 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIsraParlTweet: The Israeli Parliamentary and Twitter Resource
May 30, 2024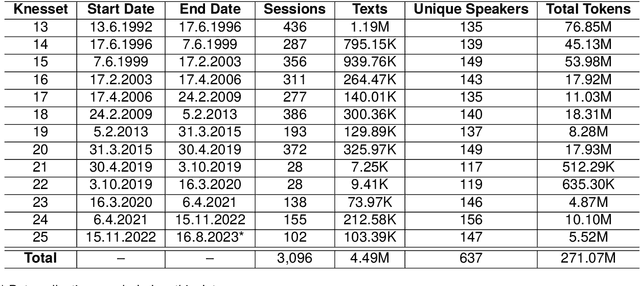
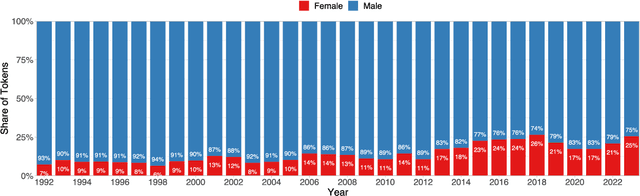


We introduce IsraParlTweet, a new linked corpus of Hebrew-language parliamentary discussions from the Knesset (Israeli Parliament) between the years 1992-2023 and Twitter posts made by Members of the Knesset between the years 2008-2023, containing a total of 294.5 million Hebrew tokens. In addition to raw text, the corpus contains comprehensive metadata on speakers and Knesset sessions as well as several linguistic annotations. As a result, IsraParlTweet can be used to conduct a wide variety of quantitative and qualitative analyses and provide valuable insights into political discourse in Israel.
Reap the Wild Wind: Detecting Media Storms in Large-Scale News Corpora
Apr 14, 2024

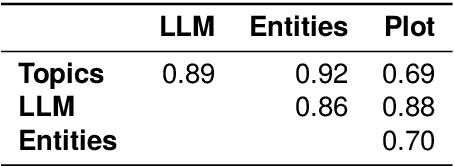

Media Storms, dramatic outbursts of attention to a story, are central components of media dynamics and the attention landscape. Despite their significance, there has been little systematic and empirical research on this concept due to issues of measurement and operationalization. We introduce an iterative human-in-the-loop method to identify media storms in a large-scale corpus of news articles. The text is first transformed into signals of dispersion based on several textual characteristics. In each iteration, we apply unsupervised anomaly detection to these signals; each anomaly is then validated by an expert to confirm the presence of a storm, and those results are then used to tune the anomaly detection in the next iteration. We demonstrate the applicability of this method in two scenarios: first, supplementing an initial list of media storms within a specific time frame; and second, detecting media storms in new time periods. We make available a media storm dataset compiled using both scenarios. Both the method and dataset offer the basis for comprehensive empirical research into the concept of media storms, including characterizing them and predicting their outbursts and durations, in mainstream media or social media platforms.
Detecting Narrative Elements in Informational Text
Oct 06, 2022
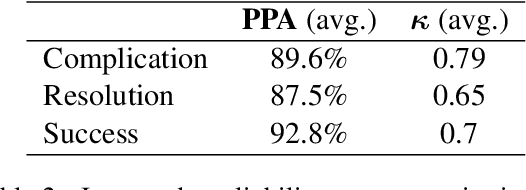
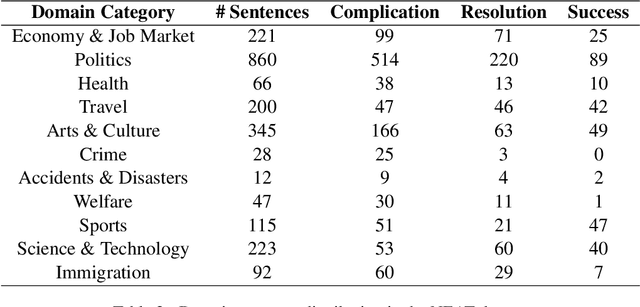
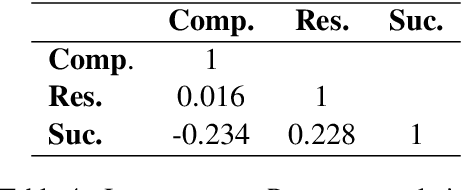
Automatic extraction of narrative elements from text, combining narrative theories with computational models, has been receiving increasing attention over the last few years. Previous works have utilized the oral narrative theory by Labov and Waletzky to identify various narrative elements in personal stories texts. Instead, we direct our focus to informational texts, specifically news stories. We introduce NEAT (Narrative Elements AnnoTation) - a novel NLP task for detecting narrative elements in raw text. For this purpose, we designed a new multi-label narrative annotation scheme, better suited for informational text (e.g. news media), by adapting elements from the narrative theory of Labov and Waletzky (Complication and Resolution) and adding a new narrative element of our own (Success). We then used this scheme to annotate a new dataset of 2,209 sentences, compiled from 46 news articles from various category domains. We trained a number of supervised models in several different setups over the annotated dataset to identify the different narrative elements, achieving an average F1 score of up to 0.77. The results demonstrate the holistic nature of our annotation scheme as well as its robustness to domain category.
CompRes: A Dataset for Narrative Structure in News
Jul 09, 2020

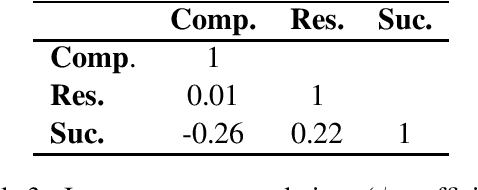

This paper addresses the task of automatically detecting narrative structures in raw texts. Previous works have utilized the oral narrative theory by Labov and Waletzky to identify various narrative elements in personal stories texts. Instead, we direct our focus to news articles, motivated by their growing social impact as well as their role in creating and shaping public opinion. We introduce CompRes -- the first dataset for narrative structure in news media. We describe the process in which the dataset was constructed: first, we designed a new narrative annotation scheme, better suited for news media, by adapting elements from the narrative theory of Labov and Waletzky (Complication and Resolution) and adding a new narrative element of our own (Success); then, we used that scheme to annotate a set of 29 English news articles (containing 1,099 sentences) collected from news and partisan websites. We use the annotated dataset to train several supervised models to identify the different narrative elements, achieving an $F_1$ score of up to 0.7. We conclude by suggesting several promising directions for future work.