 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotivation in Large Language Models
Mar 15, 2026Motivation is a central driver of human behavior, shaping decisions, goals, and task performance. As large language models (LLMs) become increasingly aligned with human preferences, we ask whether they exhibit something akin to motivation. We examine whether LLMs "report" varying levels of motivation, how these reports relate to their behavior, and whether external factors can influence them. Our experiments reveal consistent and structured patterns that echo human psychology: self-reported motivation aligns with different behavioral signatures, varies across task types, and can be modulated by external manipulations. These findings demonstrate that motivation is a coherent organizing construct for LLM behavior, systematically linking reports, choices, effort, and performance, and revealing motivational dynamics that resemble those documented in human psychology. This perspective deepens our understanding of model behavior and its connection to human-inspired concepts.
Are LLMs Better than Reported? Detecting Label Errors and Mitigating Their Effect on Model Performance
Oct 24, 2024



NLP benchmarks rely on standardized datasets for training and evaluating models and are crucial for advancing the field. Traditionally, expert annotations ensure high-quality labels; however, the cost of expert annotation does not scale well with the growing demand for larger datasets required by modern models. While crowd-sourcing provides a more scalable solution, it often comes at the expense of annotation precision and consistency. Recent advancements in large language models (LLMs) offer new opportunities to enhance the annotation process, particularly for detecting label errors in existing datasets. In this work, we consider the recent approach of LLM-as-a-judge, leveraging an ensemble of LLMs to flag potentially mislabeled examples. Through a case study of four datasets from the TRUE benchmark, covering different tasks and domains, we empirically analyze the labeling quality of existing datasets, and compare expert, crowd-sourced, and our LLM-based annotations in terms of agreement, label quality, and efficiency, demonstrating the strengths and limitations of each annotation method. Our findings reveal a substantial number of label errors, which, when corrected, induce a significant upward shift in reported model performance. This suggests that many of the LLMs so-called mistakes are due to label errors rather than genuine model failures. Additionally, we discuss the implications of mislabeled data and propose methods to mitigate them in training to improve model performance.
Decongestion by Representation: Learning to Improve Economic Welfare in Marketplaces
Jun 18, 2023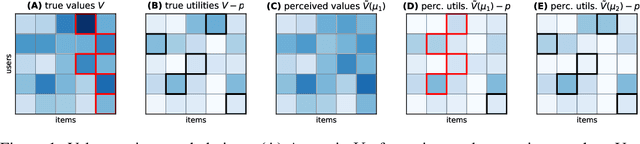
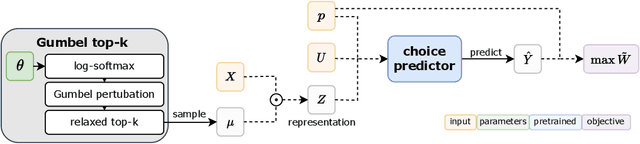
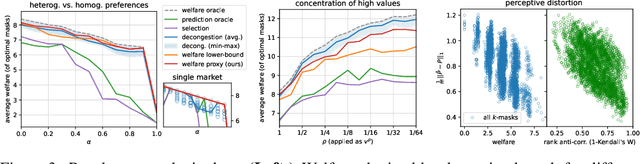
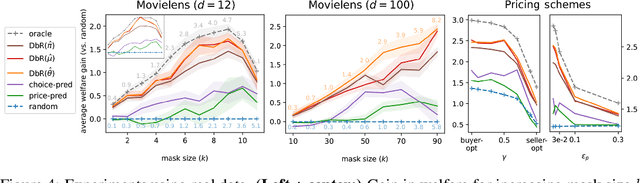
Congestion is a common failure mode of markets, where consumers compete inefficiently on the same subset of goods (e.g., chasing the same small set of properties on a vacation rental platform). The typical economic story is that prices solve this problem by balancing supply and demand in order to decongest the market. But in modern online marketplaces, prices are typically set in a decentralized way by sellers, with the power of a platform limited to controlling representations -- the information made available about products. This motivates the present study of decongestion by representation, where a platform uses this power to learn representations that improve social welfare by reducing congestion. The technical challenge is twofold: relying only on revealed preferences from users' past choices, rather than true valuations; and working with representations that determine which features to reveal and are inherently combinatorial. We tackle both by proposing a differentiable proxy of welfare that can be trained end-to-end on consumer choice data. We provide theory giving sufficient conditions for when decongestion promotes welfare, and present experiments on both synthetic and real data shedding light on our setting and approach.