 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth Refinement for Improved Stereo Reconstruction
Dec 15, 2021

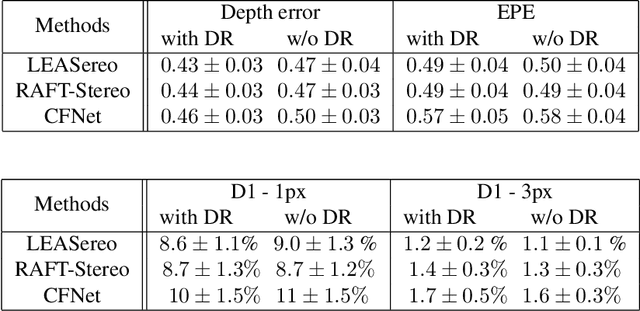
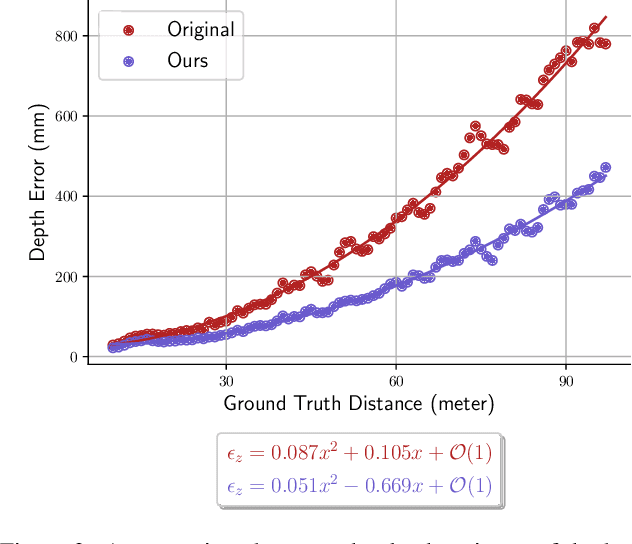
Depth estimation is a cornerstone of a vast number of applications requiring 3D assessment of the environment, such as robotics, augmented reality, and autonomous driving to name a few. One prominent technique for depth estimation is stereo matching which has several advantages: it is considered more accessible than other depth-sensing technologies, can produce dense depth estimates in real-time, and has benefited greatly from the advances of deep learning in recent years. However, current techniques for depth estimation from stereoscopic images still suffer from a built-in drawback. To reconstruct depth, a stereo matching algorithm first estimates the disparity map between the left and right images before applying a geometric triangulation. A simple analysis reveals that the depth error is quadratically proportional to the object's distance. Therefore, constant disparity errors are translated to large depth errors for objects far from the camera. To mitigate this quadratic relation, we propose a simple but effective method that uses a refinement network for depth estimation. We show analytical and empirical results suggesting that the proposed learning procedure reduces this quadratic relation. We evaluate the proposed refinement procedure on well-known benchmarks and datasets, like Sceneflow and KITTI datasets, and demonstrate significant improvements in the depth accuracy metric.
Unsupervised High-Fidelity Facial Texture Generation and Reconstruction
Oct 10, 2021

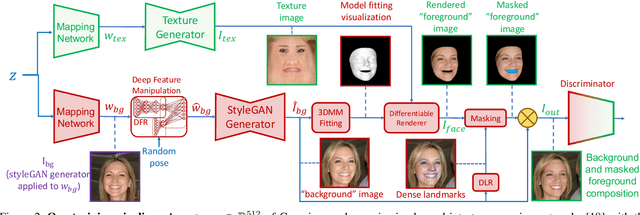

Many methods have been proposed over the years to tackle the task of facial 3D geometry and texture recovery from a single image. Such methods often fail to provide high-fidelity texture without relying on 3D facial scans during training. In contrast, the complementary task of 3D facial generation has not received as much attention. As opposed to the 2D texture domain, where GANs have proven to produce highly realistic facial images, the more challenging 3D geometry domain has not yet caught up to the same levels of realism and diversity. In this paper, we propose a novel unified pipeline for both tasks, generation of both geometry and texture, and recovery of high-fidelity texture. Our texture model is learned, in an unsupervised fashion, from natural images as opposed to scanned texture maps. To the best of our knowledge, this is the first such unified framework independent of scanned textures. Our novel training pipeline incorporates a pre-trained 2D facial generator coupled with a deep feature manipulation methodology. By applying precise 3DMM fitting, we can seamlessly integrate our modeled textures into synthetically generated background images forming a realistic composition of our textured model with background, hair, teeth, and body. This enables us to apply transfer learning from the domain of 2D image generation, thus, benefiting greatly from the impressive results obtained in this domain. We provide a comprehensive study on several recent methods comparing our model in generation and reconstruction tasks. As the extensive qualitative, as well as quantitative analysis, demonstrate, we achieve state-of-the-art results for both tasks.
On Calibration of Scene-Text Recognition Models
Dec 23, 2020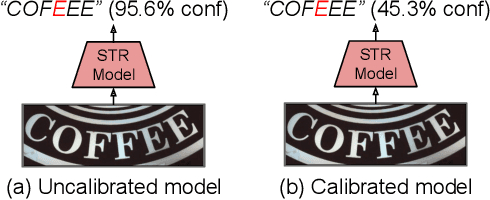
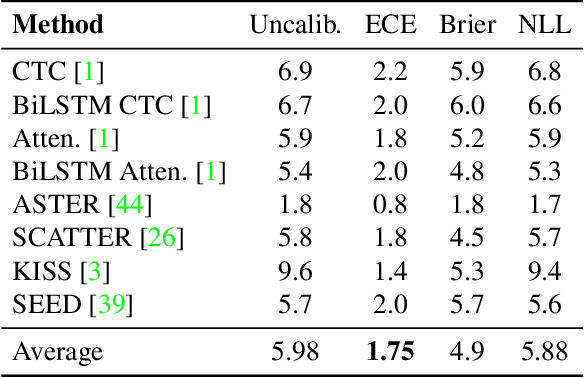
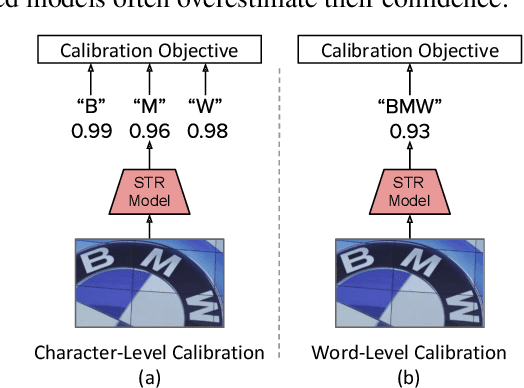
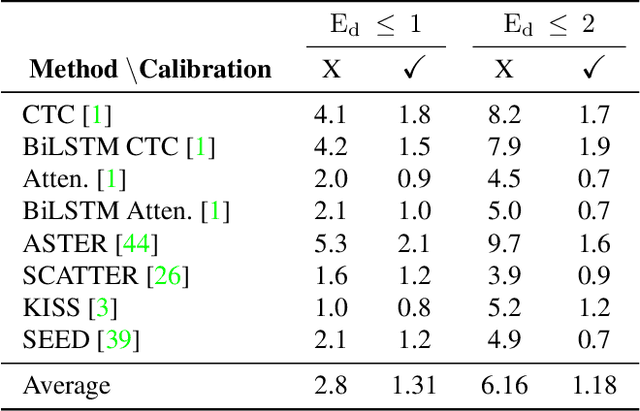
In this work, we study the problem of word-level confidence calibration for scene-text recognition (STR). Although the topic of confidence calibration has been an active research area for the last several decades, the case of structured and sequence prediction calibration has been scarcely explored. We analyze several recent STR methods and show that they are consistently overconfident. We then focus on the calibration of STR models on the word rather than the character level. In particular, we demonstrate that for attention based decoders, calibration of individual character predictions increases word-level calibration error compared to an uncalibrated model. In addition, we apply existing calibration methodologies as well as new sequence-based extensions to numerous STR models, demonstrating reduced calibration error by up to a factor of nearly 7. Finally, we show consistently improved accuracy results by applying our proposed sequence calibration method as a preprocessing step to beam-search.
Sequence-to-Sequence Contrastive Learning for Text Recognition
Dec 20, 2020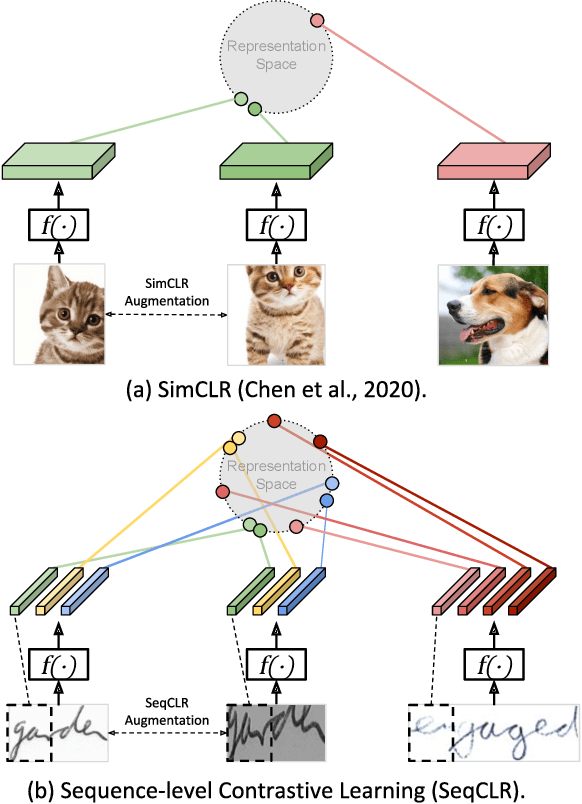
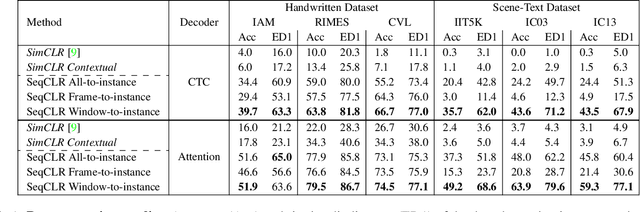
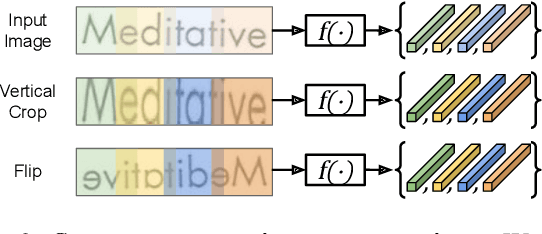
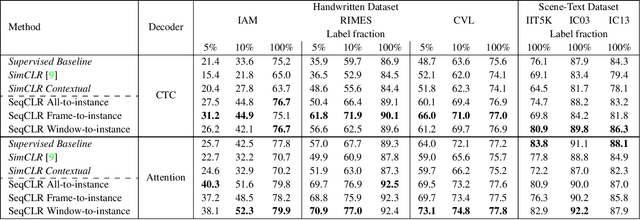
We propose a framework for sequence-to-sequence contrastive learning (SeqCLR) of visual representations, which we apply to text recognition. To account for the sequence-to-sequence structure, each feature map is divided into different instances over which the contrastive loss is computed. This operation enables us to contrast in a sub-word level, where from each image we extract several positive pairs and multiple negative examples. To yield effective visual representations for text recognition, we further suggest novel augmentation heuristics, different encoder architectures and custom projection heads. Experiments on handwritten text and on scene text show that when a text decoder is trained on the learned representations, our method outperforms non-sequential contrastive methods. In addition, when the amount of supervision is reduced, SeqCLR significantly improves performance compared with supervised training, and when fine-tuned with 100% of the labels, our method achieves state-of-the-art results on standard handwritten text recognition benchmarks.
Synthesizing facial photometries and corresponding geometries using generative adversarial networks
Jan 19, 2019

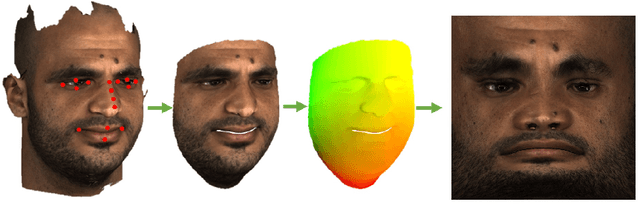

Artificial data synthesis is currently a well studied topic with useful applications in data science, computer vision, graphics and many other fields. Generating realistic data is especially challenging since human perception is highly sensitive to non realistic appearance. In recent times, new levels of realism have been achieved by advances in GAN training procedures and architectures. These successful models, however, are tuned mostly for use with regularly sampled data such as images, audio and video. Despite the successful application of the architecture on these types of media, applying the same tools to geometric data poses a far greater challenge. The study of geometric deep learning is still a debated issue within the academic community as the lack of intrinsic parametrization inherent to geometric objects prohibits the direct use of convolutional filters, a main building block of today's machine learning systems. In this paper we propose a new method for generating realistic human facial geometries coupled with overlayed textures. We circumvent the parametrization issue by imposing a global mapping from our data to the unit rectangle. We further discuss how to design such a mapping to control the mapping distortion and conserve area within the mapped image. By representing geometric textures and geometries as images, we are able to use advanced GAN methodologies to generate new geometries. We address the often neglected topic of relation between texture and geometry and propose to use this correlation to match between generated textures and their corresponding geometries. We offer a new method for training GAN models on partially corrupted data. Finally, we provide empirical evidence demonstrating our generative model's ability to produce examples of new identities independent from the training data while maintaining a high level of realism, two traits that are often at odds.
Efficient Deformable Shape Correspondence via Kernel Matching
Sep 15, 2017
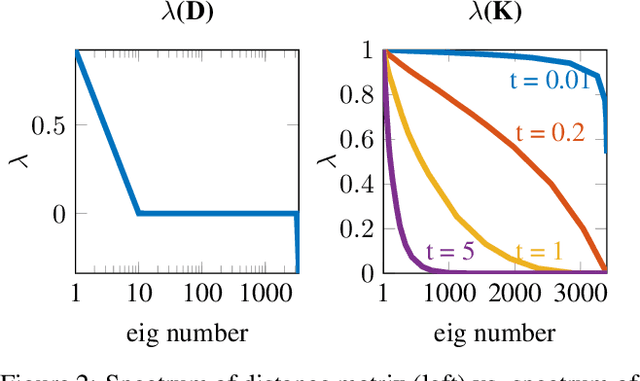
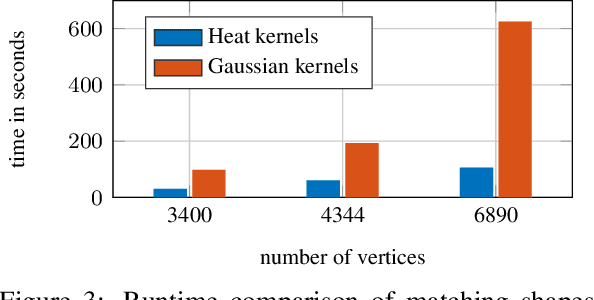

We present a method to match three dimensional shapes under non-isometric deformations, topology changes and partiality. We formulate the problem as matching between a set of pair-wise and point-wise descriptors, imposing a continuity prior on the mapping, and propose a projected descent optimization procedure inspired by difference of convex functions (DC) programming. Surprisingly, in spite of the highly non-convex nature of the resulting quadratic assignment problem, our method converges to a semantically meaningful and continuous mapping in most of our experiments, and scales well. We provide preliminary theoretical analysis and several interpretations of the method.
Deep Stereo Matching with Dense CRF Priors
Jan 24, 2017
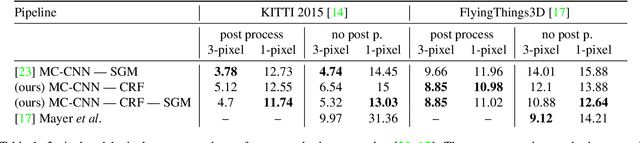
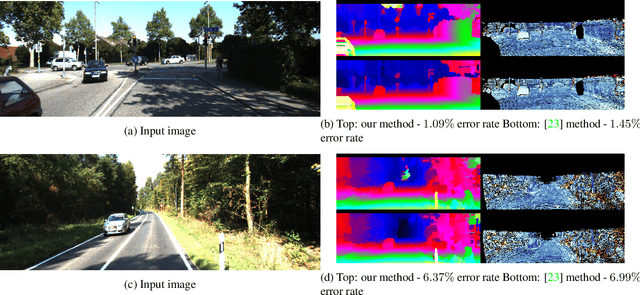
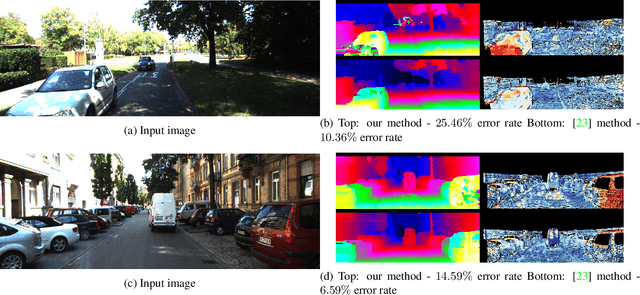
Stereo reconstruction from rectified images has recently been revisited within the context of deep learning. Using a deep Convolutional Neural Network to obtain patch-wise matching cost volumes has resulted in state of the art stereo reconstruction on classic datasets like Middlebury and Kitti. By introducing this cost into a classical stereo pipeline, the final results are improved dramatically over non-learning based cost models. However these pipelines typically include hand engineered post processing steps to effectively regularize and clean the result. Here, we show that it is possible to take a more holistic approach by training a fully end-to-end network which directly includes regularization in the form of a densely connected Conditional Random Field (CRF) that acts as a prior on inter-pixel interactions. We demonstrate that our approach on both synthetic and real world datasets outperforms an alternative end-to-end network and compares favorably to more hand engineered approaches.
Rule Of Thumb: Deep derotation for improved fingertip detection
Jul 21, 2015

We investigate a novel global orientation regression approach for articulated objects using a deep convolutional neural network. This is integrated with an in-plane image derotation scheme, DeROT, to tackle the problem of per-frame fingertip detection in depth images. The method reduces the complexity of learning in the space of articulated poses which is demonstrated by using two distinct state-of-the-art learning based hand pose estimation methods applied to fingertip detection. Significant classification improvements are shown over the baseline implementation. Our framework involves no tracking, kinematic constraints or explicit prior model of the articulated object in hand. To support our approach we also describe a new pipeline for high accuracy magnetic annotation and labeling of objects imaged by a depth camera.