 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePathways on the Image Manifold: Image Editing via Video Generation
Nov 25, 2024
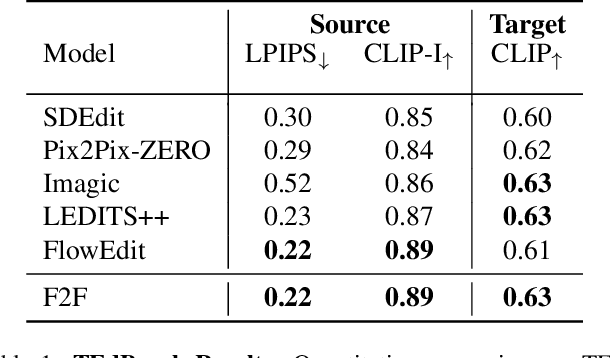
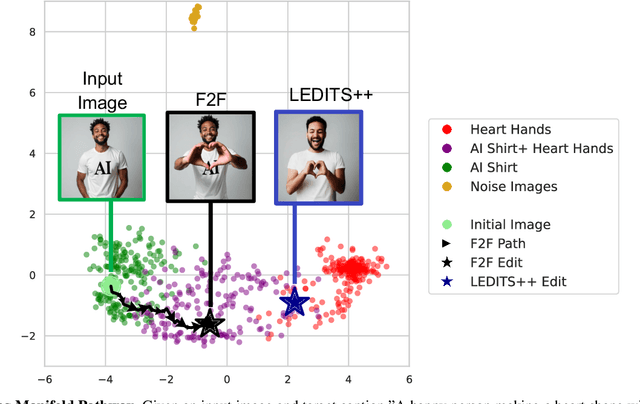
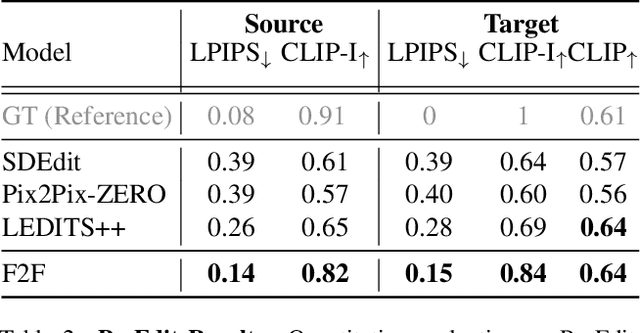
Recent advances in image editing, driven by image diffusion models, have shown remarkable progress. However, significant challenges remain, as these models often struggle to follow complex edit instructions accurately and frequently compromise fidelity by altering key elements of the original image. Simultaneously, video generation has made remarkable strides, with models that effectively function as consistent and continuous world simulators. In this paper, we propose merging these two fields by utilizing image-to-video models for image editing. We reformulate image editing as a temporal process, using pretrained video models to create smooth transitions from the original image to the desired edit. This approach traverses the image manifold continuously, ensuring consistent edits while preserving the original image's key aspects. Our approach achieves state-of-the-art results on text-based image editing, demonstrating significant improvements in both edit accuracy and image preservation.
CLIPTER: Looking at the Bigger Picture in Scene Text Recognition
Jan 18, 2023
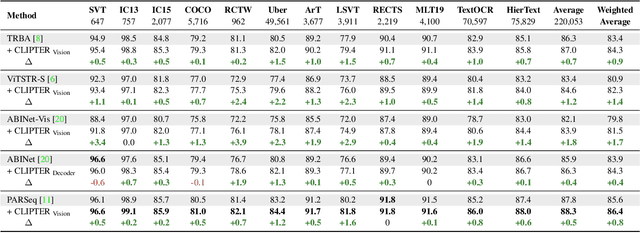
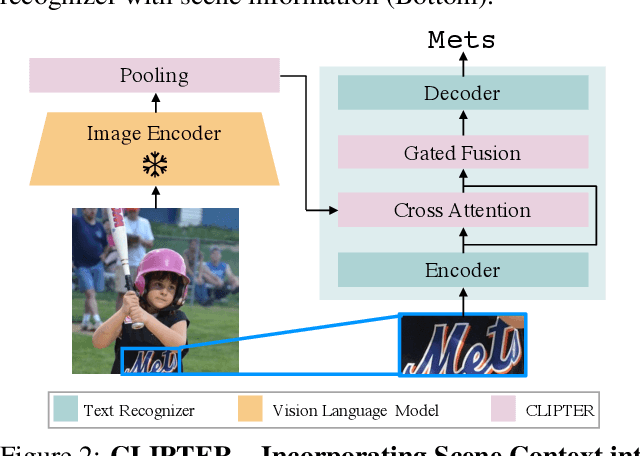

Understanding the scene is often essential for reading text in real-world scenarios. However, current scene text recognizers operate on cropped text images, unaware of the bigger picture. In this work, we harness the representative power of recent vision-language models, such as CLIP, to provide the crop-based recognizer with scene, image-level information. Specifically, we obtain a rich representation of the entire image and fuse it with the recognizer word-level features via cross-attention. Moreover, a gated mechanism is introduced that gradually shifts to the context-enriched representation, enabling simply fine-tuning a pretrained recognizer. We implement our model-agnostic framework, named CLIPTER - CLIP Text Recognition, on several leading text recognizers and demonstrate consistent performance gains, achieving state-of-the-art results over multiple benchmarks. Furthermore, an in-depth analysis reveals improved robustness to out-of-vocabulary words and enhanced generalization in low-data regimes.
Partial Shape Similarity via Alignment of Multi-Metric Hamiltonian Spectra
Jul 07, 2022



Evaluating the similarity of non-rigid shapes with significant partiality is a fundamental task in numerous computer vision applications. Here, we propose a novel axiomatic method to match similar regions across shapes. Matching similar regions is formulated as the alignment of the spectra of operators closely related to the Laplace-Beltrami operator (LBO). The main novelty of the proposed approach is the consideration of differential operators defined on a manifold with multiple metrics. The choice of a metric relates to fundamental shape properties while considering the same manifold under different metrics can thus be viewed as analyzing the underlying manifold from different perspectives. Specifically, we examine the scale-invariant metric and the corresponding scale-invariant Laplace-Beltrami operator (SI-LBO) along with the regular metric and the regular LBO. We demonstrate that the scale-invariant metric emphasizes the locations of important semantic features in articulated shapes. A truncated spectrum of the SI-LBO consequently better captures locally curved regions and complements the global information encapsulated in the truncated spectrum of the regular LBO. We show that matching these dual spectra outperforms competing axiomatic frameworks when tested on standard benchmarks. We introduced a new dataset and compare the proposed method with the state-of-the-art learning based approach in a cross-database configuration. Specifically, we show that, when trained on one data set and tested on another, the proposed axiomatic approach which does not involve training, outperforms the deep learning alternative.
Depth Refinement for Improved Stereo Reconstruction
Dec 15, 2021

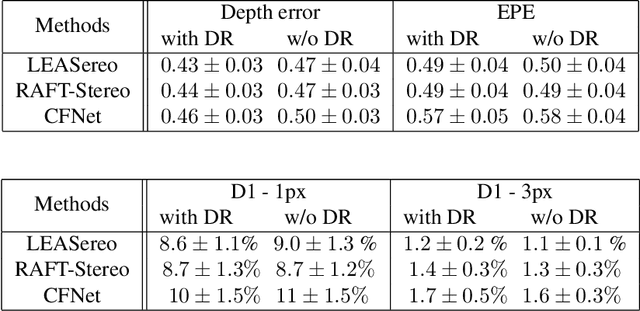
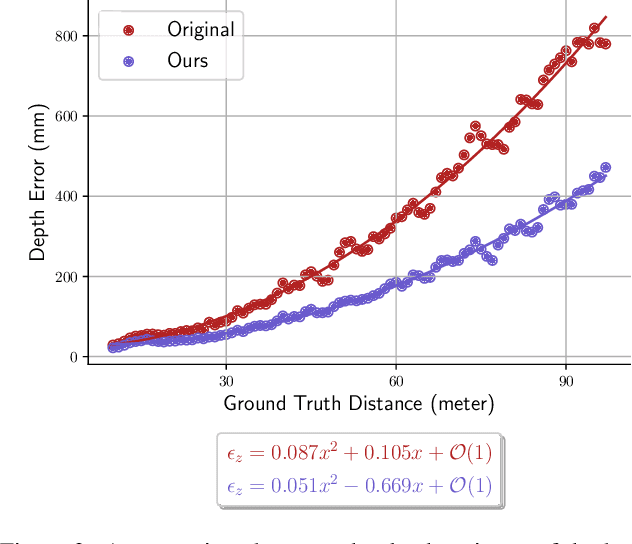
Depth estimation is a cornerstone of a vast number of applications requiring 3D assessment of the environment, such as robotics, augmented reality, and autonomous driving to name a few. One prominent technique for depth estimation is stereo matching which has several advantages: it is considered more accessible than other depth-sensing technologies, can produce dense depth estimates in real-time, and has benefited greatly from the advances of deep learning in recent years. However, current techniques for depth estimation from stereoscopic images still suffer from a built-in drawback. To reconstruct depth, a stereo matching algorithm first estimates the disparity map between the left and right images before applying a geometric triangulation. A simple analysis reveals that the depth error is quadratically proportional to the object's distance. Therefore, constant disparity errors are translated to large depth errors for objects far from the camera. To mitigate this quadratic relation, we propose a simple but effective method that uses a refinement network for depth estimation. We show analytical and empirical results suggesting that the proposed learning procedure reduces this quadratic relation. We evaluate the proposed refinement procedure on well-known benchmarks and datasets, like Sceneflow and KITTI datasets, and demonstrate significant improvements in the depth accuracy metric.