 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategic Classification with Non-Linear Classifiers
May 29, 2025



In strategic classification, the standard supervised learning setting is extended to support the notion of strategic user behavior in the form of costly feature manipulations made in response to a classifier. While standard learning supports a broad range of model classes, the study of strategic classification has, so far, been dedicated mostly to linear classifiers. This work aims to expand the horizon by exploring how strategic behavior manifests under non-linear classifiers and what this implies for learning. We take a bottom-up approach showing how non-linearity affects decision boundary points, classifier expressivity, and model classes complexity. A key finding is that universal approximators (e.g., neural nets) are no longer universal once the environment is strategic. We demonstrate empirically how this can create performance gaps even on an unrestricted model class.
Evolutionary Prediction Games
Mar 05, 2025

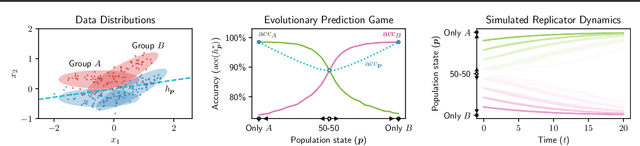
When users decide whether to use a system based on the quality of predictions they receive, learning has the capacity to shape the population of users it serves - for better or worse. This work aims to study the long-term implications of this process through the lens of evolutionary game theory. We introduce and study evolutionary prediction games, designed to capture the role of learning as a driver of natural selection between groups of users, and hence a determinant of evolutionary outcomes. Our main theoretical results show that: (i) in settings with unlimited data and compute, learning tends to reinforce the survival of the fittest, and (ii) in more realistic settings, opportunities for coexistence emerge. We analyze these opportunities in terms of their stability and feasibility, present several mechanisms that can sustain their existence, and empirically demonstrate our findings using real and synthetic data.
Learning Classifiers That Induce Markets
Feb 27, 2025


When learning is used to inform decisions about humans, such as for loans, hiring, or admissions, this can incentivize users to strategically modify their features to obtain positive predictions. A key assumption is that modifications are costly, and are governed by a cost function that is exogenous and predetermined. We challenge this assumption, and assert that the deployment of a classifier is what creates costs. Our idea is simple: when users seek positive predictions, this creates demand for important features; and if features are available for purchase, then a market will form, and competition will give rise to prices. We extend the strategic classification framework to support this notion, and study learning in a setting where a classifier can induce a market for features. We present an analysis of the learning task, devise an algorithm for computing market prices, propose a differentiable learning framework, and conduct experiments to explore our novel setting and approach.
A Market for Accuracy: Classification under Competition
Feb 25, 2025
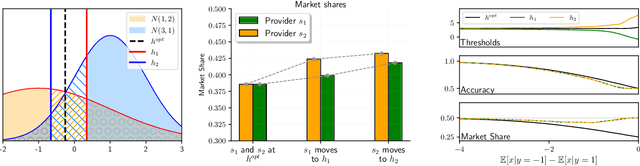

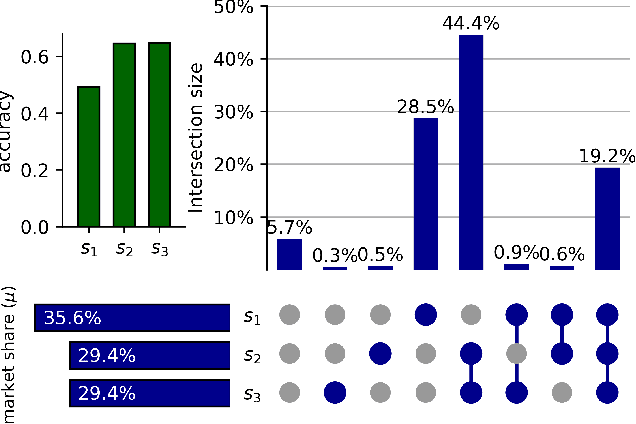
Machine learning models play a key role for service providers looking to gain market share in consumer markets. However, traditional learning approaches do not take into account the existence of additional providers, who compete with each other for consumers. Our work aims to study learning in this market setting, as it affects providers, consumers, and the market itself. We begin by analyzing such markets through the lens of the learning objective, and show that accuracy cannot be the only consideration. We then propose a method for classification under competition, so that a learner can maximize market share in the presence of competitors. We show that our approach benefits the providers as well as the consumers, and find that the timing of market entry and model updates can be crucial. We display the effectiveness of our approach across a range of domains, from simple distributions to noisy datasets, and show that the market as a whole remains stable by converging quickly to an equilibrium.
Machine Learning Should Maximize Welfare, Not (Only) Accuracy
Feb 17, 2025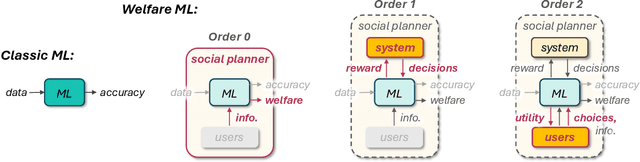
Decades of research in machine learning have given us powerful tools for making accurate predictions. But when used in social settings and on human inputs, better accuracy does not immediately translate to better social outcomes. This may not be surprising given that conventional learning frameworks are not designed to express societal preferences -- let alone promote them. This position paper argues that machine learning is currently missing, and can gain much from incorporating, a proper notion of social welfare. The field of welfare economics asks: how should we allocate limited resources to self-interested agents in a way that maximizes social benefit? We argue that this perspective applies to many modern applications of machine learning in social contexts, and advocate for its adoption. Rather than disposing of prediction, we aim to leverage this forte of machine learning for promoting social welfare. We demonstrate this idea by proposing a conceptual framework that gradually transitions from accuracy maximization (with awareness to welfare) to welfare maximization (via accurate prediction). We detail applications and use-cases for which our framework can be effective, identify technical challenges and practical opportunities, and highlight future avenues worth pursuing.
Adversaries With Incentives: A Strategic Alternative to Adversarial Robustness
Jun 17, 2024Adversarial training aims to defend against *adversaries*: malicious opponents whose sole aim is to harm predictive performance in any way possible - a rather harsh perspective, which we assert results in unnecessarily conservative models. Instead, we propose to model opponents as simply pursuing their own goals, rather than working directly against the classifier. Employing tools from strategic modeling, our approach uses knowledge or beliefs regarding the opponent's possible incentives as inductive bias for learning. Our method of *strategic training* is designed to defend against opponents within an *incentive uncertainty set*: this resorts to adversarial learning when the set is maximal, but offers potential gains when it can be appropriately reduced. We conduct a series of experiments that show how even mild knowledge regarding the adversary's incentives can be useful, and that the degree of potential gains depends on how incentives relate to the structure of the learning task.
Classification Under Strategic Self-Selection
Feb 23, 2024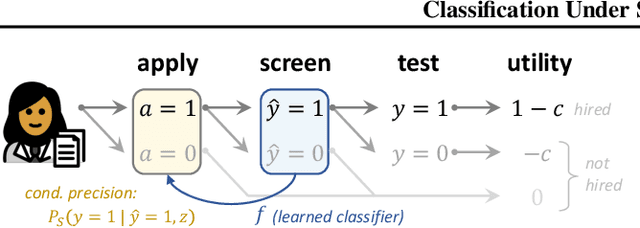

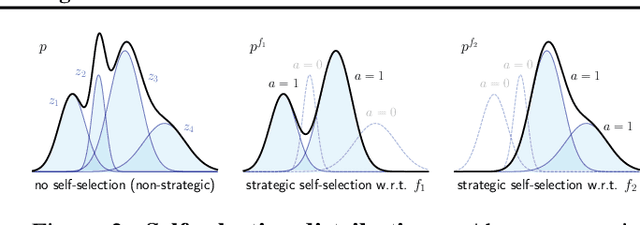
When users stand to gain from certain predictions, they are prone to act strategically to obtain favorable predictive outcomes. Whereas most works on strategic classification consider user actions that manifest as feature modifications, we study a novel setting in which users decide -- in response to the learned classifier -- whether to at all participate (or not). For learning approaches of increasing strategic awareness, we study the effects of self-selection on learning, and the implications of learning on the composition of the self-selected population. We then propose a differentiable framework for learning under self-selective behavior, which can be optimized effectively. We conclude with experiments on real data and simulated behavior that both complement our analysis and demonstrate the utility of our approach.
One-Shot Strategic Classification Under Unknown Costs
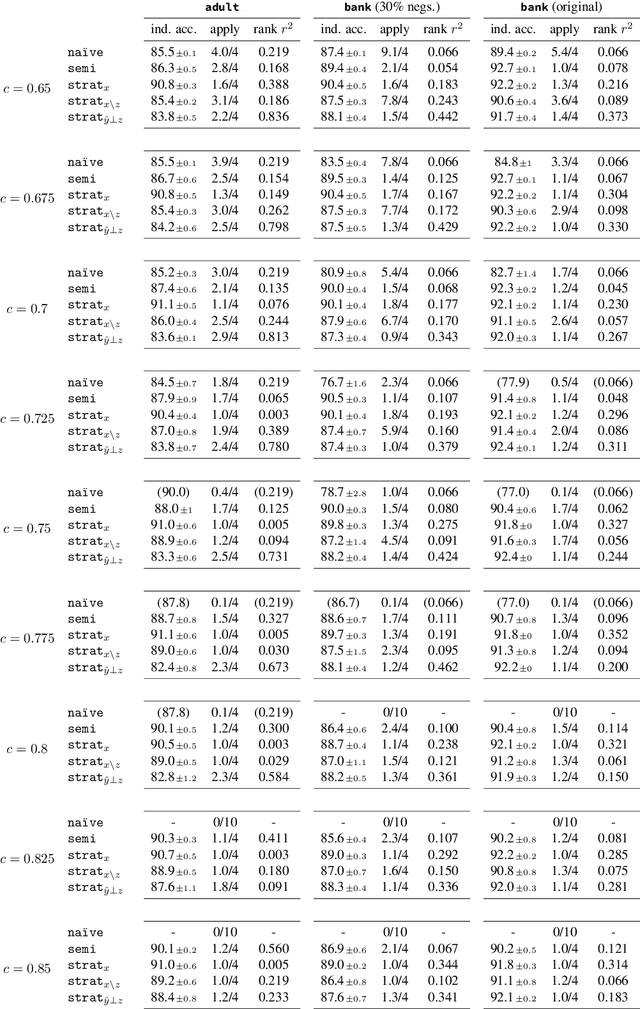
Nov 05, 2023A primary goal in strategic classification is to learn decision rules which are robust to strategic input manipulation. Earlier works assume that strategic responses are known; while some recent works address the important challenge of unknown responses, they exclusively study sequential settings which allow multiple model deployments over time. But there are many domains$\unicode{x2014}$particularly in public policy, a common motivating use-case$\unicode{x2014}$where multiple deployments are unrealistic, or where even a single bad round is undesirable. To address this gap, we initiate the study of strategic classification under unknown responses in the one-shot setting, which requires committing to a single classifier once. Focusing on the users' cost function as the source of uncertainty, we begin by proving that for a broad class of costs, even a small mis-estimation of the true cost can entail arbitrarily low accuracy in the worst case. In light of this, we frame the one-shot task as a minimax problem, with the goal of identifying the classifier with the smallest worst-case risk over an uncertainty set of possible costs. Our main contribution is efficient algorithms for both the full-batch and stochastic settings, which we prove converge (offline) to the minimax optimal solution at the dimension-independent rate of $\tilde{\mathcal{O}}(T^{-\frac{1}{2}})$. Our analysis reveals important structure stemming from the strategic nature of user responses, particularly the importance of dual norm regularization with respect to the cost function.
Instructed to Bias: Instruction-Tuned Language Models Exhibit Emergent Cognitive Bias
Aug 01, 2023Recent studies show that instruction tuning and learning from human feedback improve the abilities of large language models (LMs) dramatically. While these tuning methods can make models generate high-quality text, we conjecture that more implicit cognitive biases may arise in these fine-tuned models. Our work provides evidence that these fine-tuned models exhibit biases that were absent or less pronounced in their pretrained predecessors. We examine the extent of this phenomenon in three cognitive biases - the decoy effect, the certainty effect, and the belief bias - all of which are known to influence human decision-making and reasoning. Our findings highlight the presence of these biases in various models, especially those that have undergone instruction tuning, such as Flan-T5, GPT3.5, and GPT4. This research constitutes a step toward comprehending cognitive biases in instruction-tuned LMs, which is crucial for the development of more reliable and unbiased language models.
Delegated Classification
Jun 20, 2023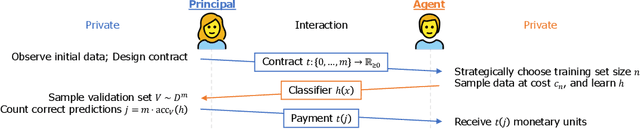

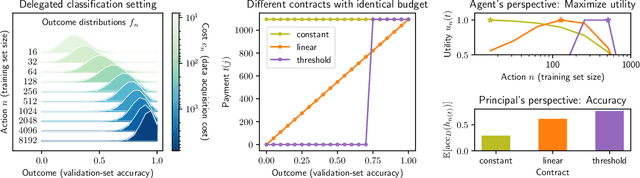
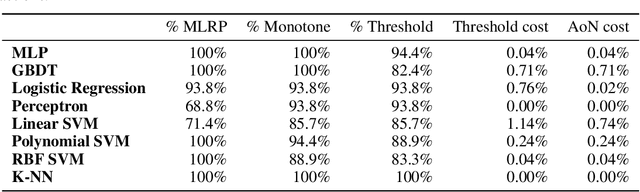
When machine learning is outsourced to a rational agent, conflicts of interest might arise and severely impact predictive performance. In this work, we propose a theoretical framework for incentive-aware delegation of machine learning tasks. We model delegation as a principal-agent game, in which accurate learning can be incentivized by the principal using performance-based contracts. Adapting the economic theory of contract design to this setting, we define budget-optimal contracts and prove they take a simple threshold form under reasonable assumptions. In the binary-action case, the optimality of such contracts is shown to be equivalent to the classic Neyman-Pearson lemma, establishing a formal connection between contract design and statistical hypothesis testing. Empirically, we demonstrate that budget-optimal contracts can be constructed using small-scale data, leveraging recent advances in the study of learning curves and scaling laws. Performance and economic outcomes are evaluated using synthetic and real-world classification tasks.