 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Assisted Decision Making with Human Learning
Feb 18, 2025AI systems increasingly support human decision-making. In many cases, despite the algorithm's superior performance, the final decision remains in human hands. For example, an AI may assist doctors in determining which diagnostic tests to run, but the doctor ultimately makes the diagnosis. This paper studies such AI-assisted decision-making settings, where the human learns through repeated interactions with the algorithm. In our framework, the algorithm -- designed to maximize decision accuracy according to its own model -- determines which features the human can consider. The human then makes a prediction based on their own less accurate model. We observe that the discrepancy between the algorithm's model and the human's model creates a fundamental tradeoff. Should the algorithm prioritize recommending more informative features, encouraging the human to recognize their importance, even if it results in less accurate predictions in the short term until learning occurs? Or is it preferable to forgo educating the human and instead select features that align more closely with their existing understanding, minimizing the immediate cost of learning? This tradeoff is shaped by the algorithm's time-discounted objective and the human's learning ability. Our results show that optimal feature selection has a surprisingly clean combinatorial characterization, reducible to a stationary sequence of feature subsets that is tractable to compute. As the algorithm becomes more "patient" or the human's learning improves, the algorithm increasingly selects more informative features, enhancing both prediction accuracy and the human's understanding. Notably, early investment in learning leads to the selection of more informative features than a later investment. We complement our analysis by showing that the impact of errors in the algorithm's knowledge is limited as it does not make the prediction directly.
Decongestion by Representation: Learning to Improve Economic Welfare in Marketplaces
Jun 18, 2023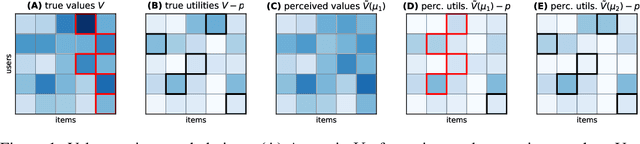
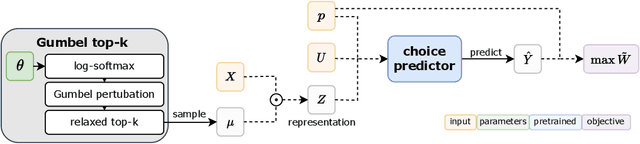
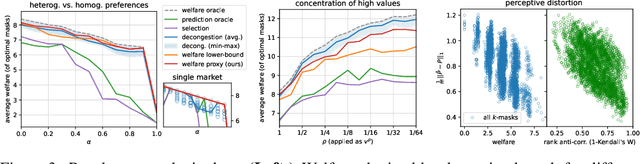
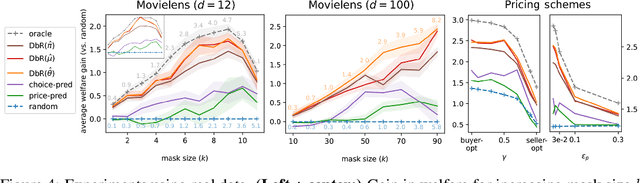
Congestion is a common failure mode of markets, where consumers compete inefficiently on the same subset of goods (e.g., chasing the same small set of properties on a vacation rental platform). The typical economic story is that prices solve this problem by balancing supply and demand in order to decongest the market. But in modern online marketplaces, prices are typically set in a decentralized way by sellers, with the power of a platform limited to controlling representations -- the information made available about products. This motivates the present study of decongestion by representation, where a platform uses this power to learn representations that improve social welfare by reducing congestion. The technical challenge is twofold: relying only on revealed preferences from users' past choices, rather than true valuations; and working with representations that determine which features to reveal and are inherently combinatorial. We tackle both by proposing a differentiable proxy of welfare that can be trained end-to-end on consumer choice data. We provide theory giving sufficient conditions for when decongestion promotes welfare, and present experiments on both synthetic and real data shedding light on our setting and approach.
Learning When to Advise Human Decision Makers
Sep 27, 2022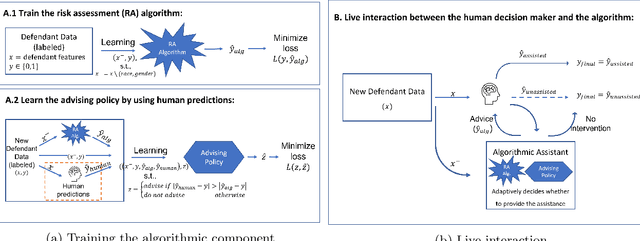
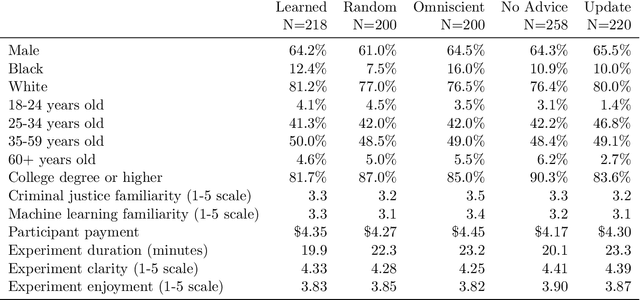
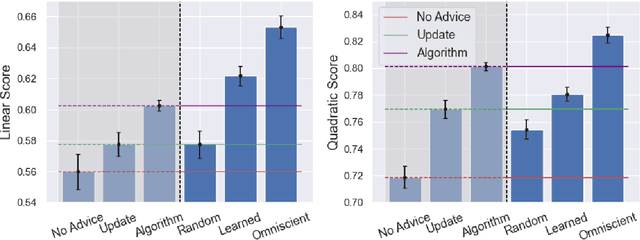
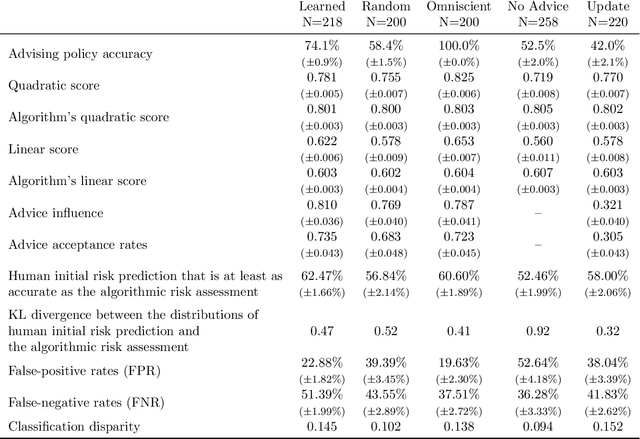
Artificial intelligence (AI) systems are increasingly used for providing advice to facilitate human decision making. While a large body of work has explored how AI systems can be optimized to produce accurate and fair advice and how algorithmic advice should be presented to human decision makers, in this work we ask a different basic question: When should algorithms provide advice? Motivated by limitations of the current practice of constantly providing algorithmic advice, we propose the design of AI systems that interact with the human user in a two-sided manner and provide advice only when it is likely to be beneficial to the human in making their decision. Our AI systems learn advising policies using past human decisions. Then, for new cases, the learned policies utilize input from the human to identify cases where algorithmic advice would be useful, as well as those where the human is better off deciding alone. We conduct a large-scale experiment to evaluate our approach by using data from the US criminal justice system on pretrial-release decisions. In our experiment, participants were asked to assess the risk of defendants to violate their release terms if released and were advised by different advising approaches. The results show that our interactive-advising approach manages to provide advice at times of need and to significantly improve human decision making compared to fixed, non-interactive advising approaches. Our approach has additional advantages in facilitating human learning, preserving complementary strengths of human decision makers, and leading to more positive responsiveness to the advice.
From Behavioral Theories to Econometrics: Inferring Preferences of Human Agents from Data on Repeated Interactions
Dec 30, 2021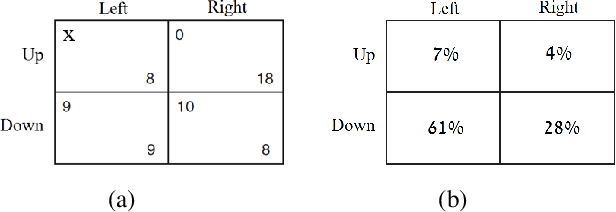
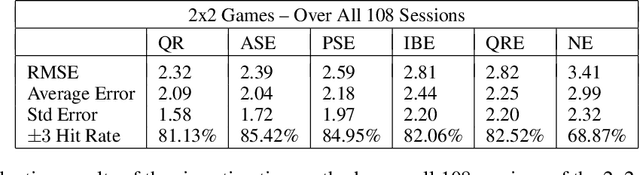
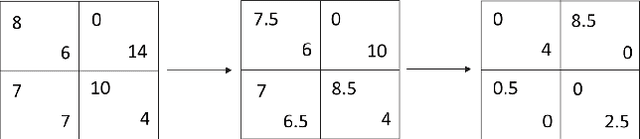
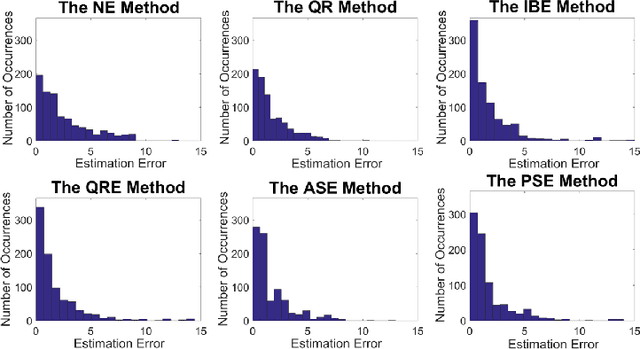
We consider the problem of estimating preferences of human agents from data of strategic systems where the agents repeatedly interact. Recently, it was demonstrated that a new estimation method called "quantal regret" produces more accurate estimates for human agents than the classic approach that assumes that agents are rational and reach a Nash equilibrium; however, this method has not been compared to methods that take into account behavioral aspects of human play. In this paper we leverage equilibrium concepts from behavioral economics for this purpose and ask how well they perform compared to the quantal regret and Nash equilibrium methods. We develop four estimation methods based on established behavioral equilibrium models to infer the utilities of human agents from observed data of normal-form games. The equilibrium models we study are quantal-response equilibrium, action-sampling equilibrium, payoff-sampling equilibrium, and impulse-balance equilibrium. We show that in some of these concepts the inference is achieved analytically via closed formulas, while in the others the inference is achieved only algorithmically. We use experimental data of 2x2 games to evaluate the estimation success of these behavioral equilibrium methods. The results show that the estimates they produce are more accurate than the estimates of the Nash equilibrium. The comparison with the quantal-regret method shows that the behavioral methods have better hit rates, but the quantal-regret method performs better in terms of the overall mean squared error, and we discuss the differences between the methods.
Bid Prediction in Repeated Auctions with Learning
Jul 26, 2020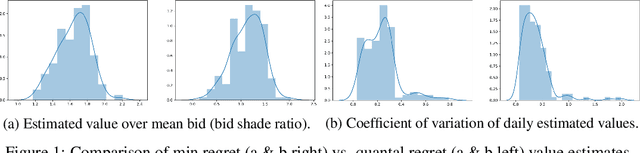
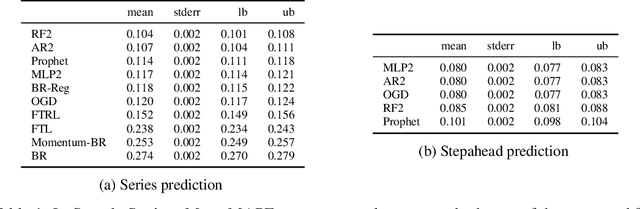
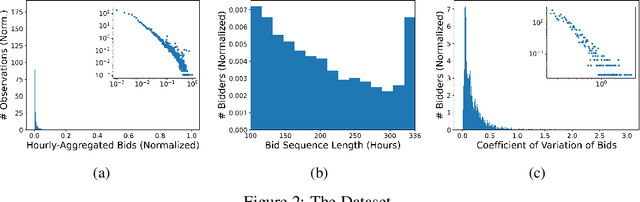
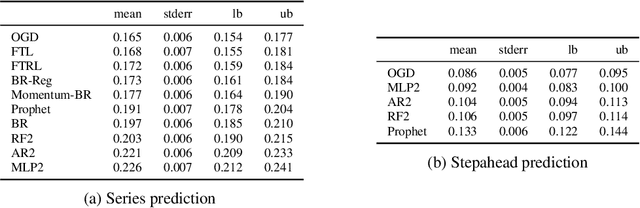
We consider the problem of bid prediction in repeated auctions and evaluate the performance of econometric methods for learning agents using a dataset from a mainstream sponsored search auction marketplace. Sponsored search auctions is a billion dollar industry and the main source of revenue of several tech giants. A critical problem in optimizing such marketplaces is understanding how bidders will react to changes in the auction design. We propose the use of no-regret based econometrics for bid prediction, modelling players as no-regret learners with respect to a utility function, unknown to the analyst. We apply these methods in a real-world dataset from the BingAds sponsored search auction marketplace and show that no-regret econometric methods perform comparable to state-of-the-art time-series machine learning methods when there is no co-variate shift, but significantly out-perform machine learning methods when there is a co-variate shift between the training and test periods. This portrays the importance of using structural econometric approaches in predicting how players will respond to changes in the market. Moreover, we show that among structural econometric methods, approaches based on no-regret learning out-perform more traditional, equilibrium-based, econometric methods that assume that players continuously best-respond to competition.
Neural Networks for Predicting Human Interactions in Repeated Games
Nov 08, 2019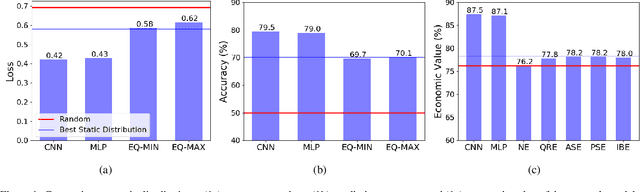
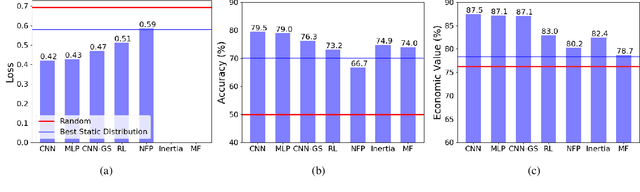
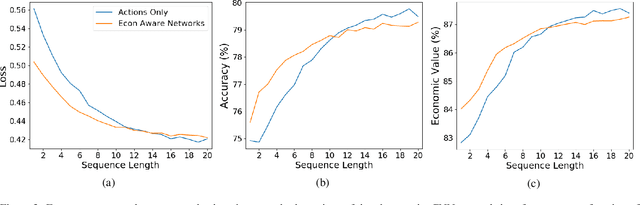
We consider the problem of predicting human players' actions in repeated strategic interactions. Our goal is to predict the dynamic step-by-step behavior of individual players in previously unseen games. We study the ability of neural networks to perform such predictions and the information that they require. We show on a dataset of normal-form games from experiments with human participants that standard neural networks are able to learn functions that provide more accurate predictions of the players' actions than established models from behavioral economics. The networks outperform the other models in terms of prediction accuracy and cross-entropy, and yield higher economic value. We show that if the available input is only of a short sequence of play, economic information about the game is important for predicting behavior of human agents. However, interestingly, we find that when the networks are trained with long enough sequences of history of play, action-based networks do well and additional economic details about the game do not improve their performance, indicating that the sequence of actions encode sufficient information for the success in the prediction task.
Behavior-Based Machine-Learning: A Hybrid Approach for Predicting Human Decision Making
Nov 30, 2016A large body of work in behavioral fields attempts to develop models that describe the way people, as opposed to rational agents, make decisions. A recent Choice Prediction Competition (2015) challenged researchers to suggest a model that captures 14 classic choice biases and can predict human decisions under risk and ambiguity. The competition focused on simple decision problems, in which human subjects were asked to repeatedly choose between two gamble options. In this paper we present our approach for predicting human decision behavior: we suggest to use machine learning algorithms with features that are based on well-established behavioral theories. The basic idea is that these psychological features are essential for the representation of the data and are important for the success of the learning process. We implement a vanilla model in which we train SVM models using behavioral features that rely on the psychological properties underlying the competition baseline model. We show that this basic model captures the 14 choice biases and outperforms all the other learning-based models in the competition. The preliminary results suggest that such hybrid models can significantly improve the prediction of human decision making, and are a promising direction for future research.