-Context Learning (ICL) with few-shot examples may be an appealing solution to enhance LLM performance in this scenario; However, naively adding ICL examples with long context introduces challenges, including substantial token overhead added for each few-shot example and context mismatch between the demonstrations and the target query. In this work, we propose to automatically generate few-shot examples for long context QA tasks by recycling contexts. Specifically, given a long input context (1-3k tokens) and a query, we generate additional query-output pairs from the given context as few-shot examples, while introducing the context only once. This ensures that the demonstrations are leveraging the same context as the target query while only adding a small number of tokens to the prompt. We further enhance each demonstration by instructing the model to explicitly identify the relevant paragraphs before the answer, which improves performance while providing fine-grained attribution to the answer source. We apply our method on multiple LLMs and obtain substantial improvements on various QA datasets with long context, especially when the answer lies within the middle of the context. Surprisingly, despite introducing only single-hop ICL examples, LLMs also successfully generalize to multi-hop long-context QA using our approach.
Can Large Language Models Faithfully Express Their Intrinsic Uncertainty in Words?
May 27, 2024We posit that large language models (LLMs) should be capable of expressing their intrinsic uncertainty in natural language. For example, if the LLM is equally likely to output two contradicting answers to the same question, then its generated response should reflect this uncertainty by hedging its answer (e.g., "I'm not sure, but I think..."). We formalize faithful response uncertainty based on the gap between the model's intrinsic confidence in the assertions it makes and the decisiveness by which they are conveyed. This example-level metric reliably indicates whether the model reflects its uncertainty, as it penalizes both excessive and insufficient hedging. We evaluate a variety of aligned LLMs at faithfully communicating uncertainty on several knowledge-intensive question answering tasks. Our results provide strong evidence that modern LLMs are poor at faithfully conveying their uncertainty, and that better alignment is necessary to improve their trustworthiness.
Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?
May 09, 2024

When large language models are aligned via supervised fine-tuning, they may encounter new factual information that was not acquired through pre-training. It is often conjectured that this can teach the model the behavior of hallucinating factually incorrect responses, as the model is trained to generate facts that are not grounded in its pre-existing knowledge. In this work, we study the impact of such exposure to new knowledge on the capability of the fine-tuned model to utilize its pre-existing knowledge. To this end, we design a controlled setup, focused on closed-book QA, where we vary the proportion of the fine-tuning examples that introduce new knowledge. We demonstrate that large language models struggle to acquire new factual knowledge through fine-tuning, as fine-tuning examples that introduce new knowledge are learned significantly slower than those consistent with the model's knowledge. However, we also find that as the examples with new knowledge are eventually learned, they linearly increase the model's tendency to hallucinate. Taken together, our results highlight the risk in introducing new factual knowledge through fine-tuning, and support the view that large language models mostly acquire factual knowledge through pre-training, whereas fine-tuning teaches them to use it more efficiently.
MiMiC: Minimally Modified Counterfactuals in the Representation Space
Feb 16, 2024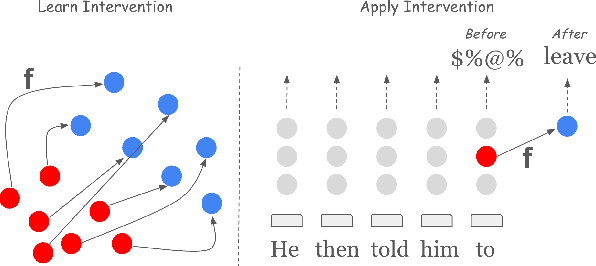
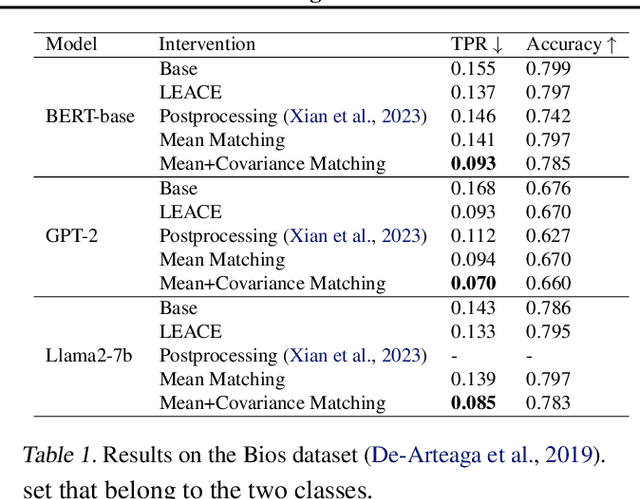
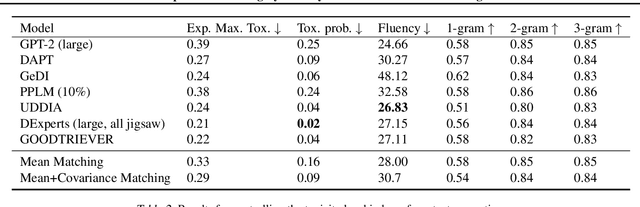
Language models often exhibit undesirable behaviors, such as gender bias or toxic language. Interventions in the representation space were shown effective in mitigating such issues by altering the LM behavior. We first show that two prominent intervention techniques, Linear Erasure and Steering Vectors, do not enable a high degree of control and are limited in expressivity. We then propose a novel intervention methodology for generating expressive counterfactuals in the representation space, aiming to make representations of a source class (e.g., "toxic") resemble those of a target class (e.g., "non-toxic"). This approach, generalizing previous linear intervention techniques, utilizes a closed-form solution for the Earth Mover's problem under Gaussian assumptions and provides theoretical guarantees on the representation space's geometric organization. We further build on this technique and derive a nonlinear intervention that enables controlled generation. We demonstrate the effectiveness of the proposed approaches in mitigating bias in multiclass classification and in reducing the generation of toxic language, outperforming strong baselines.
A Chain-of-Thought Is as Strong as Its Weakest Link: A Benchmark for Verifiers of Reasoning Chains
Feb 02, 2024
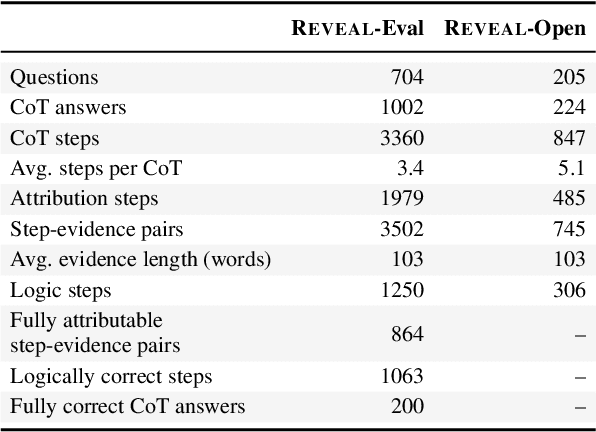
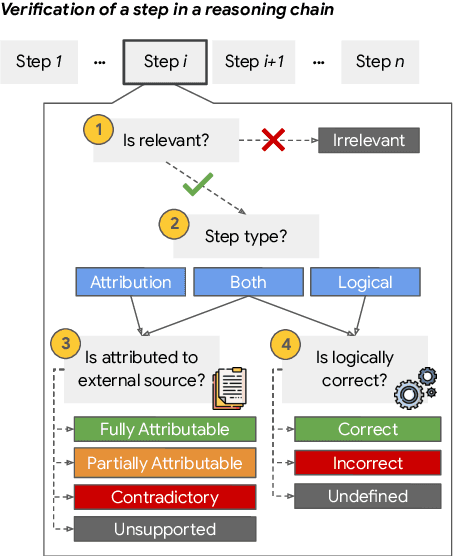
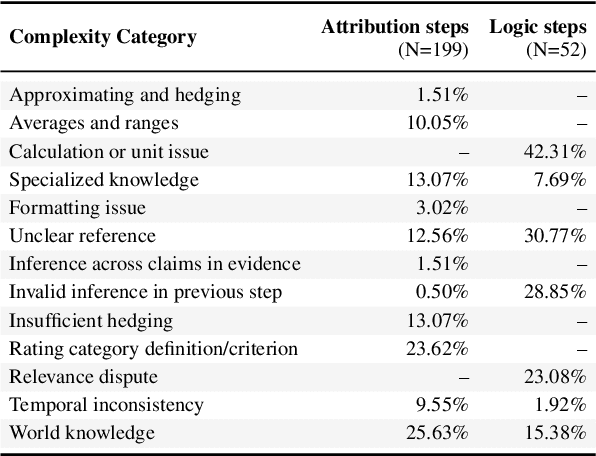
Prompting language models to provide step-by-step answers (e.g., "Chain-of-Thought") is the prominent approach for complex reasoning tasks, where more accurate reasoning chains typically improve downstream task performance. Recent literature discusses automatic methods to verify reasoning steps to evaluate and improve their correctness. However, no fine-grained step-level datasets are available to enable thorough evaluation of such verification methods, hindering progress in this direction. We introduce Reveal: Reasoning Verification Evaluation, a new dataset to benchmark automatic verifiers of complex Chain-of-Thought reasoning in open-domain question answering settings. Reveal includes comprehensive labels for the relevance, attribution to evidence passages, and logical correctness of each reasoning step in a language model's answer, across a wide variety of datasets and state-of-the-art language models.
Narrowing the Knowledge Evaluation Gap: Open-Domain Question Answering with Multi-Granularity Answers
Jan 09, 2024Factual questions typically can be answered correctly at different levels of granularity. For example, both ``August 4, 1961'' and ``1961'' are correct answers to the question ``When was Barack Obama born?''. Standard question answering (QA) evaluation protocols, however, do not explicitly take this into account and compare a predicted answer against answers of a single granularity level. In this work, we propose GRANOLA QA, a novel evaluation setting where a predicted answer is evaluated in terms of accuracy and informativeness against a set of multi-granularity answers. We present a simple methodology for enriching existing datasets with multi-granularity answers, and create GRANOLA-EQ, a multi-granularity version of the EntityQuestions dataset. We evaluate a range of decoding methods on GRANOLA-EQ, including a new algorithm, called Decoding with Response Aggregation (DRAG), that is geared towards aligning the response granularity with the model's uncertainty. Our experiments show that large language models with standard decoding tend to generate specific answers, which are often incorrect. In contrast, when evaluated on multi-granularity answers, DRAG yields a nearly 20 point increase in accuracy on average, which further increases for rare entities. Overall, this reveals that standard evaluation and decoding schemes may significantly underestimate the knowledge encapsulated in LMs.