 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDescriminative-Generative Custom Tokens for Vision-Language Models
Paper and Code
Feb 17, 2025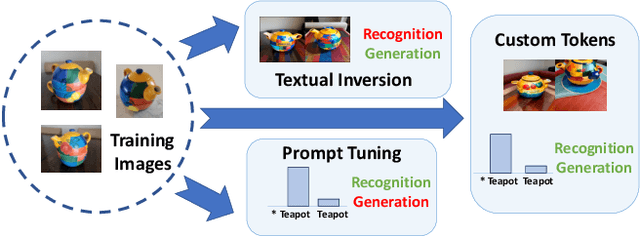

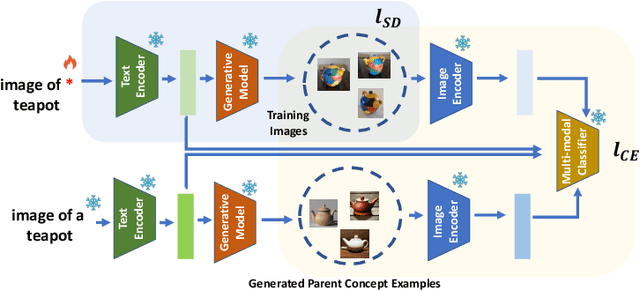
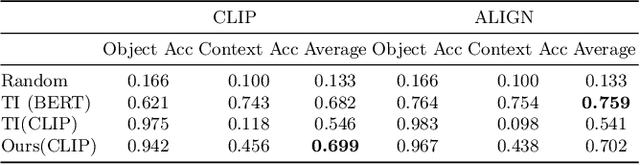
This paper explores the possibility of learning custom tokens for representing new concepts in Vision-Language Models (VLMs). Our aim is to learn tokens that can be effective for both discriminative and generative tasks while composing well with words to form new input queries. The targeted concept is specified in terms of a small set of images and a parent concept described using text. We operate on CLIP text features and propose to use a combination of a textual inversion loss and a classification loss to ensure that text features of the learned token are aligned with image features of the concept in the CLIP embedding space. We restrict the learned token to a low-dimensional subspace spanned by tokens for attributes that are appropriate for the given super-class. These modifications improve the quality of compositions of the learned token with natural language for generating new scenes. Further, we show that learned custom tokens can be used to form queries for text-to-image retrieval task, and also have the important benefit that composite queries can be visualized to ensure that the desired concept is faithfully encoded. Based on this, we introduce the method of Generation Aided Image Retrieval, where the query is modified at inference time to better suit the search intent. On the DeepFashion2 dataset, our method improves Mean Reciprocal Retrieval (MRR) over relevant baselines by 7%.