 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaricatureGS: Exaggerating 3D Gaussian Splatting Faces With Gaussian Curvature
Jan 06, 2026A photorealistic and controllable 3D caricaturization framework for faces is introduced. We start with an intrinsic Gaussian curvature-based surface exaggeration technique, which, when coupled with texture, tends to produce over-smoothed renders. To address this, we resort to 3D Gaussian Splatting (3DGS), which has recently been shown to produce realistic free-viewpoint avatars. Given a multiview sequence, we extract a FLAME mesh, solve a curvature-weighted Poisson equation, and obtain its exaggerated form. However, directly deforming the Gaussians yields poor results, necessitating the synthesis of pseudo-ground-truth caricature images by warping each frame to its exaggerated 2D representation using local affine transformations. We then devise a training scheme that alternates real and synthesized supervision, enabling a single Gaussian collection to represent both natural and exaggerated avatars. This scheme improves fidelity, supports local edits, and allows continuous control over the intensity of the caricature. In order to achieve real-time deformations, an efficient interpolation between the original and exaggerated surfaces is introduced. We further analyze and show that it has a bounded deviation from closed-form solutions. In both quantitative and qualitative evaluations, our results outperform prior work, delivering photorealistic, geometry-controlled caricature avatars.
Time-to-Move: Training-Free Motion Controlled Video Generation via Dual-Clock Denoising
Nov 09, 2025



Diffusion-based video generation can create realistic videos, yet existing image- and text-based conditioning fails to offer precise motion control. Prior methods for motion-conditioned synthesis typically require model-specific fine-tuning, which is computationally expensive and restrictive. We introduce Time-to-Move (TTM), a training-free, plug-and-play framework for motion- and appearance-controlled video generation with image-to-video (I2V) diffusion models. Our key insight is to use crude reference animations obtained through user-friendly manipulations such as cut-and-drag or depth-based reprojection. Motivated by SDEdit's use of coarse layout cues for image editing, we treat the crude animations as coarse motion cues and adapt the mechanism to the video domain. We preserve appearance with image conditioning and introduce dual-clock denoising, a region-dependent strategy that enforces strong alignment in motion-specified regions while allowing flexibility elsewhere, balancing fidelity to user intent with natural dynamics. This lightweight modification of the sampling process incurs no additional training or runtime cost and is compatible with any backbone. Extensive experiments on object and camera motion benchmarks show that TTM matches or exceeds existing training-based baselines in realism and motion control. Beyond this, TTM introduces a unique capability: precise appearance control through pixel-level conditioning, exceeding the limits of text-only prompting. Visit our project page for video examples and code: https://time-to-move.github.io/.
Pathways on the Image Manifold: Image Editing via Video Generation
Nov 25, 2024
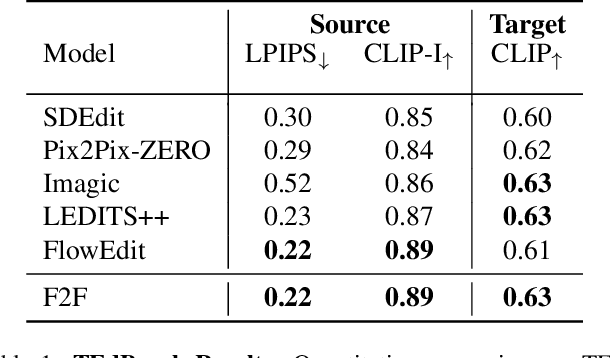
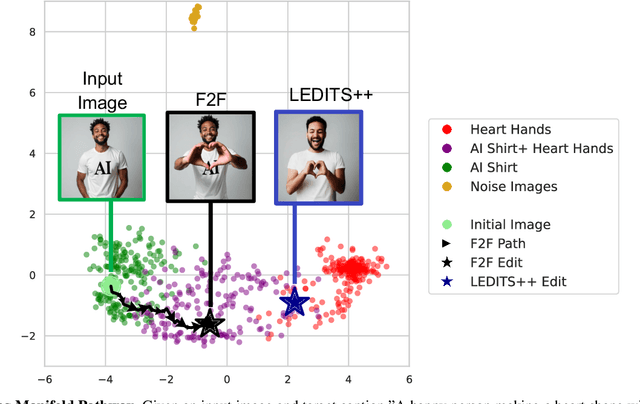
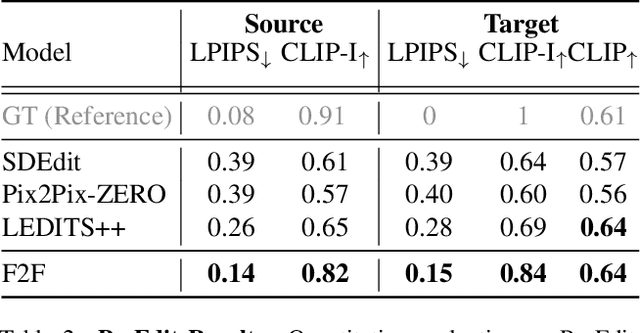
Recent advances in image editing, driven by image diffusion models, have shown remarkable progress. However, significant challenges remain, as these models often struggle to follow complex edit instructions accurately and frequently compromise fidelity by altering key elements of the original image. Simultaneously, video generation has made remarkable strides, with models that effectively function as consistent and continuous world simulators. In this paper, we propose merging these two fields by utilizing image-to-video models for image editing. We reformulate image editing as a temporal process, using pretrained video models to create smooth transitions from the original image to the desired edit. This approach traverses the image manifold continuously, ensuring consistent edits while preserving the original image's key aspects. Our approach achieves state-of-the-art results on text-based image editing, demonstrating significant improvements in both edit accuracy and image preservation.
Paint by Inpaint: Learning to Add Image Objects by Removing Them First
Apr 28, 2024
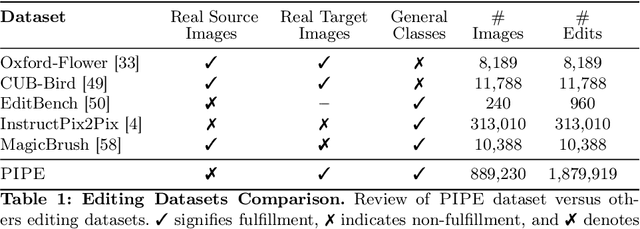

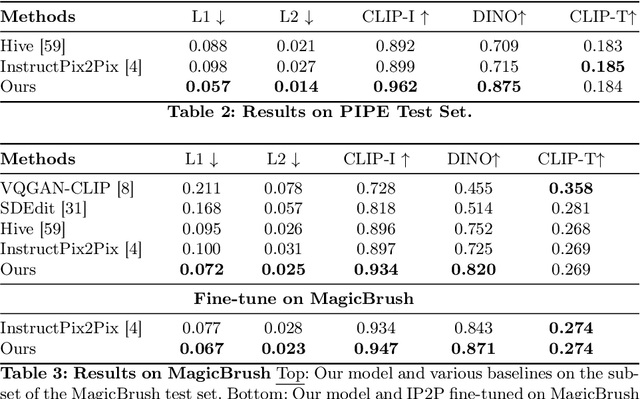
Image editing has advanced significantly with the introduction of text-conditioned diffusion models. Despite this progress, seamlessly adding objects to images based on textual instructions without requiring user-provided input masks remains a challenge. We address this by leveraging the insight that removing objects (Inpaint) is significantly simpler than its inverse process of adding them (Paint), attributed to the utilization of segmentation mask datasets alongside inpainting models that inpaint within these masks. Capitalizing on this realization, by implementing an automated and extensive pipeline, we curate a filtered large-scale image dataset containing pairs of images and their corresponding object-removed versions. Using these pairs, we train a diffusion model to inverse the inpainting process, effectively adding objects into images. Unlike other editing datasets, ours features natural target images instead of synthetic ones; moreover, it maintains consistency between source and target by construction. Additionally, we utilize a large Vision-Language Model to provide detailed descriptions of the removed objects and a Large Language Model to convert these descriptions into diverse, natural-language instructions. We show that the trained model surpasses existing ones both qualitatively and quantitatively, and release the large-scale dataset alongside the trained models for the community.
FuseCap: Leveraging Large Language Models to Fuse Visual Data into Enriched Image Captions
May 28, 2023Image captioning is a central task in computer vision which has experienced substantial progress following the advent of vision-language pre-training techniques. In this paper, we highlight a frequently overlooked limitation of captioning models that often fail to capture semantically significant elements. This drawback can be traced back to the text-image datasets; while their captions typically offer a general depiction of image content, they frequently omit salient details. To mitigate this limitation, we propose FuseCap - a novel method for enriching captions with additional visual information, obtained from vision experts, such as object detectors, attribute recognizers, and Optical Character Recognizers (OCR). Our approach fuses the outputs of such vision experts with the original caption using a large language model (LLM), yielding enriched captions that present a comprehensive image description. We validate the effectiveness of the proposed caption enrichment method through both quantitative and qualitative analysis. Our method is then used to curate the training set of a captioning model based BLIP which surpasses current state-of-the-art approaches in generating accurate and detailed captions while using significantly fewer parameters and training data. As additional contributions, we provide a dataset comprising of 12M image-enriched caption pairs and show that the proposed method largely improves image-text retrieval.
Depth Refinement for Improved Stereo Reconstruction
Dec 15, 2021

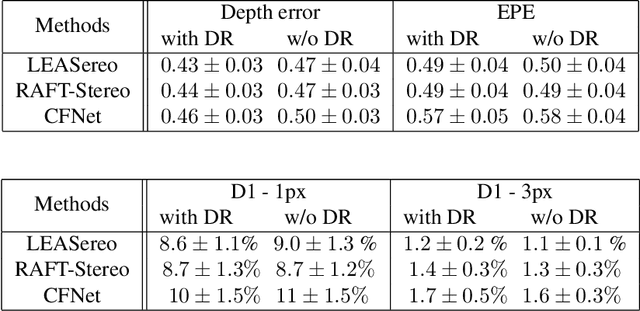
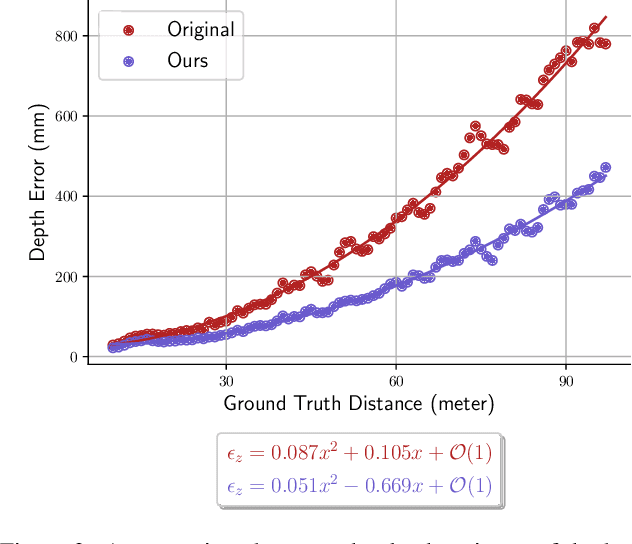
Depth estimation is a cornerstone of a vast number of applications requiring 3D assessment of the environment, such as robotics, augmented reality, and autonomous driving to name a few. One prominent technique for depth estimation is stereo matching which has several advantages: it is considered more accessible than other depth-sensing technologies, can produce dense depth estimates in real-time, and has benefited greatly from the advances of deep learning in recent years. However, current techniques for depth estimation from stereoscopic images still suffer from a built-in drawback. To reconstruct depth, a stereo matching algorithm first estimates the disparity map between the left and right images before applying a geometric triangulation. A simple analysis reveals that the depth error is quadratically proportional to the object's distance. Therefore, constant disparity errors are translated to large depth errors for objects far from the camera. To mitigate this quadratic relation, we propose a simple but effective method that uses a refinement network for depth estimation. We show analytical and empirical results suggesting that the proposed learning procedure reduces this quadratic relation. We evaluate the proposed refinement procedure on well-known benchmarks and datasets, like Sceneflow and KITTI datasets, and demonstrate significant improvements in the depth accuracy metric.
Colored Point Cloud to Image Alignment
Oct 07, 2021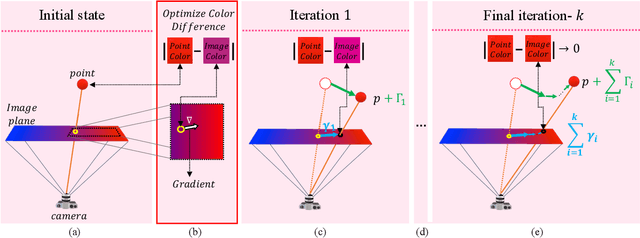


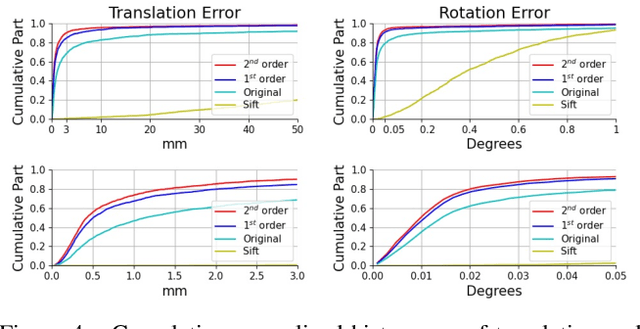
Recognition and segmentation of objects in images enjoy the wealth of large volume of well annotated data. At the other end, when dealing with the reconstruction of geometric structures of objects from images, there is a limited amount of accurate data available for supervised learning. One type of such geometric data with insufficient amount required for deep learning is real world accurate RGB-D images. The lack of accurate RGB-D datasets is one of the obstacles in the evolution of geometric scene reconstructions from images. One solution to creating such a dataset is to capture RGB images while simultaneously using an accurate depth scanning device that assigns a depth value to each pixel. A major challenge in acquiring such ground truth data is the accurate alignment between the RGB images and the measured depth and color profiles. We introduce a differential optimization method that aligns a colored point cloud to a given color image via iterative geometric and color matching. The proposed method enables the construction of RGB-D datasets for specific camera systems. In the suggested framework, the optimization minimizes the difference between the colors of the image pixels and the corresponding colors of the projected points to the camera plane. We assume that the colors produced by the geometric scanner camera and the color camera sensor are different and thus are characterized by different chromatic acquisition properties. We align the different color spaces while compensating for their corresponding color appearance. Under this setup, we find the transformation between the camera image and the point cloud colors by iterating between matching the relative location of the point cloud and matching colors. The successful alignments produced by the proposed method are demonstrated on both synthetic data with quantitative evaluation and real world scenes with qualitative results.