 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Narrative Elements in Informational Text
Oct 06, 2022
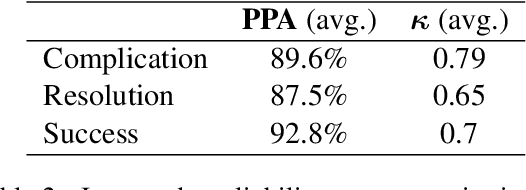
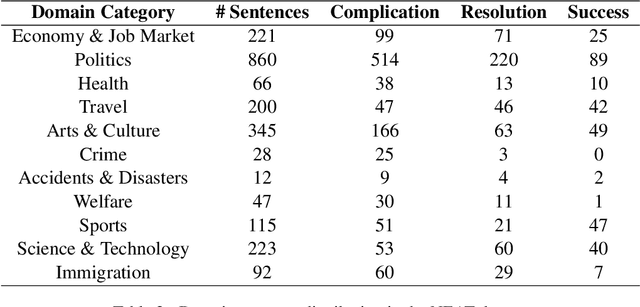
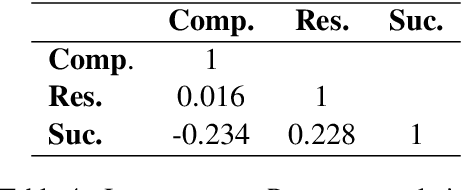
Automatic extraction of narrative elements from text, combining narrative theories with computational models, has been receiving increasing attention over the last few years. Previous works have utilized the oral narrative theory by Labov and Waletzky to identify various narrative elements in personal stories texts. Instead, we direct our focus to informational texts, specifically news stories. We introduce NEAT (Narrative Elements AnnoTation) - a novel NLP task for detecting narrative elements in raw text. For this purpose, we designed a new multi-label narrative annotation scheme, better suited for informational text (e.g. news media), by adapting elements from the narrative theory of Labov and Waletzky (Complication and Resolution) and adding a new narrative element of our own (Success). We then used this scheme to annotate a new dataset of 2,209 sentences, compiled from 46 news articles from various category domains. We trained a number of supervised models in several different setups over the annotated dataset to identify the different narrative elements, achieving an average F1 score of up to 0.77. The results demonstrate the holistic nature of our annotation scheme as well as its robustness to domain category.
CompRes: A Dataset for Narrative Structure in News
Jul 09, 2020

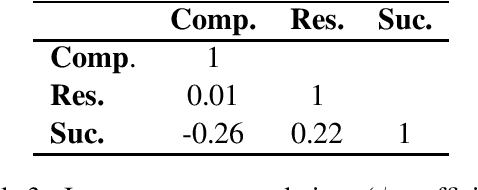

This paper addresses the task of automatically detecting narrative structures in raw texts. Previous works have utilized the oral narrative theory by Labov and Waletzky to identify various narrative elements in personal stories texts. Instead, we direct our focus to news articles, motivated by their growing social impact as well as their role in creating and shaping public opinion. We introduce CompRes -- the first dataset for narrative structure in news media. We describe the process in which the dataset was constructed: first, we designed a new narrative annotation scheme, better suited for news media, by adapting elements from the narrative theory of Labov and Waletzky (Complication and Resolution) and adding a new narrative element of our own (Success); then, we used that scheme to annotate a set of 29 English news articles (containing 1,099 sentences) collected from news and partisan websites. We use the annotated dataset to train several supervised models to identify the different narrative elements, achieving an $F_1$ score of up to 0.7. We conclude by suggesting several promising directions for future work.