 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth Refinement for Improved Stereo Reconstruction
Paper and Code
Dec 15, 2021

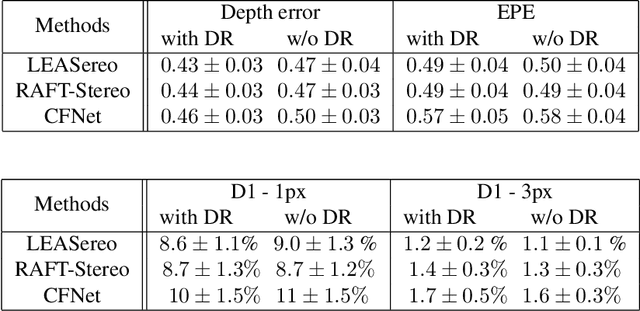
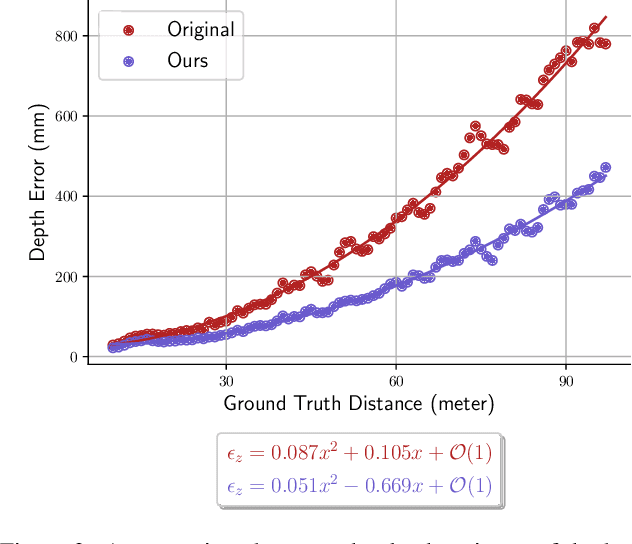
Depth estimation is a cornerstone of a vast number of applications requiring 3D assessment of the environment, such as robotics, augmented reality, and autonomous driving to name a few. One prominent technique for depth estimation is stereo matching which has several advantages: it is considered more accessible than other depth-sensing technologies, can produce dense depth estimates in real-time, and has benefited greatly from the advances of deep learning in recent years. However, current techniques for depth estimation from stereoscopic images still suffer from a built-in drawback. To reconstruct depth, a stereo matching algorithm first estimates the disparity map between the left and right images before applying a geometric triangulation. A simple analysis reveals that the depth error is quadratically proportional to the object's distance. Therefore, constant disparity errors are translated to large depth errors for objects far from the camera. To mitigate this quadratic relation, we propose a simple but effective method that uses a refinement network for depth estimation. We show analytical and empirical results suggesting that the proposed learning procedure reduces this quadratic relation. We evaluate the proposed refinement procedure on well-known benchmarks and datasets, like Sceneflow and KITTI datasets, and demonstrate significant improvements in the depth accuracy metric.