 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextual Gradients are a Flawed Metaphor for Automatic Prompt Optimization
Dec 15, 2025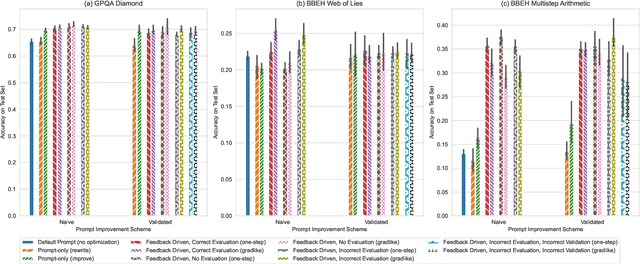
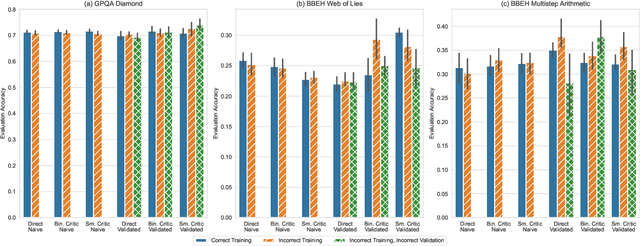
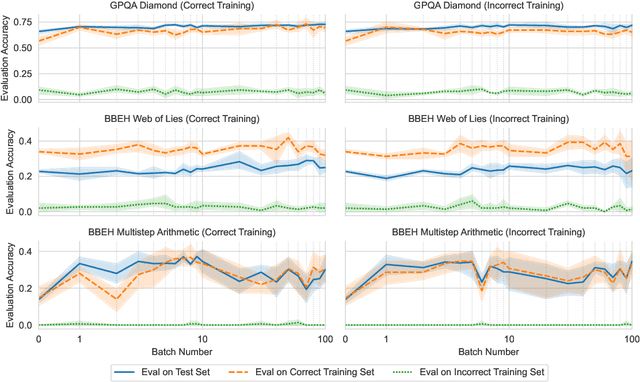
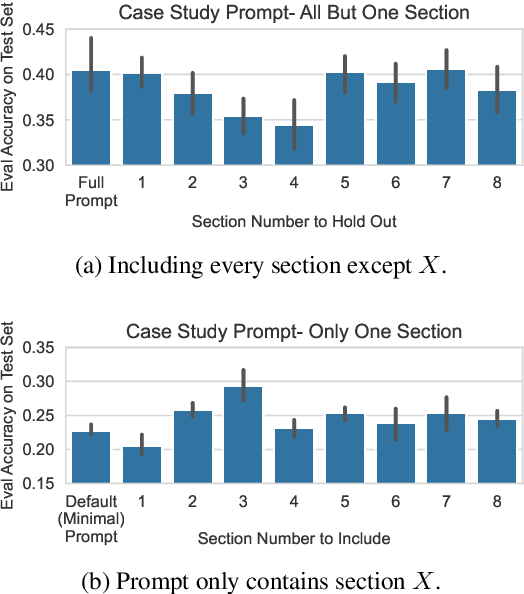
A well-engineered prompt can increase the performance of large language models; automatic prompt optimization techniques aim to increase performance without requiring human effort to tune the prompts. One leading class of prompt optimization techniques introduces the analogy of textual gradients. We investigate the behavior of these textual gradient methods through a series of experiments and case studies. While such methods often result in a performance improvement, our experiments suggest that the gradient analogy does not accurately explain their behavior. Our insights may inform the selection of prompt optimization strategies, and development of new approaches.
Approximately Aligned Decoding
Oct 01, 2024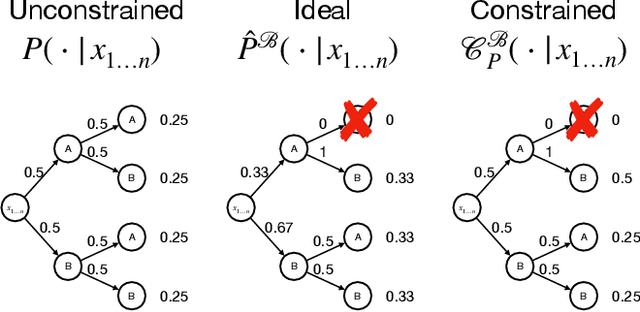
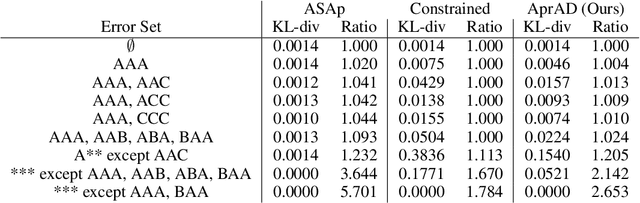

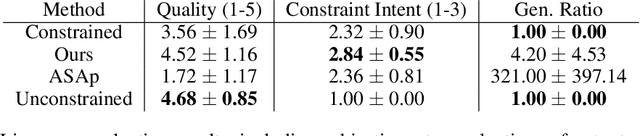
It is common to reject undesired outputs of Large Language Models (LLMs); however, current methods to do so require an excessive amount of computation, or severely distort the distribution of outputs. We present a method to balance the distortion of the output distribution with computational efficiency, allowing for the generation of long sequences of text with difficult-to-satisfy constraints, with less amplification of low probability outputs compared to existing methods. We show through a series of experiments that the task-specific performance of our method is comparable to methods that do not distort the output distribution, while being much more computationally efficient.
Hawkes Process Multi-armed Bandits for Disaster Search and Rescue
Apr 03, 2020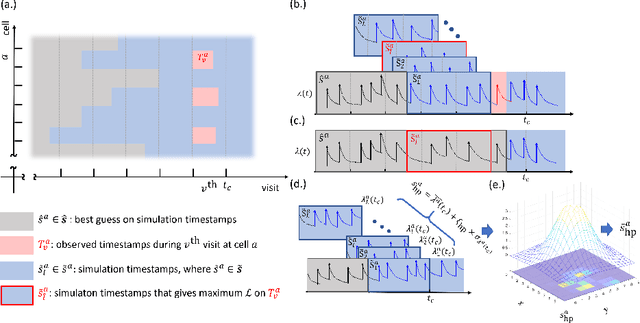
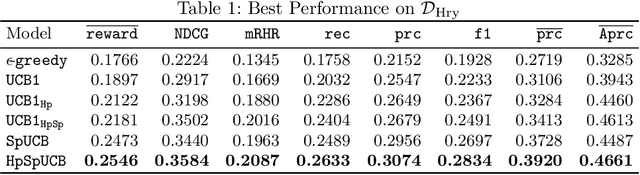
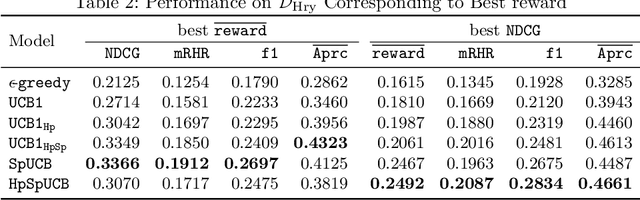
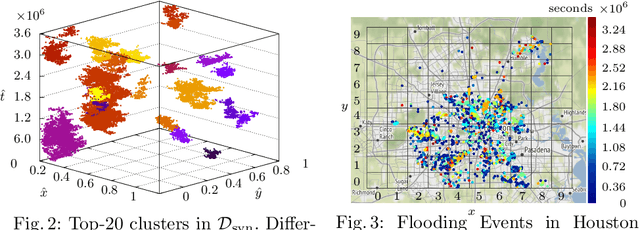
We propose a novel framework for integrating Hawkes processes with multi-armed bandit algorithms to solve spatio-temporal event forecasting and detection problems when data may be undersampled or spatially biased. In particular, we introduce an upper confidence bound algorithm using Bayesian spatial Hawkes process estimation for balancing the tradeoff between exploiting geographic regions where data has been collected and exploring geographic regions where data is unobserved. We first validate our model using simulated data and then apply it to the problem of disaster search and rescue using calls for service data from hurricane Harvey in 2017. Our model outperforms the state of the art baseline spatial MAB algorithms in terms of cumulative reward and several other ranking evaluation metrics.
Drug-drug interaction prediction based on co-medication patterns and graph matching
Feb 22, 2019
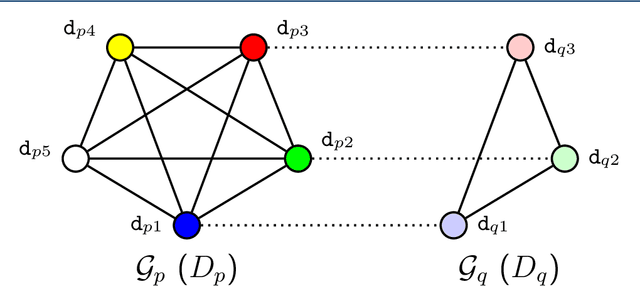
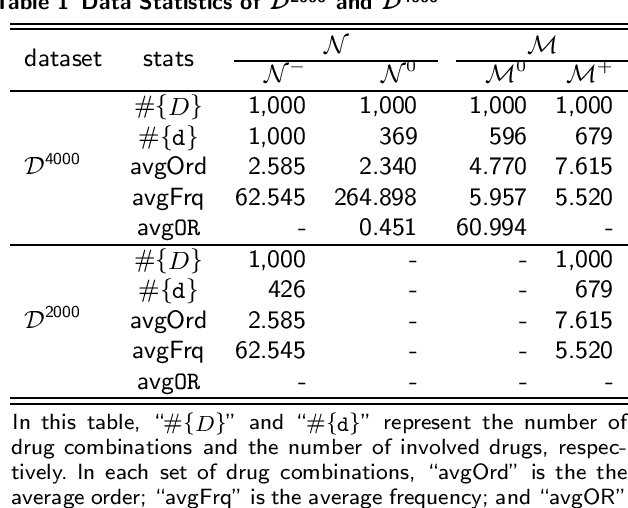
Background: The problem of predicting whether a drug combination of arbitrary orders is likely to induce adverse drug reactions is considered in this manuscript. Methods: Novel kernels over drug combinations of arbitrary orders are developed within support vector machines for the prediction. Graph matching methods are used in the novel kernels to measure the similarities among drug combinations, in which drug co-medication patterns are leveraged to measure single drug similarities. Results: The experimental results on a real-world dataset demonstrated that the new kernels achieve an area under the curve (AUC) value 0.912 for the prediction problem. Conclusions: The new methods with drug co-medication based single drug similarities can accurately predict whether a drug combination is likely to induce adverse drug reactions of interest. Keywords: drug-drug interaction prediction; drug combination similarity; co-medication; graph matching
Drug Recommendation toward Safe Polypharmacy
Mar 08, 2018
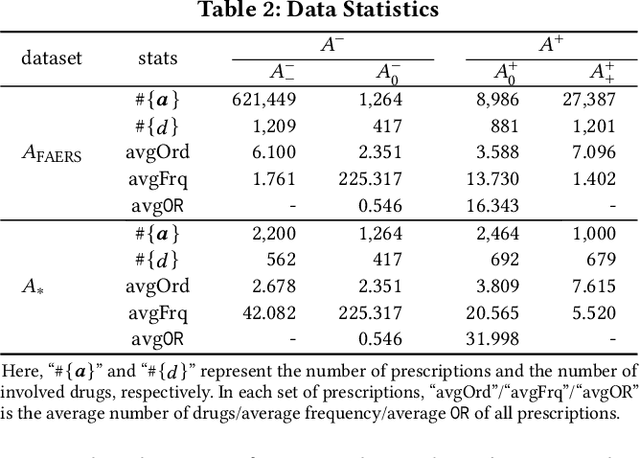
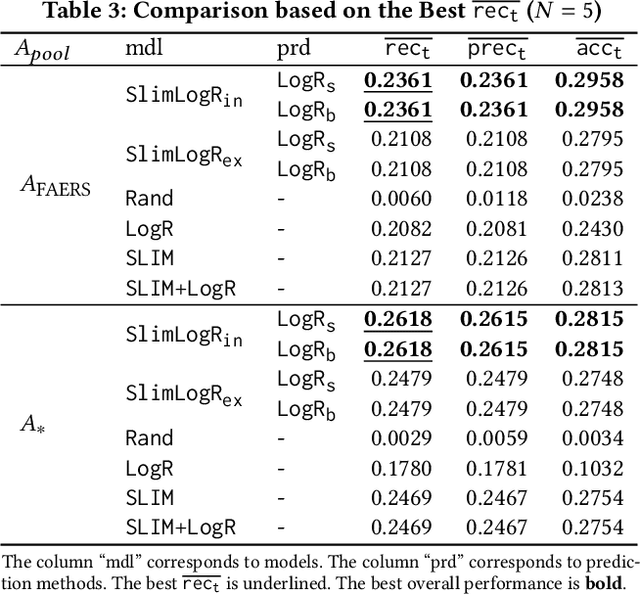
Adverse drug reactions (ADRs) induced from high-order drug-drug interactions (DDIs) due to polypharmacy represent a significant public health problem. In this paper, we formally formulate the to-avoid and safe (with respect to ADRs) drug recommendation problems when multiple drugs have been taken simultaneously. We develop a joint model with a recommendation component and an ADR label prediction component to recommend for a prescription a set of to-avoid drugs that will induce ADRs if taken together with the prescription. We also develop real drug-drug interaction datasets and corresponding evaluation protocols. Our experimental results on real datasets demonstrate the strong performance of the joint model compared to other baseline methods.