 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerated Preference Elicitation with LLM-Based Proxies
Jan 24, 2025Bidders in combinatorial auctions face significant challenges when describing their preferences to an auctioneer. Classical work on preference elicitation focuses on query-based techniques inspired from proper learning--often via proxies that interface between bidders and an auction mechanism--to incrementally learn bidder preferences as needed to compute efficient allocations. Although such elicitation mechanisms enjoy theoretical query efficiency, the amount of communication required may still be too cognitively taxing in practice. We propose a family of efficient LLM-based proxy designs for eliciting preferences from bidders using natural language. Our proposed mechanism combines LLM pipelines and DNF-proper-learning techniques to quickly approximate preferences when communication is limited. To validate our approach, we create a testing sandbox for elicitation mechanisms that communicate in natural language. In our experiments, our most promising LLM proxy design reaches approximately efficient outcomes with five times fewer queries than classical proper learning based elicitation mechanisms.
Decongestion by Representation: Learning to Improve Economic Welfare in Marketplaces
Jun 18, 2023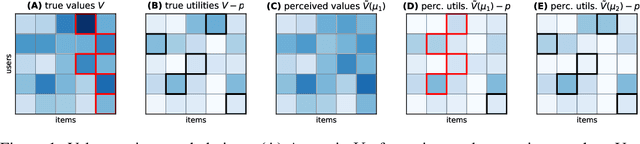
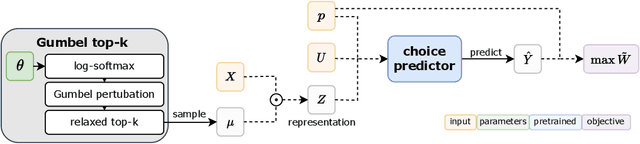
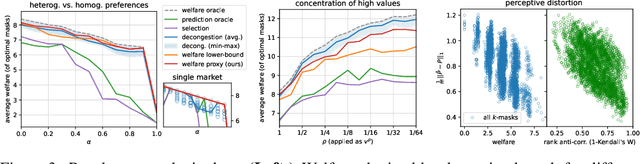
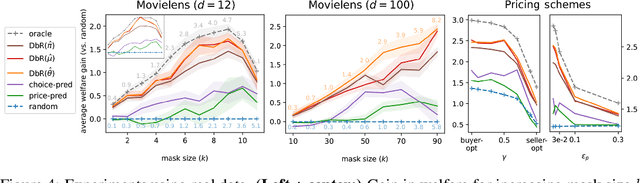
Congestion is a common failure mode of markets, where consumers compete inefficiently on the same subset of goods (e.g., chasing the same small set of properties on a vacation rental platform). The typical economic story is that prices solve this problem by balancing supply and demand in order to decongest the market. But in modern online marketplaces, prices are typically set in a decentralized way by sellers, with the power of a platform limited to controlling representations -- the information made available about products. This motivates the present study of decongestion by representation, where a platform uses this power to learn representations that improve social welfare by reducing congestion. The technical challenge is twofold: relying only on revealed preferences from users' past choices, rather than true valuations; and working with representations that determine which features to reveal and are inherently combinatorial. We tackle both by proposing a differentiable proxy of welfare that can be trained end-to-end on consumer choice data. We provide theory giving sufficient conditions for when decongestion promotes welfare, and present experiments on both synthetic and real data shedding light on our setting and approach.
Artificial Intelligence and Life in 2030: The One Hundred Year Study on Artificial Intelligence
Oct 31, 2022In September 2016, Stanford's "One Hundred Year Study on Artificial Intelligence" project (AI100) issued the first report of its planned long-term periodic assessment of artificial intelligence (AI) and its impact on society. It was written by a panel of 17 study authors, each of whom is deeply rooted in AI research, chaired by Peter Stone of the University of Texas at Austin. The report, entitled "Artificial Intelligence and Life in 2030," examines eight domains of typical urban settings on which AI is likely to have impact over the coming years: transportation, home and service robots, healthcare, education, public safety and security, low-resource communities, employment and workplace, and entertainment. It aims to provide the general public with a scientifically and technologically accurate portrayal of the current state of AI and its potential and to help guide decisions in industry and governments, as well as to inform research and development in the field. The charge for this report was given to the panel by the AI100 Standing Committee, chaired by Barbara Grosz of Harvard University.
The Rise of AI-Driven Simulators: Building a New Crystal Ball
Dec 11, 2020The use of computational simulation is by now so pervasive in society that it is no exaggeration to say that continued U.S. and international prosperity, security, and health depend in part on continued improvements in simulation capabilities. What if we could predict weather two weeks out, guide the design of new drugs for new viral diseases, or manage new manufacturing processes that cut production costs and times by an order of magnitude? What if we could predict collective human behavior, for example, response to an evacuation request during a natural disaster, or labor response to fiscal stimulus? (See also the companion CCC Quad Paper on Pandemic Informatics, which discusses features that would be essential to solving large-scale problems like preparation for, and response to, the inevitable next pandemic.) The past decade has brought remarkable advances in complementary areas: in sensors, which can now capture enormous amounts of data about the world, and in AI methods capable of learning to extract predictive patterns from those data. These advances may lead to a new era in computational simulation, in which sensors of many kinds are used to produce vast quantities of data, AI methods identify patterns in those data, and new AI-driven simulators combine machine-learned and mathematical rules to make accurate and actionable predictions. At the same time, there are new challenges -- computers in some important regards are no longer getting faster, and in some areas we are reaching the limits of mathematical understanding, or at least of our ability to translate mathematical understanding into efficient simulation. In this paper, we lay out some themes that we envision forming part of a cohesive, multi-disciplinary, and application-inspired research agenda on AI-driven simulators.
Artificial Intelligence & Cooperation
Dec 10, 2020The rise of Artificial Intelligence (AI) will bring with it an ever-increasing willingness to cede decision-making to machines. But rather than just giving machines the power to make decisions that affect us, we need ways to work cooperatively with AI systems. There is a vital need for research in "AI and Cooperation" that seeks to understand the ways in which systems of AIs and systems of AIs with people can engender cooperative behavior. Trust in AI is also key: trust that is intrinsic and trust that can only be earned over time. Here we use the term "AI" in its broadest sense, as employed by the recent 20-Year Community Roadmap for AI Research (Gil and Selman, 2019), including but certainly not limited to, recent advances in deep learning. With success, cooperation between humans and AIs can build society just as human-human cooperation has. Whether coming from an intrinsic willingness to be helpful, or driven through self-interest, human societies have grown strong and the human species has found success through cooperation. We cooperate "in the small" -- as family units, with neighbors, with co-workers, with strangers -- and "in the large" as a global community that seeks cooperative outcomes around questions of commerce, climate change, and disarmament. Cooperation has evolved in nature also, in cells and among animals. While many cases involving cooperation between humans and AIs will be asymmetric, with the human ultimately in control, AI systems are growing so complex that, even today, it is impossible for the human to fully comprehend their reasoning, recommendations, and actions when functioning simply as passive observers.
Weighted Tensor Completion for Time-Series Causal Inference
Feb 14, 2019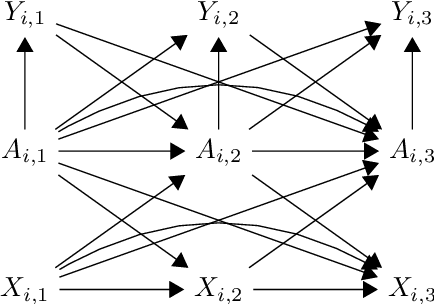
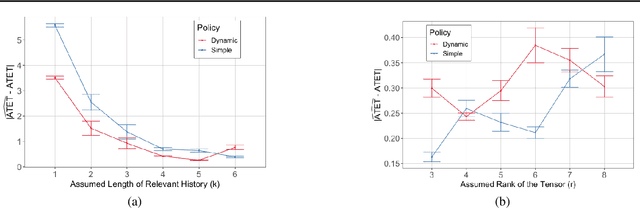
Marginal Structural Models (MSM) {Robins, 2000} are the most popular models for causal inference from time-series observational data. However, they have two main drawbacks: (a) they do not capture subject heterogeneity, and (b) they only consider fixed time intervals and do not scale gracefully with longer intervals. In this work, we propose a new family of MSMs to address these two concerns. We model the potential outcomes as a three-dimensional tensor of low rank, where the three dimensions correspond to the agents, time periods and the set of possible histories. Unlike the traditional MSM, we allow the dimensions of the tensor to increase with the number of agents and time periods. We set up a weighted tensor completion problem as our estimation procedure, and show that the solution to this problem converges to the true model in an appropriate sense. Then we show how to solve the estimation problem, providing conditions under which we can approximately and efficiently solve the estimation problem. Finally, we propose an algorithm based on projected gradient descent, which is easy to implement and evaluate its performance on a simulated dataset.
Learning to Collaborate in Markov Decision Processes
Jan 23, 2019We consider a two-agent MDP framework where agents repeatedly solve a task in a collaborative setting. We study the problem of designing a learning algorithm for the first agent (A1) that facilitates a successful collaboration even in cases when the second agent (A2) is adapting its policy in an unknown way. The key challenge in our setting is that the presence of the second agent leads to non-stationarity and non-obliviousness of rewards and transitions for the first agent. We design novel online learning algorithms for agent A1 whose regret decays as $O(T^{1-\frac{3}{7} \cdot \alpha})$ with $T$ learning episodes provided that the magnitude of agent A2's policy changes between any two consecutive episodes are upper bounded by $O(T^{-\alpha})$. Here, the parameter $\alpha$ is assumed to be strictly greater than $0$, and we show that this assumption is necessary provided that the {\em learning parity with noise} problem is computationally hard. We show that sub-linear regret of agent A1 further implies near-optimality of the agents' joint return for MDPs that manifest the properties of a {\em smooth} game.
How Do Fairness Definitions Fare? Examining Public Attitudes Towards Algorithmic Definitions of Fairness
Nov 08, 2018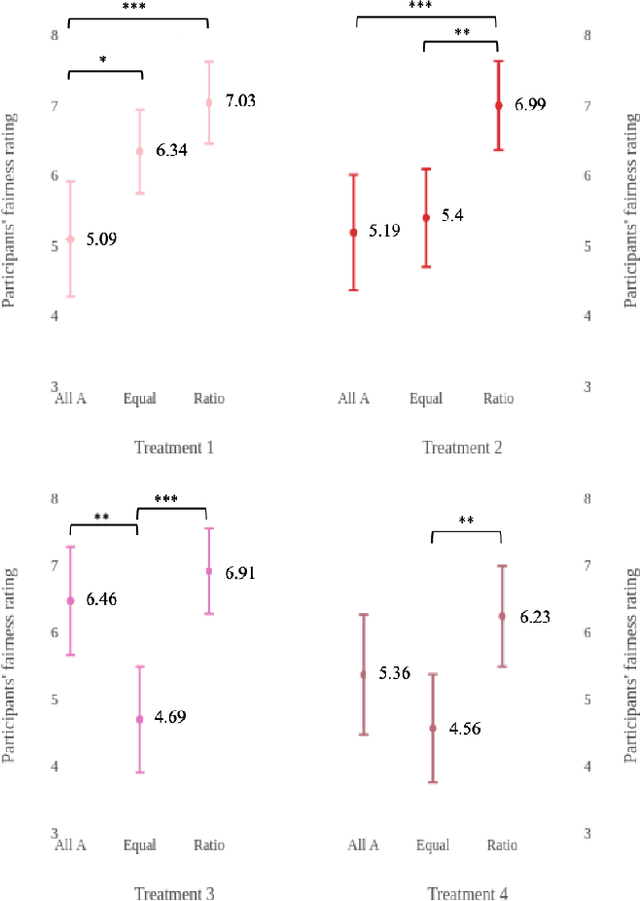
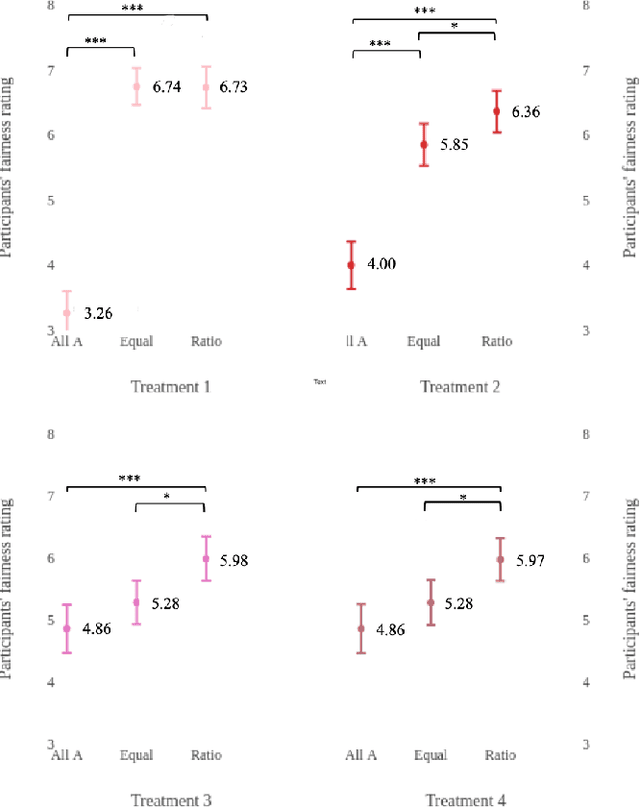
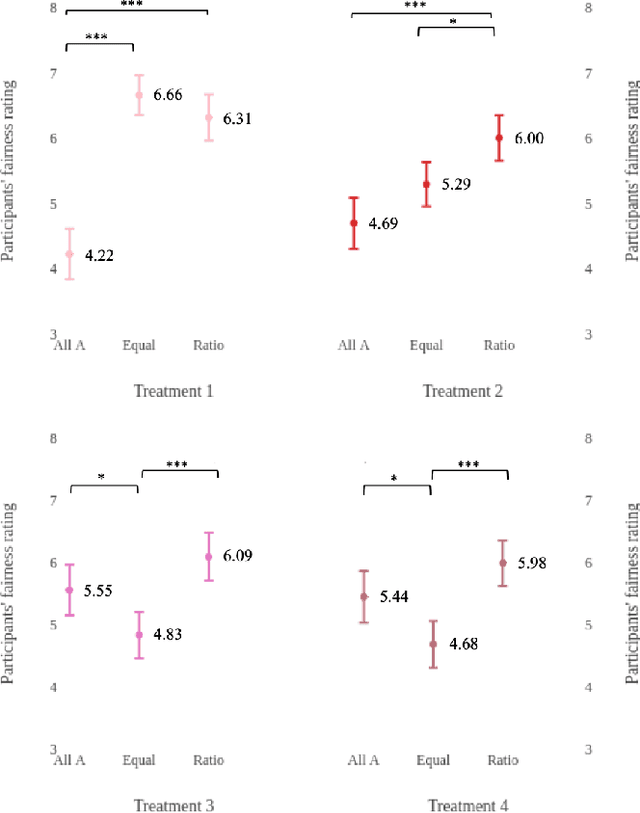

What is the best way to define algorithmic fairness? There has been much recent debate on algorithmic fairness. While many definitions of fairness have been proposed in the computer science literature, there is no clear agreement over a particular definition. In this work, we investigate ordinary people's perceptions of three of these fairness definitions. Across two online experiments, we test which definitions people perceive to be the fairest in the context of loan decisions, and whether those fairness perceptions change with the addition of sensitive information (i.e., race of the loan applicants). We find a clear preference for one definition, and the general results seem to align with the principle of affirmative action.
Bayesian fairness
Nov 04, 2018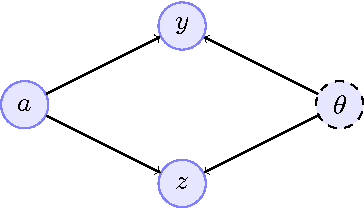
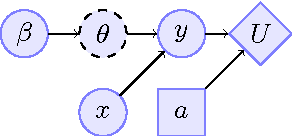
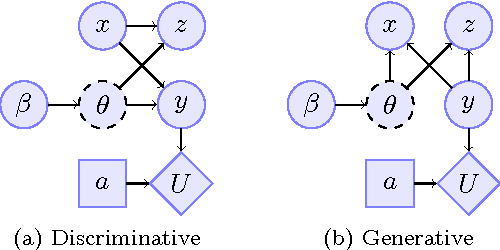
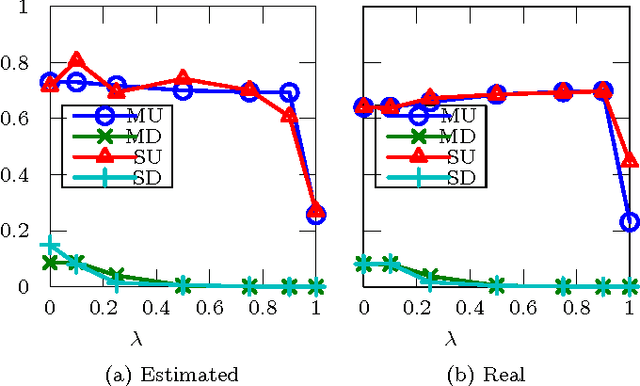
We consider the problem of how decision making can be fair when the underlying probabilistic model of the world is not known with certainty. We argue that recent notions of fairness in machine learning need to explicitly incorporate parameter uncertainty, hence we introduce the notion of {\em Bayesian fairness} as a suitable candidate for fair decision rules. Using balance, a definition of fairness introduced by Kleinberg et al (2016), we show how a Bayesian perspective can lead to well-performing, fair decision rules even under high uncertainty.
Fair Division via Social Comparison
Feb 25, 2018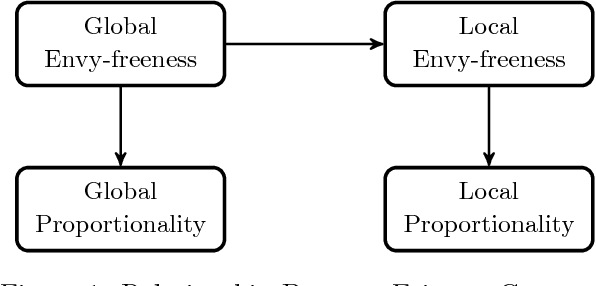

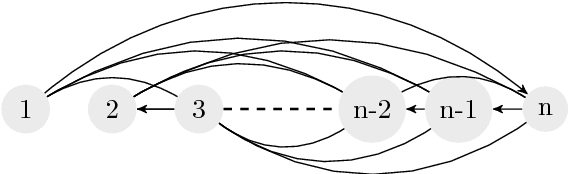
In the classical cake cutting problem, a resource must be divided among agents with different utilities so that each agent believes they have received a fair share of the resource relative to the other agents. We introduce a variant of the problem in which we model an underlying social network on the agents with a graph, and agents only evaluate their shares relative to their neighbors' in the network. This formulation captures many situations in which it is unrealistic to assume a global view, and also exposes interesting phenomena in the original problem. Specifically, we say an allocation is locally envy-free if no agent envies a neighbor's allocation and locally proportional if each agent values her own allocation as much as the average value of her neighbor's allocations, with the former implying the latter. While global envy-freeness implies local envy-freeness, global proportionality does not imply local proportionality, or vice versa. A general result is that for any two distinct graphs on the same set of nodes and an allocation, there exists a set of valuation functions such that the allocation is locally proportional on one but not the other. We fully characterize the set of graphs for which an oblivious single-cutter protocol-- a protocol that uses a single agent to cut the cake into pieces --admits a bounded protocol with $O(n^2)$ query complexity for locally envy-free allocations in the Robertson-Webb model. We also consider the price of envy-freeness, which compares the total utility of an optimal allocation to the best utility of an allocation that is envy-free. We show that a lower bound of $\Omega(\sqrt{n})$ on the price of envy-freeness for global allocations in fact holds for local envy-freeness in any connected undirected graph. Thus, sparse graphs surprisingly do not provide more flexibility with respect to the quality of envy-free allocations.