 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialogues of Dissent: Thematic and Rhetorical Dimensions of Hate and Counter-Hate Speech in Social Media Conversations
Jul 28, 2025We introduce a novel multi-labeled scheme for joint annotation of hate and counter-hate speech in social media conversations, categorizing hate and counter-hate messages into thematic and rhetorical dimensions. The thematic categories outline different discursive aspects of each type of speech, while the rhetorical dimension captures how hate and counter messages are communicated, drawing on Aristotle's Logos, Ethos and Pathos. We annotate a sample of 92 conversations, consisting of 720 tweets, and conduct statistical analyses, incorporating public metrics, to explore patterns of interaction between the thematic and rhetorical dimensions within and between hate and counter-hate speech. Our findings provide insights into the spread of hate messages on social media, the strategies used to counter them, and their potential impact on online behavior.
Exploring Factual Entailment with NLI: A News Media Study
Jun 24, 2024



We explore the relationship between factuality and Natural Language Inference (NLI) by introducing FactRel -- a novel annotation scheme that models \textit{factual} rather than \textit{textual} entailment, and use it to annotate a dataset of naturally occurring sentences from news articles. Our analysis shows that 84\% of factually supporting pairs and 63\% of factually undermining pairs do not amount to NLI entailment or contradiction, respectively, suggesting that factual relationships are more apt for analyzing media discourse. We experiment with models for pairwise classification on the new dataset, and find that in some cases, generating synthetic data with GPT-4 on the basis of the annotated dataset can improve performance. Surprisingly, few-shot learning with GPT-4 yields strong results on par with medium LMs (DeBERTa) trained on the labelled dataset. We hypothesize that these results indicate the fundamental dependence of this task on both world knowledge and advanced reasoning abilities.
IsraParlTweet: The Israeli Parliamentary and Twitter Resource
May 30, 2024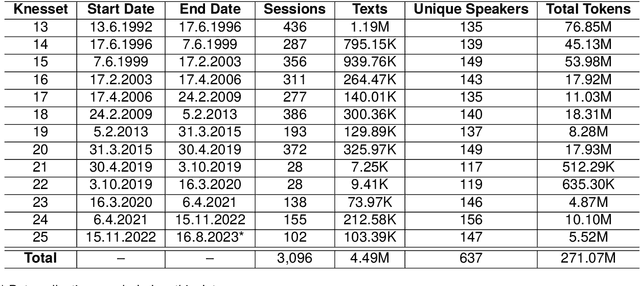
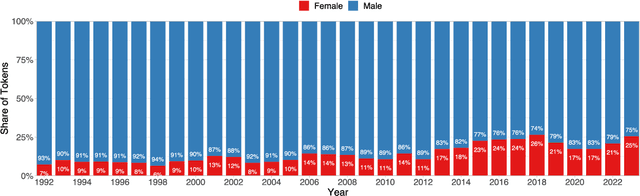


We introduce IsraParlTweet, a new linked corpus of Hebrew-language parliamentary discussions from the Knesset (Israeli Parliament) between the years 1992-2023 and Twitter posts made by Members of the Knesset between the years 2008-2023, containing a total of 294.5 million Hebrew tokens. In addition to raw text, the corpus contains comprehensive metadata on speakers and Knesset sessions as well as several linguistic annotations. As a result, IsraParlTweet can be used to conduct a wide variety of quantitative and qualitative analyses and provide valuable insights into political discourse in Israel.
Reap the Wild Wind: Detecting Media Storms in Large-Scale News Corpora
Apr 14, 2024


Media Storms, dramatic outbursts of attention to a story, are central components of media dynamics and the attention landscape. Despite their significance, there has been little systematic and empirical research on this concept due to issues of measurement and operationalization. We introduce an iterative human-in-the-loop method to identify media storms in a large-scale corpus of news articles. The text is first transformed into signals of dispersion based on several textual characteristics. In each iteration, we apply unsupervised anomaly detection to these signals; each anomaly is then validated by an expert to confirm the presence of a storm, and those results are then used to tune the anomaly detection in the next iteration. We demonstrate the applicability of this method in two scenarios: first, supplementing an initial list of media storms within a specific time frame; and second, detecting media storms in new time periods. We make available a media storm dataset compiled using both scenarios. Both the method and dataset offer the basis for comprehensive empirical research into the concept of media storms, including characterizing them and predicting their outbursts and durations, in mainstream media or social media platforms.
Factoring Hate Speech: A New Annotation Framework to Study Hate Speech in Social Media
Nov 07, 2023



In this work we propose a novel annotation scheme which factors hate speech into five separate discursive categories. To evaluate our scheme, we construct a corpus of over 2.9M Twitter posts containing hateful expressions directed at Jews, and annotate a sample dataset of 1,050 tweets. We present a statistical analysis of the annotated dataset as well as discuss annotation examples, and conclude by discussing promising directions for future work.
Detecting Narrative Elements in Informational Text
Oct 06, 2022
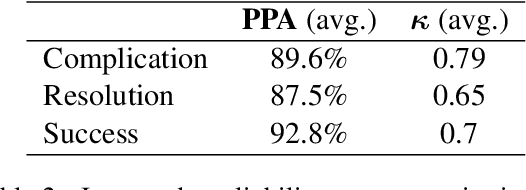
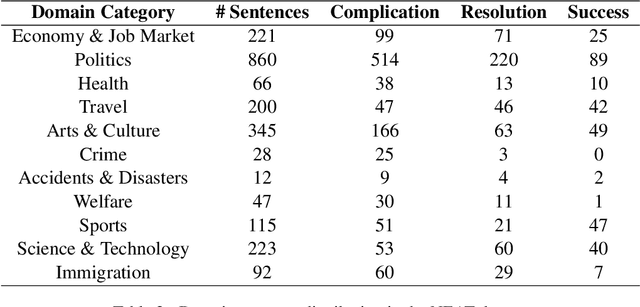
Automatic extraction of narrative elements from text, combining narrative theories with computational models, has been receiving increasing attention over the last few years. Previous works have utilized the oral narrative theory by Labov and Waletzky to identify various narrative elements in personal stories texts. Instead, we direct our focus to informational texts, specifically news stories. We introduce NEAT (Narrative Elements AnnoTation) - a novel NLP task for detecting narrative elements in raw text. For this purpose, we designed a new multi-label narrative annotation scheme, better suited for informational text (e.g. news media), by adapting elements from the narrative theory of Labov and Waletzky (Complication and Resolution) and adding a new narrative element of our own (Success). We then used this scheme to annotate a new dataset of 2,209 sentences, compiled from 46 news articles from various category domains. We trained a number of supervised models in several different setups over the annotated dataset to identify the different narrative elements, achieving an average F1 score of up to 0.77. The results demonstrate the holistic nature of our annotation scheme as well as its robustness to domain category.
A Decomposition-Based Approach for Evaluating Inter-Annotator Disagreement in Narrative Analysis
Jun 11, 2022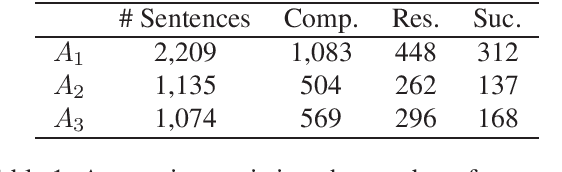
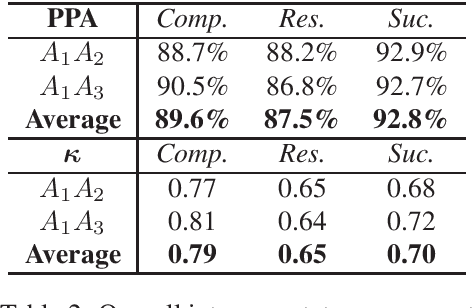
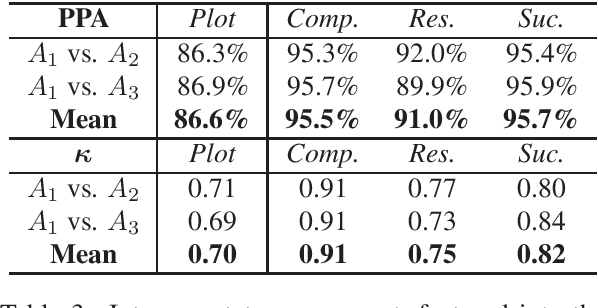
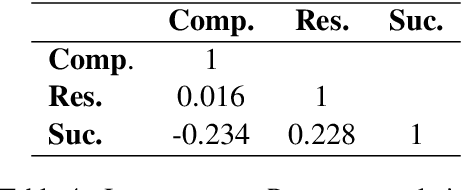
In this work, we explore sources of inter-annotator disagreement in narrative analysis, in light of the question of whether or not a narrative plot exists in the text. For this purpose, we present a method for a conceptual decomposition of an existing annotation into two separate levels: (1) \textbf{whether} or not a narrative plot exists in the text, and (2) \textbf{which} plot elements exist in the text. We apply this method to an existing dataset of sentences annotated with three different narrative plot elements: \textit{Complication}, \textit{Resolution} and \textit{Success}. We then employ statistical analysis in order to quantify how much of the inter-annotator disagreement can be explained by each of the two levels. We further perform a qualitative analysis of disagreement cases in each level, observing several sources of disagreement, such as text ambiguity, scheme definition and personal differences between the annotators. The insights gathered on the dataset may serve to reduce inter-annotator disagreement in future annotation endeavors. We conclude with a broader discussion on the potential implications of our approach in studying and evaluating inter-annotator disagreement in other settings.
CompRes: A Dataset for Narrative Structure in News
Jul 09, 2020


This paper addresses the task of automatically detecting narrative structures in raw texts. Previous works have utilized the oral narrative theory by Labov and Waletzky to identify various narrative elements in personal stories texts. Instead, we direct our focus to news articles, motivated by their growing social impact as well as their role in creating and shaping public opinion. We introduce CompRes -- the first dataset for narrative structure in news media. We describe the process in which the dataset was constructed: first, we designed a new narrative annotation scheme, better suited for news media, by adapting elements from the narrative theory of Labov and Waletzky (Complication and Resolution) and adding a new narrative element of our own (Success); then, we used that scheme to annotate a set of 29 English news articles (containing 1,099 sentences) collected from news and partisan websites. We use the annotated dataset to train several supervised models to identify the different narrative elements, achieving an $F_1$ score of up to 0.7. We conclude by suggesting several promising directions for future work.
Computing Word Classes Using Spectral Clustering
Aug 16, 2018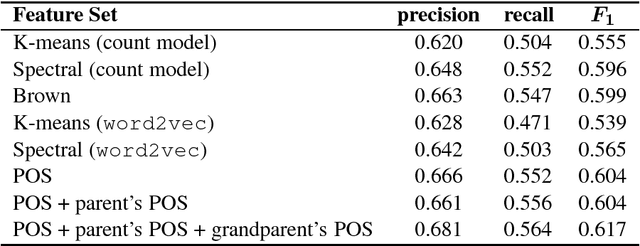


Clustering a lexicon of words is a well-studied problem in natural language processing (NLP). Word clusters are used to deal with sparse data in statistical language processing, as well as features for solving various NLP tasks (text categorization, question answering, named entity recognition and others). Spectral clustering is a widely used technique in the field of image processing and speech recognition. However, it has scarcely been explored in the context of NLP; specifically, the method used in this (Meila and Shi, 2001) has never been used to cluster a general word lexicon. We apply spectral clustering to a lexicon of words, evaluating the resulting clusters by using them as features for solving two classical NLP tasks: semantic role labeling and dependency parsing. We compare performance with Brown clustering, a widely-used technique for word clustering, as well as with other clustering methods. We show that spectral clusters produce similar results to Brown clusters, and outperform other clustering methods. In addition, we quantify the overlap between spectral and Brown clusters, showing that each model captures some information which is uncaptured by the other.
Behavior-Based Machine-Learning: A Hybrid Approach for Predicting Human Decision Making
Nov 30, 2016A large body of work in behavioral fields attempts to develop models that describe the way people, as opposed to rational agents, make decisions. A recent Choice Prediction Competition (2015) challenged researchers to suggest a model that captures 14 classic choice biases and can predict human decisions under risk and ambiguity. The competition focused on simple decision problems, in which human subjects were asked to repeatedly choose between two gamble options. In this paper we present our approach for predicting human decision behavior: we suggest to use machine learning algorithms with features that are based on well-established behavioral theories. The basic idea is that these psychological features are essential for the representation of the data and are important for the success of the learning process. We implement a vanilla model in which we train SVM models using behavioral features that rely on the psychological properties underlying the competition baseline model. We show that this basic model captures the 14 choice biases and outperforms all the other learning-based models in the competition. The preliminary results suggest that such hybrid models can significantly improve the prediction of human decision making, and are a promising direction for future research.