 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocation Not Found: Exposing Implicit Local and Global Biases in Multilingual LLMs
Apr 21, 2026Multilingual large language models (LLMs) have minimized the fluency gap between languages. This advancement, however, exposes models to the risk of biased behavior, as knowledge and norms may propagate across languages. In this work, we aim to quantify models' inter- and intra-lingual biases, via their ability to answer locale-ambiguous questions. To this end, we present LocQA, a test set containing 2,156 questions in 12 languages, referring to various locale-dependent facts such as laws, dates, and measurements. The questions do not contain indications of the locales they relate to, other than the querying language itself. LLMs' responses to LocQA locale-ambiguous questions thus reveal models' implicit priors. We used LocQA to evaluate 32 models, and detected two types of structural biases. Inter-lingually, we show a global bias towards answers relevant to the US-locale, even when models are asked in languages other than English. Moreover, we discovered that this global bias is exacerbated in models that underwent instruction tuning, compared to their base counterparts. Intra-lingually, we show that when multiple locales are relevant for the same language, models act as demographic probability engines, prioritizing locales with larger populations. Taken together, insights from LocQA may help in shaping LLMs' desired local behavior, and in quantifying the impact of various training phases on different kinds of biases.
Gemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
ECLeKTic: a Novel Challenge Set for Evaluation of Cross-Lingual Knowledge Transfer
Feb 28, 2025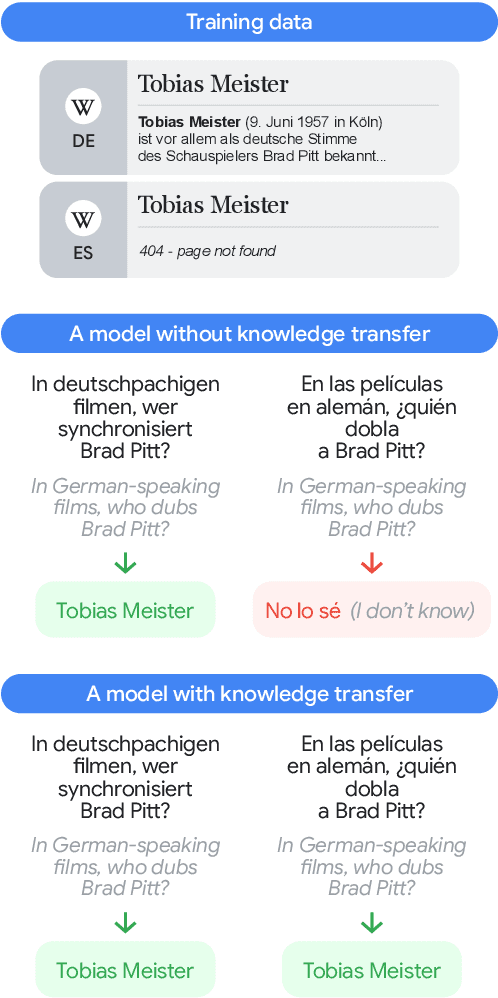
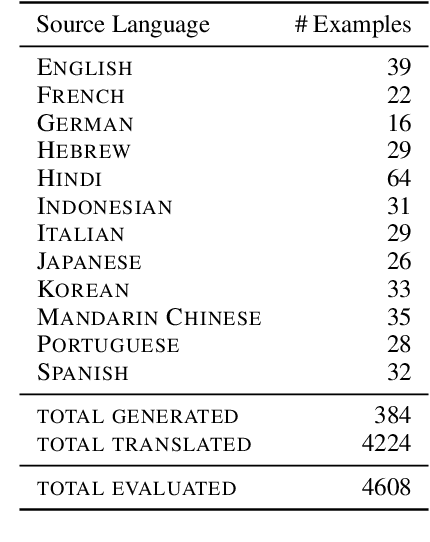
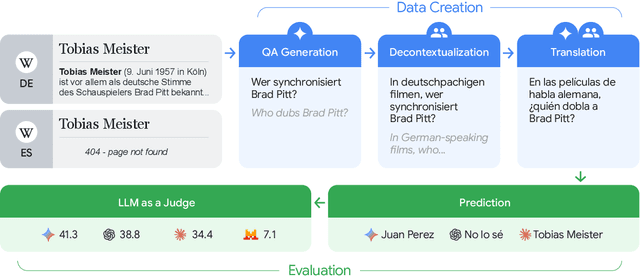
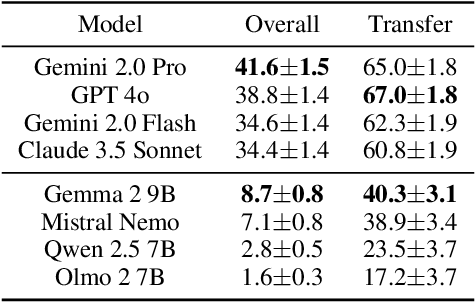
To achieve equitable performance across languages, multilingual large language models (LLMs) must be able to abstract knowledge beyond the language in which it was acquired. However, the current literature lacks reliable ways to measure LLMs' capability of cross-lingual knowledge transfer. To that end, we present ECLeKTic, a multilingual closed-book QA (CBQA) dataset that Evaluates Cross-Lingual Knowledge Transfer in a simple, black-box manner. We detected information with uneven coverage across languages by controlling for presence and absence of Wikipedia articles in 12 languages. We generated knowledge-seeking questions in a source language, for which the answer appears in a relevant Wikipedia article and translated them to all other 11 languages, for which the respective Wikipedias lack equivalent articles. Assuming that Wikipedia reflects the prominent knowledge in the LLM's training data, to solve ECLeKTic's CBQA task the model is required to transfer knowledge between languages. Experimenting with 8 LLMs, we show that SOTA models struggle to effectively share knowledge across, languages even if they can predict the answer well for queries in the same language the knowledge was acquired in.
Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?
May 09, 2024

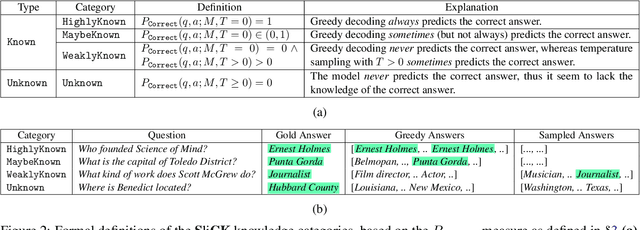
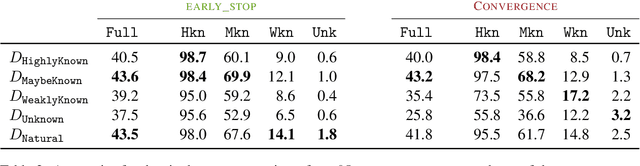
When large language models are aligned via supervised fine-tuning, they may encounter new factual information that was not acquired through pre-training. It is often conjectured that this can teach the model the behavior of hallucinating factually incorrect responses, as the model is trained to generate facts that are not grounded in its pre-existing knowledge. In this work, we study the impact of such exposure to new knowledge on the capability of the fine-tuned model to utilize its pre-existing knowledge. To this end, we design a controlled setup, focused on closed-book QA, where we vary the proportion of the fine-tuning examples that introduce new knowledge. We demonstrate that large language models struggle to acquire new factual knowledge through fine-tuning, as fine-tuning examples that introduce new knowledge are learned significantly slower than those consistent with the model's knowledge. However, we also find that as the examples with new knowledge are eventually learned, they linearly increase the model's tendency to hallucinate. Taken together, our results highlight the risk in introducing new factual knowledge through fine-tuning, and support the view that large language models mostly acquire factual knowledge through pre-training, whereas fine-tuning teaches them to use it more efficiently.
Unpacking Tokenization: Evaluating Text Compression and its Correlation with Model Performance
Mar 10, 2024Despite it being the cornerstone of BPE, the most common tokenization algorithm, the importance of compression in the tokenization process is still unclear. In this paper, we argue for the theoretical importance of compression, that can be viewed as 0-gram language modeling where equal probability is assigned to all tokens. We also demonstrate the empirical importance of compression for downstream success of pre-trained language models. We control the compression ability of several BPE tokenizers by varying the amount of documents available during their training: from 1 million documents to a character-based tokenizer equivalent to no training data at all. We then pre-train English language models based on those tokenizers and fine-tune them over several tasks. We show that there is a correlation between tokenizers' compression and models' downstream performance, suggesting that compression is a reliable intrinsic indicator of tokenization quality. These correlations are more pronounced for generation tasks (over classification) or for smaller models (over large ones). We replicated a representative part of our experiments on Turkish and found similar results, confirming that our results hold for languages with typological characteristics dissimilar to English. We conclude that building better compressing tokenizers is a fruitful avenue for further research and for improving overall model performance.
Breaking the Language Barrier: Can Direct Inference Outperform Pre-Translation in Multilingual LLM Applications?
Mar 04, 2024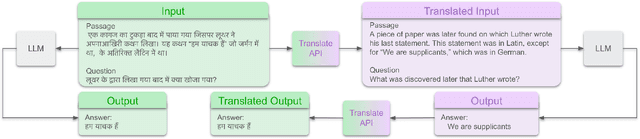
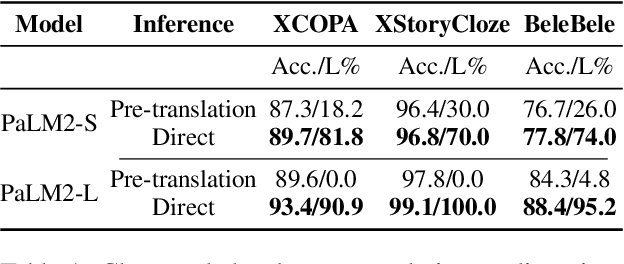

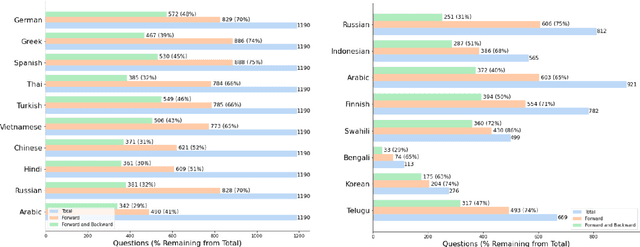
Large language models hold significant promise in multilingual applications. However, inherent biases stemming from predominantly English-centric pre-training have led to the widespread practice of pre-translation, i.e., translating non-English inputs to English before inference, leading to complexity and information loss. This study re-evaluates the need for pre-translation in the context of PaLM2 models (Anil et al., 2023), which have been established as highly performant in multilingual tasks. We offer a comprehensive investigation across 108 languages and 6 diverse benchmarks, including open-end generative tasks, which were excluded from previous similar studies. Our findings challenge the pre-translation paradigm established in prior research, highlighting the advantages of direct inference in PaLM2. Specifically, PaLM2-L consistently outperforms pre-translation in 94 out of 108 languages. These findings pave the way for more efficient and effective multilingual applications, alleviating the limitations associated with pre-translation and unlocking linguistic authenticity.
The Hidden Space of Transformer Language Adapters
Feb 20, 2024
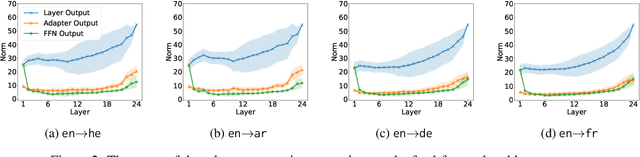

We analyze the operation of transformer language adapters, which are small modules trained on top of a frozen language model to adapt its predictions to new target languages. We show that adapted predictions mostly evolve in the source language the model was trained on, while the target language becomes pronounced only in the very last layers of the model. Moreover, the adaptation process is gradual and distributed across layers, where it is possible to skip small groups of adapters without decreasing adaptation performance. Last, we show that adapters operate on top of the model's frozen representation space while largely preserving its structure, rather than on an 'isolated' subspace. Our findings provide a deeper view into the adaptation process of language models to new languages, showcasing the constraints imposed on it by the underlying model and introduces practical implications to enhance its efficiency.
Multilingual Instruction Tuning With Just a Pinch of Multilinguality
Jan 08, 2024As instruction-tuned large language models (LLMs) gain global adoption, their ability to follow instructions in multiple languages becomes increasingly crucial. One promising approach is cross-lingual transfer, where a model acquires specific functionality on some language by finetuning on another language. In this work, we investigate how multilinguality during instruction tuning of a multilingual LLM affects instruction-following across languages. We first show that many languages transfer some instruction-following capabilities to other languages from even monolingual tuning. Furthermore, we find that only 40 multilingual examples in an English tuning set substantially improve multilingual instruction-following, both in seen and unseen languages during tuning. In general, we observe that models tuned on multilingual mixtures exhibit comparable or superior performance in several languages compared to monolingually tuned models, despite training on 10x fewer examples in those languages. Finally, we find that increasing the number of languages in the instruction tuning set from 1 to only 2, 3, or 4 increases cross-lingual generalization. Our results suggest that building massively multilingual instruction-tuned models can be done with only a very small set of multilingual instruction-responses.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Multilingual Sequence-to-Sequence Models for Hebrew NLP
Dec 19, 2022


Recent work attributes progress in NLP to large language models (LMs) with increased model size and large quantities of pretraining data. Despite this, current state-of-the-art LMs for Hebrew are both under-parameterized and under-trained compared to LMs in other languages. Additionally, previous work on pretrained Hebrew LMs focused on encoder-only models. While the encoder-only architecture is beneficial for classification tasks, it does not cater well for sub-word prediction tasks, such as Named Entity Recognition, when considering the morphologically rich nature of Hebrew. In this paper we argue that sequence-to-sequence generative architectures are more suitable for LLMs in the case of morphologically rich languages (MRLs) such as Hebrew. We demonstrate that by casting tasks in the Hebrew NLP pipeline as text-to-text tasks, we can leverage powerful multilingual, pretrained sequence-to-sequence models as mT5, eliminating the need for a specialized, morpheme-based, separately fine-tuned decoder. Using this approach, our experiments show substantial improvements over previously published results on existing Hebrew NLP benchmarks. These results suggest that multilingual sequence-to-sequence models present a promising building block for NLP for MRLs.