 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrinciples of Designing Robust Remote Face Anti-Spoofing Systems
Jun 06, 2024

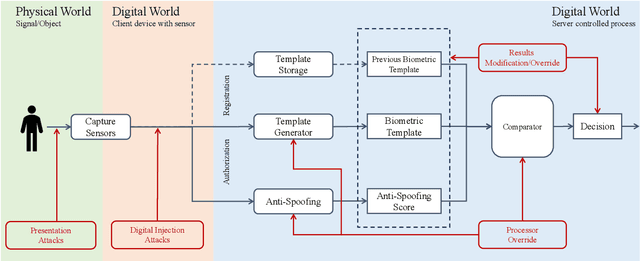

Protecting digital identities of human face from various attack vectors is paramount, and face anti-spoofing plays a crucial role in this endeavor. Current approaches primarily focus on detecting spoofing attempts within individual frames to detect presentation attacks. However, the emergence of hyper-realistic generative models capable of real-time operation has heightened the risk of digitally generated attacks. In light of these evolving threats, this paper aims to address two key aspects. First, it sheds light on the vulnerabilities of state-of-the-art face anti-spoofing methods against digital attacks. Second, it presents a comprehensive taxonomy of common threats encountered in face anti-spoofing systems. Through a series of experiments, we demonstrate the limitations of current face anti-spoofing detection techniques and their failure to generalize to novel digital attack scenarios. Notably, the existing models struggle with digital injection attacks including adversarial noise, realistic deepfake attacks, and digital replay attacks. To aid in the design and implementation of robust face anti-spoofing systems resilient to these emerging vulnerabilities, the paper proposes key design principles from model accuracy and robustness to pipeline robustness and even platform robustness. Especially, we suggest to implement the proactive face anti-spoofing system using active sensors to significant reduce the risks for unseen attack vectors and improve the user experience.
On Calibration of Scene-Text Recognition Models
Dec 23, 2020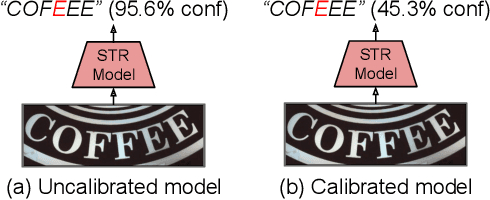
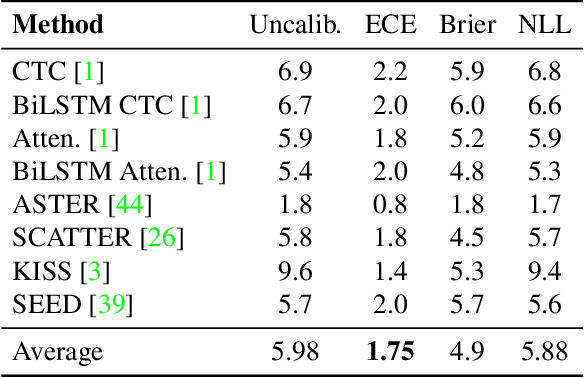
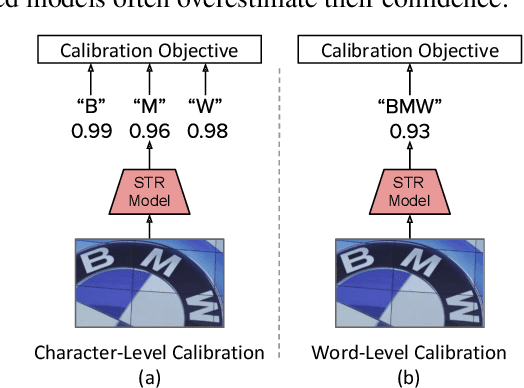
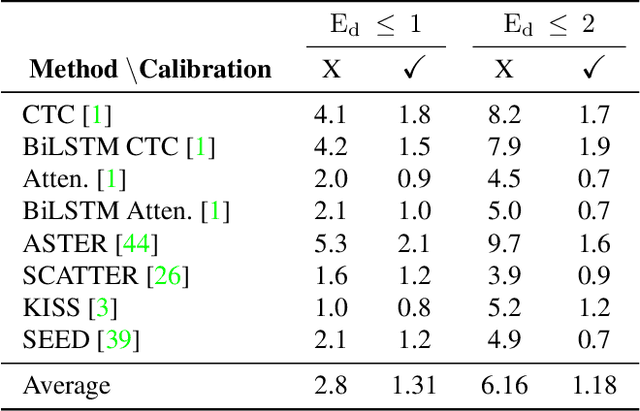
In this work, we study the problem of word-level confidence calibration for scene-text recognition (STR). Although the topic of confidence calibration has been an active research area for the last several decades, the case of structured and sequence prediction calibration has been scarcely explored. We analyze several recent STR methods and show that they are consistently overconfident. We then focus on the calibration of STR models on the word rather than the character level. In particular, we demonstrate that for attention based decoders, calibration of individual character predictions increases word-level calibration error compared to an uncalibrated model. In addition, we apply existing calibration methodologies as well as new sequence-based extensions to numerous STR models, demonstrating reduced calibration error by up to a factor of nearly 7. Finally, we show consistently improved accuracy results by applying our proposed sequence calibration method as a preprocessing step to beam-search.
TextTubes for Detecting Curved Text in the Wild
Dec 19, 2019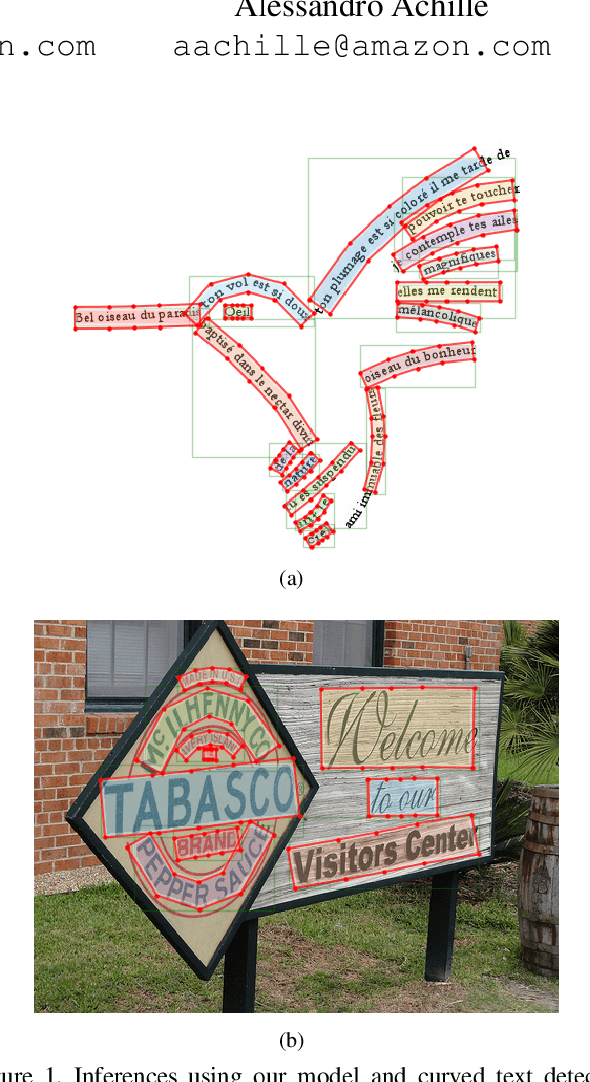
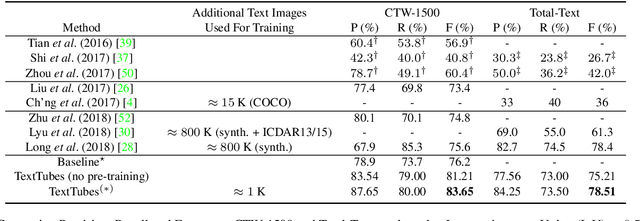

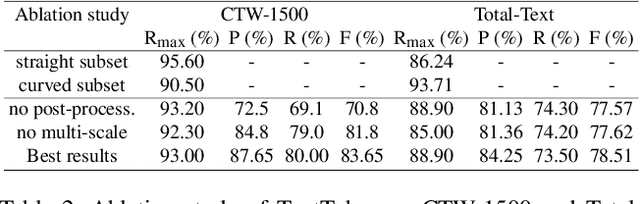
We present a detector for curved text in natural images. We model scene text instances as tubes around their medial axes and introduce a parametrization-invariant loss function. We train a two-stage curved text detector, and evaluate it on the curved text benchmarks CTW-1500 and Total-Text. Our approach achieves state-of-the-art results or improves upon them, notably for CTW-1500 by over 8 percentage points in F-score.