 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Factual Entailment with NLI: A News Media Study
Jun 24, 2024



We explore the relationship between factuality and Natural Language Inference (NLI) by introducing FactRel -- a novel annotation scheme that models \textit{factual} rather than \textit{textual} entailment, and use it to annotate a dataset of naturally occurring sentences from news articles. Our analysis shows that 84\% of factually supporting pairs and 63\% of factually undermining pairs do not amount to NLI entailment or contradiction, respectively, suggesting that factual relationships are more apt for analyzing media discourse. We experiment with models for pairwise classification on the new dataset, and find that in some cases, generating synthetic data with GPT-4 on the basis of the annotated dataset can improve performance. Surprisingly, few-shot learning with GPT-4 yields strong results on par with medium LMs (DeBERTa) trained on the labelled dataset. We hypothesize that these results indicate the fundamental dependence of this task on both world knowledge and advanced reasoning abilities.
IsraParlTweet: The Israeli Parliamentary and Twitter Resource
May 30, 2024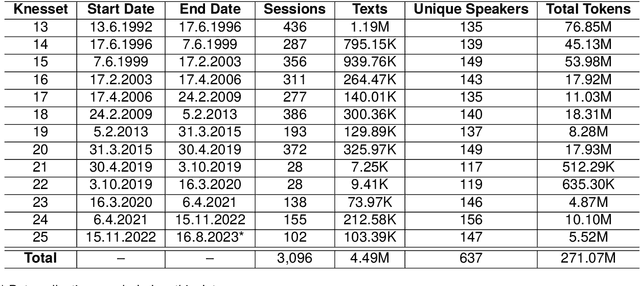
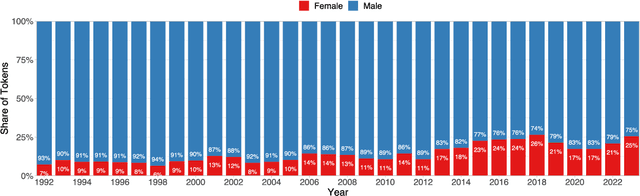


We introduce IsraParlTweet, a new linked corpus of Hebrew-language parliamentary discussions from the Knesset (Israeli Parliament) between the years 1992-2023 and Twitter posts made by Members of the Knesset between the years 2008-2023, containing a total of 294.5 million Hebrew tokens. In addition to raw text, the corpus contains comprehensive metadata on speakers and Knesset sessions as well as several linguistic annotations. As a result, IsraParlTweet can be used to conduct a wide variety of quantitative and qualitative analyses and provide valuable insights into political discourse in Israel.