 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputing Word Classes Using Spectral Clustering
Aug 16, 2018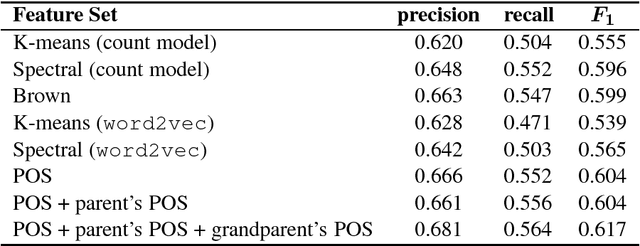


Clustering a lexicon of words is a well-studied problem in natural language processing (NLP). Word clusters are used to deal with sparse data in statistical language processing, as well as features for solving various NLP tasks (text categorization, question answering, named entity recognition and others). Spectral clustering is a widely used technique in the field of image processing and speech recognition. However, it has scarcely been explored in the context of NLP; specifically, the method used in this (Meila and Shi, 2001) has never been used to cluster a general word lexicon. We apply spectral clustering to a lexicon of words, evaluating the resulting clusters by using them as features for solving two classical NLP tasks: semantic role labeling and dependency parsing. We compare performance with Brown clustering, a widely-used technique for word clustering, as well as with other clustering methods. We show that spectral clusters produce similar results to Brown clusters, and outperform other clustering methods. In addition, we quantify the overlap between spectral and Brown clusters, showing that each model captures some information which is uncaptured by the other.