 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDescriminative-Generative Custom Tokens for Vision-Language Models
Feb 17, 2025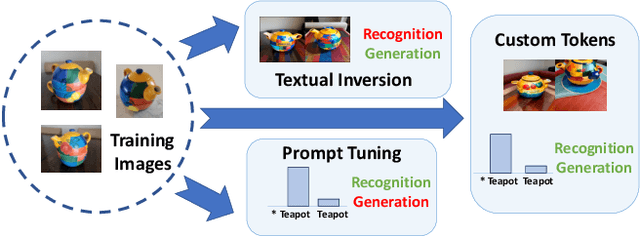

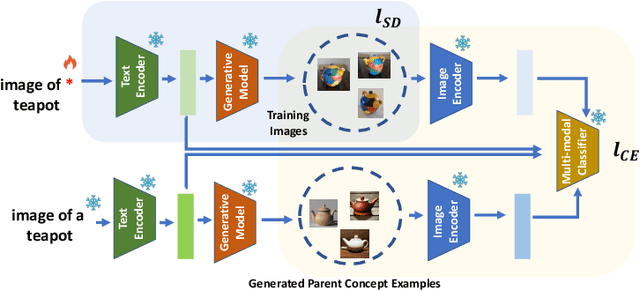
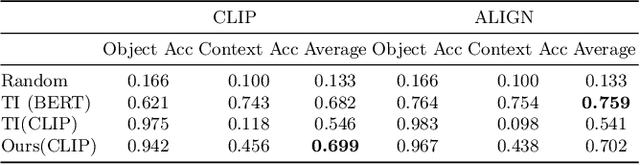
This paper explores the possibility of learning custom tokens for representing new concepts in Vision-Language Models (VLMs). Our aim is to learn tokens that can be effective for both discriminative and generative tasks while composing well with words to form new input queries. The targeted concept is specified in terms of a small set of images and a parent concept described using text. We operate on CLIP text features and propose to use a combination of a textual inversion loss and a classification loss to ensure that text features of the learned token are aligned with image features of the concept in the CLIP embedding space. We restrict the learned token to a low-dimensional subspace spanned by tokens for attributes that are appropriate for the given super-class. These modifications improve the quality of compositions of the learned token with natural language for generating new scenes. Further, we show that learned custom tokens can be used to form queries for text-to-image retrieval task, and also have the important benefit that composite queries can be visualized to ensure that the desired concept is faithfully encoded. Based on this, we introduce the method of Generation Aided Image Retrieval, where the query is modified at inference time to better suit the search intent. On the DeepFashion2 dataset, our method improves Mean Reciprocal Retrieval (MRR) over relevant baselines by 7%.
Approximately Aligned Decoding
Oct 01, 2024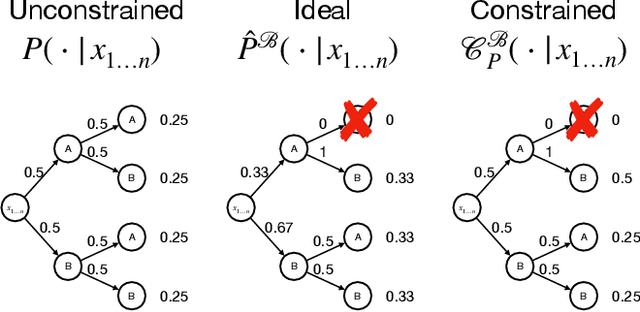
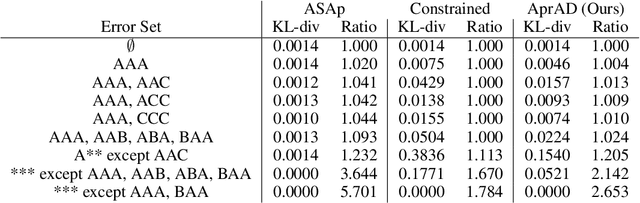

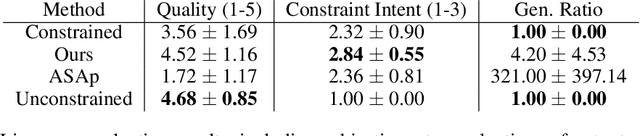
It is common to reject undesired outputs of Large Language Models (LLMs); however, current methods to do so require an excessive amount of computation, or severely distort the distribution of outputs. We present a method to balance the distortion of the output distribution with computational efficiency, allowing for the generation of long sequences of text with difficult-to-satisfy constraints, with less amplification of low probability outputs compared to existing methods. We show through a series of experiments that the task-specific performance of our method is comparable to methods that do not distort the output distribution, while being much more computationally efficient.
Compositional Structures in Neural Embedding and Interaction Decompositions
Jul 12, 2024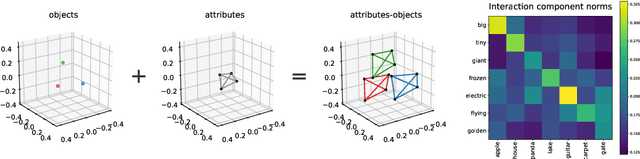
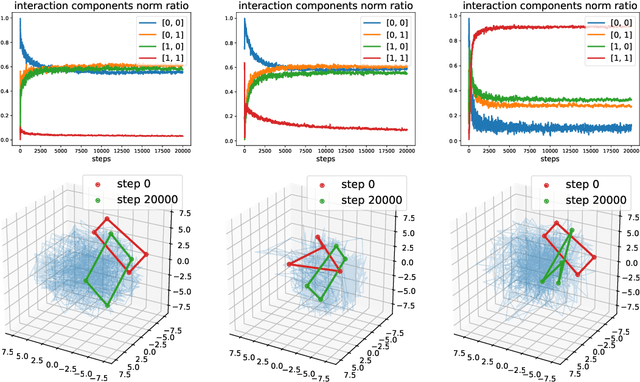
We describe a basic correspondence between linear algebraic structures within vector embeddings in artificial neural networks and conditional independence constraints on the probability distributions modeled by these networks. Our framework aims to shed light on the emergence of structural patterns in data representations, a phenomenon widely acknowledged but arguably still lacking a solid formal grounding. Specifically, we introduce a characterization of compositional structures in terms of "interaction decompositions," and we establish necessary and sufficient conditions for the presence of such structures within the representations of a model.
Multi-Modal Hallucination Control by Visual Information Grounding
Mar 20, 2024



Generative Vision-Language Models (VLMs) are prone to generate plausible-sounding textual answers that, however, are not always grounded in the input image. We investigate this phenomenon, usually referred to as "hallucination" and show that it stems from an excessive reliance on the language prior. In particular, we show that as more tokens are generated, the reliance on the visual prompt decreases, and this behavior strongly correlates with the emergence of hallucinations. To reduce hallucinations, we introduce Multi-Modal Mutual-Information Decoding (M3ID), a new sampling method for prompt amplification. M3ID amplifies the influence of the reference image over the language prior, hence favoring the generation of tokens with higher mutual information with the visual prompt. M3ID can be applied to any pre-trained autoregressive VLM at inference time without necessitating further training and with minimal computational overhead. If training is an option, we show that M3ID can be paired with Direct Preference Optimization (DPO) to improve the model's reliance on the prompt image without requiring any labels. Our empirical findings show that our algorithms maintain the fluency and linguistic capabilities of pre-trained VLMs while reducing hallucinations by mitigating visually ungrounded answers. Specifically, for the LLaVA 13B model, M3ID and M3ID+DPO reduce the percentage of hallucinated objects in captioning tasks by 25% and 28%, respectively, and improve the accuracy on VQA benchmarks such as POPE by 21% and 24%.
Meaning Representations from Trajectories in Autoregressive Models
Nov 02, 2023We propose to extract meaning representations from autoregressive language models by considering the distribution of all possible trajectories extending an input text. This strategy is prompt-free, does not require fine-tuning, and is applicable to any pre-trained autoregressive model. Moreover, unlike vector-based representations, distribution-based representations can also model asymmetric relations (e.g., direction of logical entailment, hypernym/hyponym relations) by using algebraic operations between likelihood functions. These ideas are grounded in distributional perspectives on semantics and are connected to standard constructions in automata theory, but to our knowledge they have not been applied to modern language models. We empirically show that the representations obtained from large models align well with human annotations, outperform other zero-shot and prompt-free methods on semantic similarity tasks, and can be used to solve more complex entailment and containment tasks that standard embeddings cannot handle. Finally, we extend our method to represent data from different modalities (e.g., image and text) using multimodal autoregressive models.
Prompt Algebra for Task Composition
Jun 01, 2023We investigate whether prompts learned independently for different tasks can be later combined through prompt algebra to obtain a model that supports composition of tasks. We consider Visual Language Models (VLM) with prompt tuning as our base classifier and formally define the notion of prompt algebra. We propose constrained prompt tuning to improve performance of the composite classifier. In the proposed scheme, prompts are constrained to appear in the lower dimensional subspace spanned by the basis vectors of the pre-trained vocabulary. Further regularization is added to ensure that the learned prompt is grounded correctly to the existing pre-trained vocabulary. We demonstrate the effectiveness of our method on object classification and object-attribute classification datasets. On average, our composite model obtains classification accuracy within 2.5% of the best base model. On UTZappos it improves classification accuracy over the best base model by 8.45% on average.
Generate then Select: Open-ended Visual Question Answering Guided by World Knowledge
May 30, 2023

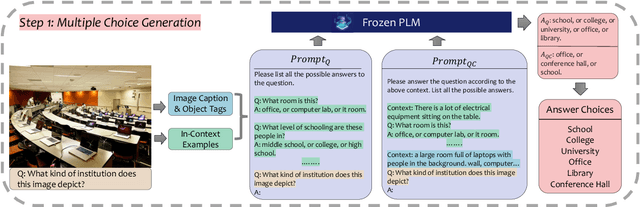
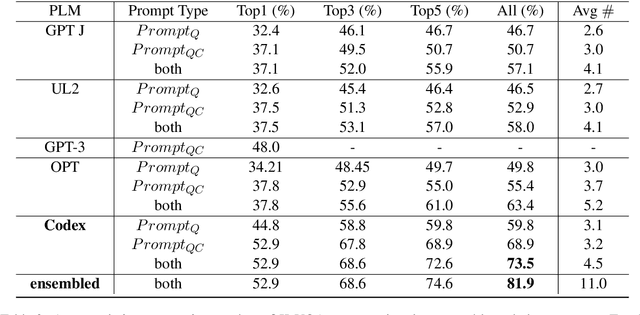
The open-ended Visual Question Answering (VQA) task requires AI models to jointly reason over visual and natural language inputs using world knowledge. Recently, pre-trained Language Models (PLM) such as GPT-3 have been applied to the task and shown to be powerful world knowledge sources. However, these methods suffer from low knowledge coverage caused by PLM bias -- the tendency to generate certain tokens over other tokens regardless of prompt changes, and high dependency on the PLM quality -- only models using GPT-3 can achieve the best result. To address the aforementioned challenges, we propose RASO: a new VQA pipeline that deploys a generate-then-select strategy guided by world knowledge for the first time. Rather than following the de facto standard to train a multi-modal model that directly generates the VQA answer, RASO first adopts PLM to generate all the possible answers, and then trains a lightweight answer selection model for the correct answer. As proved in our analysis, RASO expands the knowledge coverage from in-domain training data by a large margin. We provide extensive experimentation and show the effectiveness of our pipeline by advancing the state-of-the-art by 4.1% on OK-VQA, without additional computation cost. Code and models are released at http://cogcomp.org/page/publication_view/1010
Benchmarking Diverse-Modal Entity Linking with Generative Models
May 27, 2023Entities can be expressed in diverse formats, such as texts, images, or column names and cell values in tables. While existing entity linking (EL) models work well on per modality configuration, such as text-only EL, visual grounding, or schema linking, it is more challenging to design a unified model for diverse modality configurations. To bring various modality configurations together, we constructed a benchmark for diverse-modal EL (DMEL) from existing EL datasets, covering all three modalities including text, image, and table. To approach the DMEL task, we proposed a generative diverse-modal model (GDMM) following a multimodal-encoder-decoder paradigm. Pre-training \Model with rich corpora builds a solid foundation for DMEL without storing the entire KB for inference. Fine-tuning GDMM builds a stronger DMEL baseline, outperforming state-of-the-art task-specific EL models by 8.51 F1 score on average. Additionally, extensive error analyses are conducted to highlight the challenges of DMEL, facilitating future research on this task.
Train/Test-Time Adaptation with Retrieval
Mar 25, 2023We introduce Train/Test-Time Adaptation with Retrieval (${\rm T^3AR}$), a method to adapt models both at train and test time by means of a retrieval module and a searchable pool of external samples. Before inference, ${\rm T^3AR}$ adapts a given model to the downstream task using refined pseudo-labels and a self-supervised contrastive objective function whose noise distribution leverages retrieved real samples to improve feature adaptation on the target data manifold. The retrieval of real images is key to ${\rm T^3AR}$ since it does not rely solely on synthetic data augmentations to compensate for the lack of adaptation data, as typically done by other adaptation algorithms. Furthermore, thanks to the retrieval module, our method gives the user or service provider the possibility to improve model adaptation on the downstream task by incorporating further relevant data or to fully remove samples that may no longer be available due to changes in user preference after deployment. First, we show that ${\rm T^3AR}$ can be used at training time to improve downstream fine-grained classification over standard fine-tuning baselines, and the fewer the adaptation data the higher the relative improvement (up to 13%). Second, we apply ${\rm T^3AR}$ for test-time adaptation and show that exploiting a pool of external images at test-time leads to more robust representations over existing methods on DomainNet-126 and VISDA-C, especially when few adaptation data are available (up to 8%).
Linear Spaces of Meanings: the Compositional Language of VLMs
Feb 28, 2023We investigate compositional structures in vector data embeddings from pre-trained vision-language models (VLMs). Traditionally, compositionality has been associated with algebraic operations on embeddings of words from a pre-existing vocabulary. In contrast, we seek to approximate label representations from a text encoder as combinations of a smaller set of vectors in the embedding space. These vectors can be seen as "ideal words" which can be used to generate new concepts in an efficient way. We present a theoretical framework for understanding linear compositionality, drawing connections with mathematical representation theory and previous definitions of disentanglement. We provide theoretical and empirical evidence that ideal words provide good compositional approximations of composite concepts and can be more effective than token-based decompositions of the same concepts.