 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Calibration of Scene-Text Recognition Models
Paper and Code
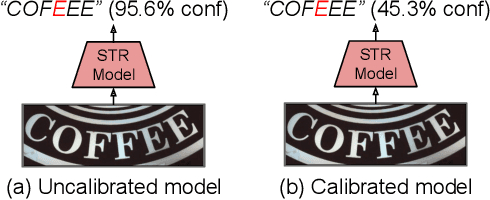
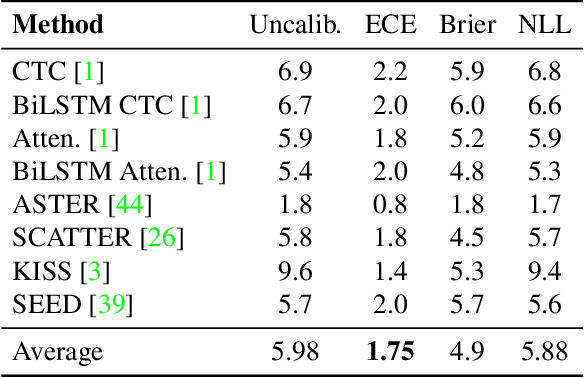
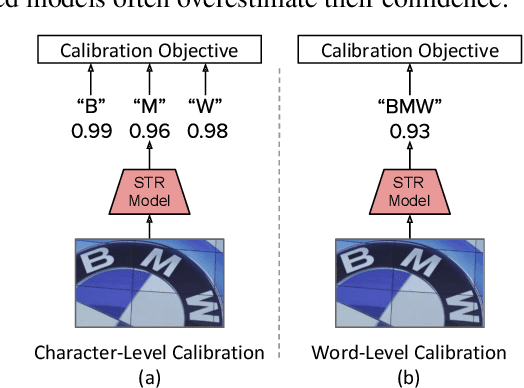
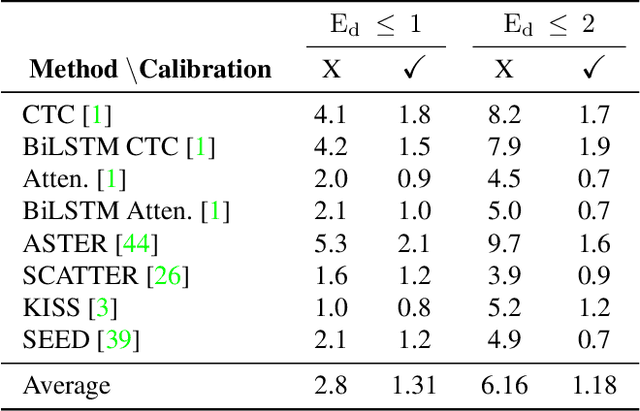
In this work, we study the problem of word-level confidence calibration for scene-text recognition (STR). Although the topic of confidence calibration has been an active research area for the last several decades, the case of structured and sequence prediction calibration has been scarcely explored. We analyze several recent STR methods and show that they are consistently overconfident. We then focus on the calibration of STR models on the word rather than the character level. In particular, we demonstrate that for attention based decoders, calibration of individual character predictions increases word-level calibration error compared to an uncalibrated model. In addition, we apply existing calibration methodologies as well as new sequence-based extensions to numerous STR models, demonstrating reduced calibration error by up to a factor of nearly 7. Finally, we show consistently improved accuracy results by applying our proposed sequence calibration method as a preprocessing step to beam-search.