 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDREAM: Deep Research Evaluation with Agentic Metrics
Feb 21, 2026Deep Research Agents generate analyst-grade reports, yet evaluating them remains challenging due to the absence of a single ground truth and the multidimensional nature of research quality. Recent benchmarks propose distinct methodologies, yet they suffer from the Mirage of Synthesis, where strong surface-level fluency and citation alignment can obscure underlying factual and reasoning defects. We characterize this gap by introducing a taxonomy across four verticals that exposes a critical capability mismatch: static evaluators inherently lack the tool-use capabilities required to assess temporal validity and factual correctness. To address this, we propose DREAM (Deep Research Evaluation with Agentic Metrics), a framework that instantiates the principle of capability parity by making evaluation itself agentic. DREAM structures assessment through an evaluation protocol combining query-agnostic metrics with adaptive metrics generated by a tool-calling agent, enabling temporally aware coverage, grounded verification, and systematic reasoning probes. Controlled evaluations demonstrate DREAM is significantly more sensitive to factual and temporal decay than existing benchmarks, offering a scalable, reference-free evaluation paradigm.
DODO: Discrete OCR Diffusion Models
Feb 18, 2026Optical Character Recognition (OCR) is a fundamental task for digitizing information, serving as a critical bridge between visual data and textual understanding. While modern Vision-Language Models (VLM) have achieved high accuracy in this domain, they predominantly rely on autoregressive decoding, which becomes computationally expensive and slow for long documents as it requires a sequential forward pass for every generated token. We identify a key opportunity to overcome this bottleneck: unlike open-ended generation, OCR is a highly deterministic task where the visual input strictly dictates a unique output sequence, theoretically enabling efficient, parallel decoding via diffusion models. However, we show that existing masked diffusion models fail to harness this potential; those introduce structural instabilities that are benign in flexible tasks, like captioning, but catastrophic for the rigid, exact-match requirements of OCR. To bridge this gap, we introduce DODO, the first VLM to utilize block discrete diffusion and unlock its speedup potential for OCR. By decomposing generation into blocks, DODO mitigates the synchronization errors of global diffusion. Empirically, our method achieves near state-of-the-art accuracy while enabling up to 3x faster inference compared to autoregressive baselines.
DocVLM: Make Your VLM an Efficient Reader
Dec 11, 2024



Vision-Language Models (VLMs) excel in diverse visual tasks but face challenges in document understanding, which requires fine-grained text processing. While typical visual tasks perform well with low-resolution inputs, reading-intensive applications demand high-resolution, resulting in significant computational overhead. Using OCR-extracted text in VLM prompts partially addresses this issue but underperforms compared to full-resolution counterpart, as it lacks the complete visual context needed for optimal performance. We introduce DocVLM, a method that integrates an OCR-based modality into VLMs to enhance document processing while preserving original weights. Our approach employs an OCR encoder to capture textual content and layout, compressing these into a compact set of learned queries incorporated into the VLM. Comprehensive evaluations across leading VLMs show that DocVLM significantly reduces reliance on high-resolution images for document understanding. In limited-token regimes (448$\times$448), DocVLM with 64 learned queries improves DocVQA results from 56.0% to 86.6% when integrated with InternVL2 and from 84.4% to 91.2% with Qwen2-VL. In LLaVA-OneVision, DocVLM achieves improved results while using 80% less image tokens. The reduced token usage allows processing multiple pages effectively, showing impressive zero-shot results on DUDE and state-of-the-art performance on MP-DocVQA, highlighting DocVLM's potential for applications requiring high-performance and efficiency.
TAP-VL: Text Layout-Aware Pre-training for Enriched Vision-Language Models
Nov 07, 2024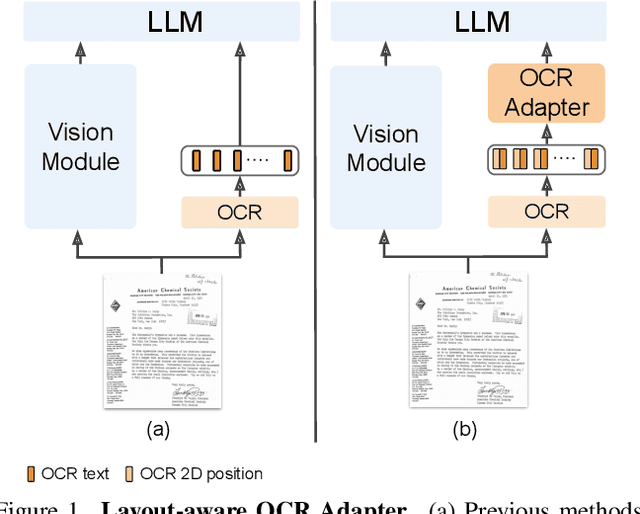
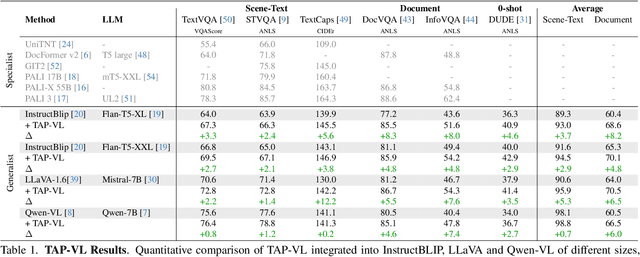
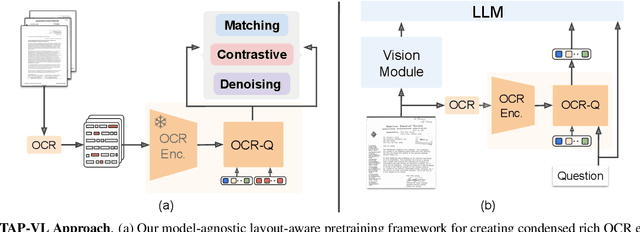
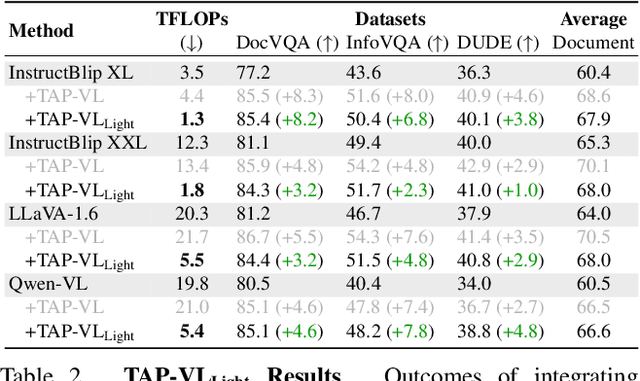
Vision-Language (VL) models have garnered considerable research interest; however, they still face challenges in effectively handling text within images. To address this limitation, researchers have developed two approaches. The first method involves utilizing external Optical Character Recognition (OCR) tools to extract textual information from images, which is then prepended to other textual inputs. The second strategy focuses on employing extremely high-resolution images to improve text recognition capabilities. In this paper, we focus on enhancing the first strategy by introducing a novel method, named TAP-VL, which treats OCR information as a distinct modality and seamlessly integrates it into any VL model. TAP-VL employs a lightweight transformer-based OCR module to receive OCR with layout information, compressing it into a short fixed-length sequence for input into the LLM. Initially, we conduct model-agnostic pretraining of the OCR module on unlabeled documents, followed by its integration into any VL architecture through brief fine-tuning. Extensive experiments demonstrate consistent performance improvements when applying TAP-VL to top-performing VL models, across scene-text and document-based VL benchmarks.
Text-to-Image Generation Via Energy-Based CLIP
Aug 30, 2024



Joint Energy Models (JEMs), while drawing significant research attention, have not been successfully scaled to real-world, high-resolution datasets. We present EB-CLIP, a novel approach extending JEMs to the multimodal vision-language domain using CLIP, integrating both generative and discriminative objectives. For the generative objective, we introduce an image-text joint-energy function based on Cosine similarity in the CLIP space, training CLIP to assign low energy to real image-caption pairs and high energy otherwise. For the discriminative objective, we employ contrastive adversarial loss, extending the adversarial training objective to the multimodal domain. EB-CLIP not only generates realistic images from text but also achieves competitive results on the compositionality benchmark, outperforming leading methods with fewer parameters. Additionally, we demonstrate the superior guidance capability of EB-CLIP by enhancing CLIP-based generative frameworks and converting unconditional diffusion models to text-based ones. Lastly, we show that EB-CLIP can serve as a more robust evaluation metric for text-to-image generative tasks than CLIP.
Adversaries With Incentives: A Strategic Alternative to Adversarial Robustness
Jun 17, 2024Adversarial training aims to defend against *adversaries*: malicious opponents whose sole aim is to harm predictive performance in any way possible - a rather harsh perspective, which we assert results in unnecessarily conservative models. Instead, we propose to model opponents as simply pursuing their own goals, rather than working directly against the classifier. Employing tools from strategic modeling, our approach uses knowledge or beliefs regarding the opponent's possible incentives as inductive bias for learning. Our method of *strategic training* is designed to defend against opponents within an *incentive uncertainty set*: this resorts to adversarial learning when the set is maximal, but offers potential gains when it can be appropriately reduced. We conduct a series of experiments that show how even mild knowledge regarding the adversary's incentives can be useful, and that the degree of potential gains depends on how incentives relate to the structure of the learning task.
Enhancing Consistency-Based Image Generation via Adversarialy-Trained Classification and Energy-Based Discrimination
May 25, 2024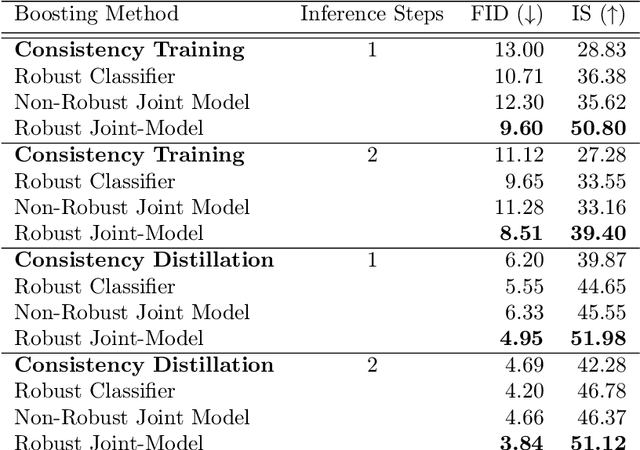

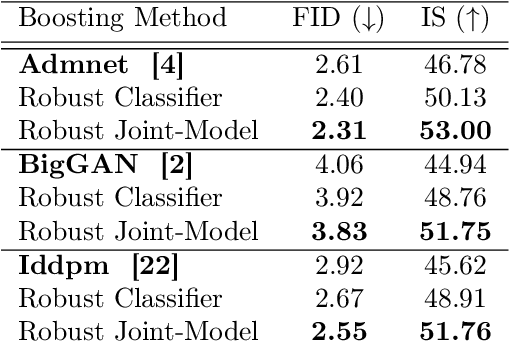
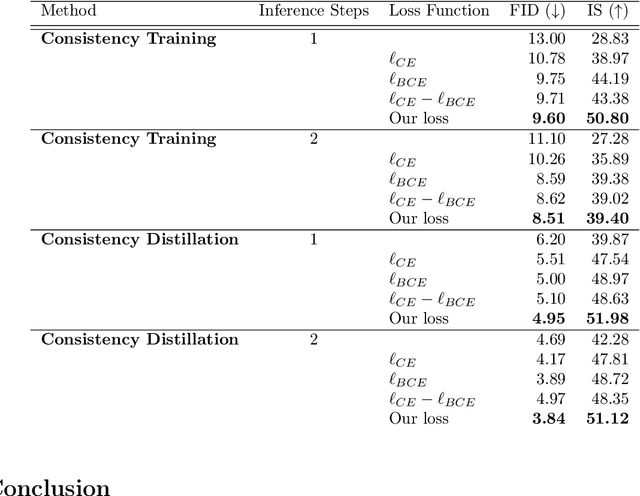
The recently introduced Consistency models pose an efficient alternative to diffusion algorithms, enabling rapid and good quality image synthesis. These methods overcome the slowness of diffusion models by directly mapping noise to data, while maintaining a (relatively) simpler training. Consistency models enable a fast one- or few-step generation, but they typically fall somewhat short in sample quality when compared to their diffusion origins. In this work we propose a novel and highly effective technique for post-processing Consistency-based generated images, enhancing their perceptual quality. Our approach utilizes a joint classifier-discriminator model, in which both portions are trained adversarially. While the classifier aims to grade an image based on its assignment to a designated class, the discriminator portion of the very same network leverages the softmax values to assess the proximity of the input image to the targeted data manifold, thereby serving as an Energy-based Model. By employing example-specific projected gradient iterations under the guidance of this joint machine, we refine synthesized images and achieve an improved FID scores on the ImageNet 64x64 dataset for both Consistency-Training and Consistency-Distillation techniques.
Paint by Inpaint: Learning to Add Image Objects by Removing Them First
Apr 28, 2024
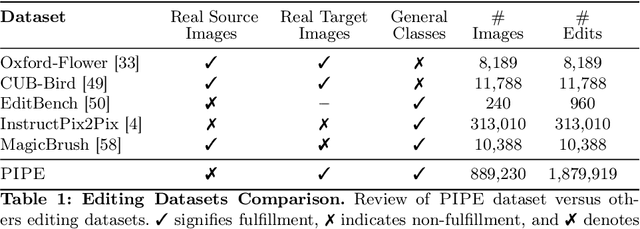

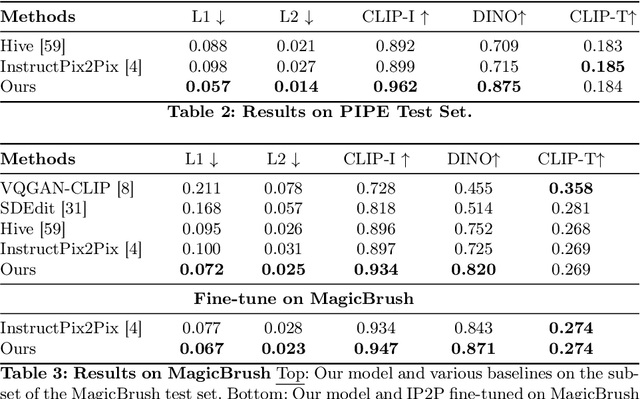
Image editing has advanced significantly with the introduction of text-conditioned diffusion models. Despite this progress, seamlessly adding objects to images based on textual instructions without requiring user-provided input masks remains a challenge. We address this by leveraging the insight that removing objects (Inpaint) is significantly simpler than its inverse process of adding them (Paint), attributed to the utilization of segmentation mask datasets alongside inpainting models that inpaint within these masks. Capitalizing on this realization, by implementing an automated and extensive pipeline, we curate a filtered large-scale image dataset containing pairs of images and their corresponding object-removed versions. Using these pairs, we train a diffusion model to inverse the inpainting process, effectively adding objects into images. Unlike other editing datasets, ours features natural target images instead of synthetic ones; moreover, it maintains consistency between source and target by construction. Additionally, we utilize a large Vision-Language Model to provide detailed descriptions of the removed objects and a Large Language Model to convert these descriptions into diverse, natural-language instructions. We show that the trained model surpasses existing ones both qualitatively and quantitatively, and release the large-scale dataset alongside the trained models for the community.
Question Aware Vision Transformer for Multimodal Reasoning
Feb 08, 2024


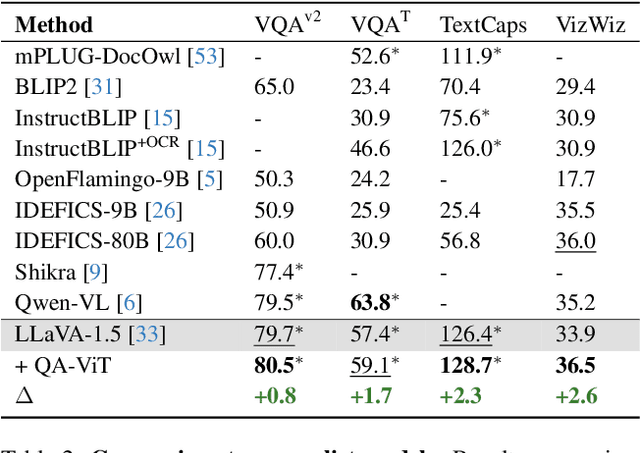
Vision-Language (VL) models have gained significant research focus, enabling remarkable advances in multimodal reasoning. These architectures typically comprise a vision encoder, a Large Language Model (LLM), and a projection module that aligns visual features with the LLM's representation space. Despite their success, a critical limitation persists: the vision encoding process remains decoupled from user queries, often in the form of image-related questions. Consequently, the resulting visual features may not be optimally attuned to the query-specific elements of the image. To address this, we introduce QA-ViT, a Question Aware Vision Transformer approach for multimodal reasoning, which embeds question awareness directly within the vision encoder. This integration results in dynamic visual features focusing on relevant image aspects to the posed question. QA-ViT is model-agnostic and can be incorporated efficiently into any VL architecture. Extensive experiments demonstrate the effectiveness of applying our method to various multimodal architectures, leading to consistent improvement across diverse tasks and showcasing its potential for enhancing visual and scene-text understanding.
GRAM: Global Reasoning for Multi-Page VQA
Jan 07, 2024


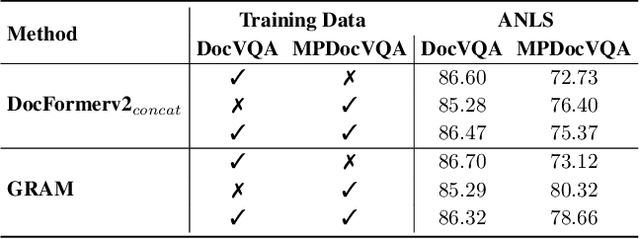
The increasing use of transformer-based large language models brings forward the challenge of processing long sequences. In document visual question answering (DocVQA), leading methods focus on the single-page setting, while documents can span hundreds of pages. We present GRAM, a method that seamlessly extends pre-trained single-page models to the multi-page setting, without requiring computationally-heavy pretraining. To do so, we leverage a single-page encoder for local page-level understanding, and enhance it with document-level designated layers and learnable tokens, facilitating the flow of information across pages for global reasoning. To enforce our model to utilize the newly introduced document-level tokens, we propose a tailored bias adaptation method. For additional computational savings during decoding, we introduce an optional compression stage using our C-Former model, which reduces the encoded sequence length, thereby allowing a tradeoff between quality and latency. Extensive experiments showcase GRAM's state-of-the-art performance on the benchmarks for multi-page DocVQA, demonstrating the effectiveness of our approach.