 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExecTune: Effective Steering of Black-Box LLMs with Guide Models
Apr 09, 2026For large language models deployed through black-box APIs, recurring inference costs often exceed one-time training costs. This motivates composed agentic systems that amortize expensive reasoning into reusable intermediate representations. We study a broad class of such systems, termed Guide-Core Policies (GCoP), in which a guide model generates a structured strategy that is executed by a black-box core model. This abstraction subsumes base, supervised, and advisor-style approaches, which differ primarily in how the guide is trained. We formalize GCoP under a cost-sensitive utility objective and show that end-to-end performance is governed by guide-averaged executability: the probability that a strategy generated by the guide can be faithfully executed by the core. Our analysis shows that existing GCoP instantiations often fail to optimize executability under deployment constraints, resulting in brittle strategies and inefficient computation. Motivated by these insights, we propose ExecTune, a principled training recipe that combines teacher-guided acceptance sampling, supervised fine-tuning, and structure-aware reinforcement learning to directly optimize syntactic validity, execution success, and cost efficiency. Across mathematical reasoning and code-generation benchmarks, GCoP with ExecTune improves accuracy by up to 9.2% over prior state-of-the-art baselines while reducing inference cost by up to 22.4%. It enables Claude Haiku 3.5 to outperform Sonnet 3.5 on both math and code tasks, and to come within 1.7% absolute accuracy of Sonnet 4 at 38% lower cost. Beyond efficiency, GCoP also supports modular adaptation by updating the guide without retraining the core.
e1: Learning Adaptive Control of Reasoning Effort
Oct 30, 2025Increasing the thinking budget of AI models can significantly improve accuracy, but not all questions warrant the same amount of reasoning. Users may prefer to allocate different amounts of reasoning effort depending on how they value output quality versus latency and cost. To leverage this tradeoff effectively, users need fine-grained control over the amount of thinking used for a particular query, but few approaches enable such control. Existing methods require users to specify the absolute number of desired tokens, but this requires knowing the difficulty of the problem beforehand to appropriately set the token budget for a query. To address these issues, we propose Adaptive Effort Control, a self-adaptive reinforcement learning method that trains models to use a user-specified fraction of tokens relative to the current average chain-of-thought length for each query. This approach eliminates dataset- and phase-specific tuning while producing better cost-accuracy tradeoff curves compared to standard methods. Users can dynamically adjust the cost-accuracy trade-off through a continuous effort parameter specified at inference time. We observe that the model automatically learns to allocate resources proportionally to the task difficulty and, across model scales ranging from 1.5B to 32B parameters, our approach enables approximately 3x reduction in chain-of-thought length while maintaining or improving performance relative to the base model used for RL training.
PICASO: Permutation-Invariant Context Composition with State Space Models
Feb 24, 2025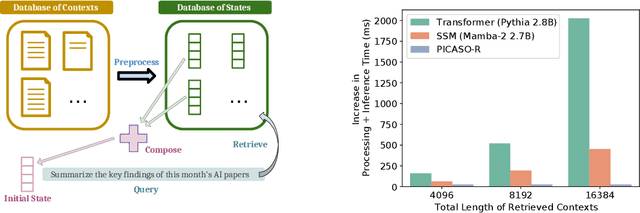

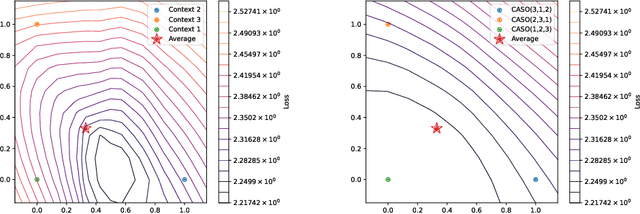

Providing Large Language Models with relevant contextual knowledge at inference time has been shown to greatly improve the quality of their generations. This is often achieved by prepending informative passages of text, or 'contexts', retrieved from external knowledge bases to their input. However, processing additional contexts online incurs significant computation costs that scale with their length. State Space Models (SSMs) offer a promising solution by allowing a database of contexts to be mapped onto fixed-dimensional states from which to start the generation. A key challenge arises when attempting to leverage information present across multiple contexts, since there is no straightforward way to condition generation on multiple independent states in existing SSMs. To address this, we leverage a simple mathematical relation derived from SSM dynamics to compose multiple states into one that efficiently approximates the effect of concatenating textual contexts. Since the temporal ordering of contexts can often be uninformative, we enforce permutation-invariance by efficiently averaging states obtained via our composition algorithm across all possible context orderings. We evaluate our resulting method on WikiText and MSMARCO in both zero-shot and fine-tuned settings, and show that we can match the strongest performing baseline while enjoying on average 5.4x speedup.
Descriminative-Generative Custom Tokens for Vision-Language Models
Feb 17, 2025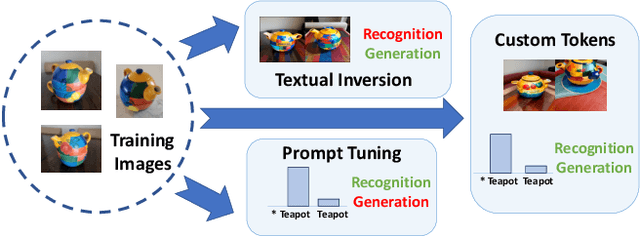

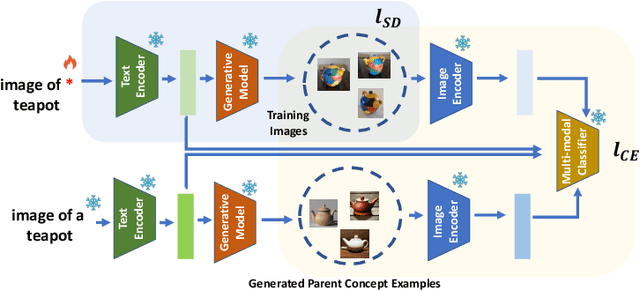
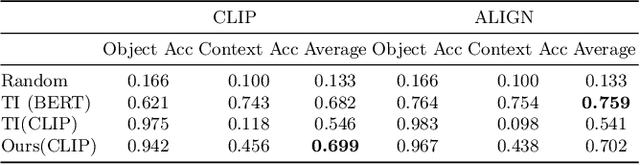
This paper explores the possibility of learning custom tokens for representing new concepts in Vision-Language Models (VLMs). Our aim is to learn tokens that can be effective for both discriminative and generative tasks while composing well with words to form new input queries. The targeted concept is specified in terms of a small set of images and a parent concept described using text. We operate on CLIP text features and propose to use a combination of a textual inversion loss and a classification loss to ensure that text features of the learned token are aligned with image features of the concept in the CLIP embedding space. We restrict the learned token to a low-dimensional subspace spanned by tokens for attributes that are appropriate for the given super-class. These modifications improve the quality of compositions of the learned token with natural language for generating new scenes. Further, we show that learned custom tokens can be used to form queries for text-to-image retrieval task, and also have the important benefit that composite queries can be visualized to ensure that the desired concept is faithfully encoded. Based on this, we introduce the method of Generation Aided Image Retrieval, where the query is modified at inference time to better suit the search intent. On the DeepFashion2 dataset, our method improves Mean Reciprocal Retrieval (MRR) over relevant baselines by 7%.
Compositional Structures in Neural Embedding and Interaction Decompositions
Jul 12, 2024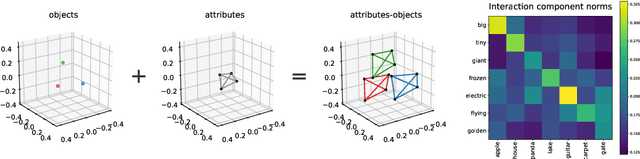
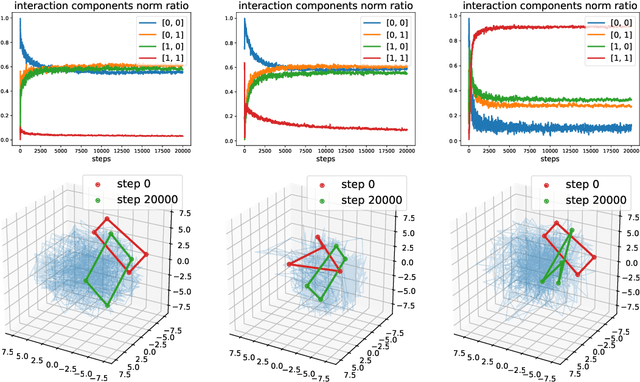
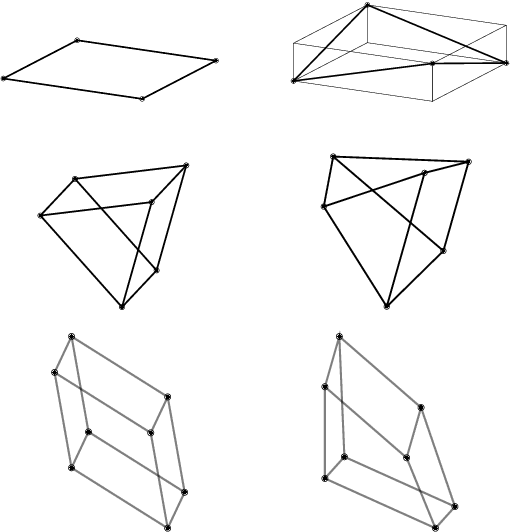
We describe a basic correspondence between linear algebraic structures within vector embeddings in artificial neural networks and conditional independence constraints on the probability distributions modeled by these networks. Our framework aims to shed light on the emergence of structural patterns in data representations, a phenomenon widely acknowledged but arguably still lacking a solid formal grounding. Specifically, we introduce a characterization of compositional structures in terms of "interaction decompositions," and we establish necessary and sufficient conditions for the presence of such structures within the representations of a model.
B'MOJO: Hybrid State Space Realizations of Foundation Models with Eidetic and Fading Memory
Jul 08, 2024We describe a family of architectures to support transductive inference by allowing memory to grow to a finite but a-priori unknown bound while making efficient use of finite resources for inference. Current architectures use such resources to represent data either eidetically over a finite span ("context" in Transformers), or fading over an infinite span (in State Space Models, or SSMs). Recent hybrid architectures have combined eidetic and fading memory, but with limitations that do not allow the designer or the learning process to seamlessly modulate the two, nor to extend the eidetic memory span. We leverage ideas from Stochastic Realization Theory to develop a class of models called B'MOJO to seamlessly combine eidetic and fading memory within an elementary composable module. The overall architecture can be used to implement models that can access short-term eidetic memory "in-context," permanent structural memory "in-weights," fading memory "in-state," and long-term eidetic memory "in-storage" by natively incorporating retrieval from an asynchronously updated memory. We show that Transformers, existing SSMs such as Mamba, and hybrid architectures such as Jamba are special cases of B'MOJO and describe a basic implementation, to be open sourced, that can be stacked and scaled efficiently in hardware. We test B'MOJO on transductive inference tasks, such as associative recall, where it outperforms existing SSMs and Hybrid models; as a baseline, we test ordinary language modeling where B'MOJO achieves perplexity comparable to similarly-sized Transformers and SSMs up to 1.4B parameters, while being up to 10% faster to train. Finally, we show that B'MOJO's ability to modulate eidetic and fading memory results in better inference on longer sequences tested up to 32K tokens, four-fold the length of the longest sequences seen during training.
Diffusion Soup: Model Merging for Text-to-Image Diffusion Models
Jun 12, 2024



We present Diffusion Soup, a compartmentalization method for Text-to-Image Generation that averages the weights of diffusion models trained on sharded data. By construction, our approach enables training-free continual learning and unlearning with no additional memory or inference costs, since models corresponding to data shards can be added or removed by re-averaging. We show that Diffusion Soup samples from a point in weight space that approximates the geometric mean of the distributions of constituent datasets, which offers anti-memorization guarantees and enables zero-shot style mixing. Empirically, Diffusion Soup outperforms a paragon model trained on the union of all data shards and achieves a 30% improvement in Image Reward (.34 $\to$ .44) on domain sharded data, and a 59% improvement in IR (.37 $\to$ .59) on aesthetic data. In both cases, souping also prevails in TIFA score (respectively, 85.5 $\to$ 86.5 and 85.6 $\to$ 86.8). We demonstrate robust unlearning -- removing any individual domain shard only lowers performance by 1% in IR (.45 $\to$ .44) -- and validate our theoretical insights on anti-memorization using real data. Finally, we showcase Diffusion Soup's ability to blend the distinct styles of models finetuned on different shards, resulting in the zero-shot generation of hybrid styles.
Principles of Designing Robust Remote Face Anti-Spoofing Systems
Jun 06, 2024

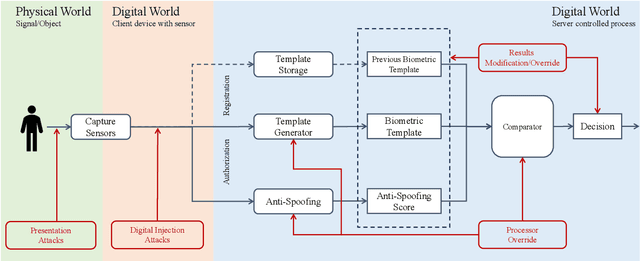

Protecting digital identities of human face from various attack vectors is paramount, and face anti-spoofing plays a crucial role in this endeavor. Current approaches primarily focus on detecting spoofing attempts within individual frames to detect presentation attacks. However, the emergence of hyper-realistic generative models capable of real-time operation has heightened the risk of digitally generated attacks. In light of these evolving threats, this paper aims to address two key aspects. First, it sheds light on the vulnerabilities of state-of-the-art face anti-spoofing methods against digital attacks. Second, it presents a comprehensive taxonomy of common threats encountered in face anti-spoofing systems. Through a series of experiments, we demonstrate the limitations of current face anti-spoofing detection techniques and their failure to generalize to novel digital attack scenarios. Notably, the existing models struggle with digital injection attacks including adversarial noise, realistic deepfake attacks, and digital replay attacks. To aid in the design and implementation of robust face anti-spoofing systems resilient to these emerging vulnerabilities, the paper proposes key design principles from model accuracy and robustness to pipeline robustness and even platform robustness. Especially, we suggest to implement the proactive face anti-spoofing system using active sensors to significant reduce the risks for unseen attack vectors and improve the user experience.
NeRF-Insert: 3D Local Editing with Multimodal Control Signals
Apr 30, 2024



We propose NeRF-Insert, a NeRF editing framework that allows users to make high-quality local edits with a flexible level of control. Unlike previous work that relied on image-to-image models, we cast scene editing as an in-painting problem, which encourages the global structure of the scene to be preserved. Moreover, while most existing methods use only textual prompts to condition edits, our framework accepts a combination of inputs of different modalities as reference. More precisely, a user may provide a combination of textual and visual inputs including images, CAD models, and binary image masks for specifying a 3D region. We use generic image generation models to in-paint the scene from multiple viewpoints, and lift the local edits to a 3D-consistent NeRF edit. Compared to previous methods, our results show better visual quality and also maintain stronger consistency with the original NeRF.
CPR: Retrieval Augmented Generation for Copyright Protection
Mar 27, 2024Retrieval Augmented Generation (RAG) is emerging as a flexible and robust technique to adapt models to private users data without training, to handle credit attribution, and to allow efficient machine unlearning at scale. However, RAG techniques for image generation may lead to parts of the retrieved samples being copied in the model's output. To reduce risks of leaking private information contained in the retrieved set, we introduce Copy-Protected generation with Retrieval (CPR), a new method for RAG with strong copyright protection guarantees in a mixed-private setting for diffusion models.CPR allows to condition the output of diffusion models on a set of retrieved images, while also guaranteeing that unique identifiable information about those example is not exposed in the generated outputs. In particular, it does so by sampling from a mixture of public (safe) distribution and private (user) distribution by merging their diffusion scores at inference. We prove that CPR satisfies Near Access Freeness (NAF) which bounds the amount of information an attacker may be able to extract from the generated images. We provide two algorithms for copyright protection, CPR-KL and CPR-Choose. Unlike previously proposed rejection-sampling-based NAF methods, our methods enable efficient copyright-protected sampling with a single run of backward diffusion. We show that our method can be applied to any pre-trained conditional diffusion model, such as Stable Diffusion or unCLIP. In particular, we empirically show that applying CPR on top of unCLIP improves quality and text-to-image alignment of the generated results (81.4 to 83.17 on TIFA benchmark), while enabling credit attribution, copy-right protection, and deterministic, constant time, unlearning.