 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Spatiotemporal Point Processes: Trends and Challenges
Feb 13, 2025Spatiotemporal point processes (STPPs) are probabilistic models for events occurring in continuous space and time. Real-world event data often exhibit intricate dependencies and heterogeneous dynamics. By incorporating modern deep learning techniques, STPPs can model these complexities more effectively than traditional approaches. Consequently, the fusion of neural methods with STPPs has become an active and rapidly evolving research area. In this review, we categorize existing approaches, unify key design choices, and explain the challenges of working with this data modality. We further highlight emerging trends and diverse application domains. Finally, we identify open challenges and gaps in the literature.
Time-to-event modeling of subreddits transitions to r/SuicideWatch
Feb 13, 2023



Recent data mining research has focused on the analysis of social media text, content and networks to identify suicide ideation online. However, there has been limited research on the temporal dynamics of users and suicide ideation. In this work, we use time-to-event modeling to identify which subreddits have a higher association with users transitioning to posting on r/suicidewatch. For this purpose we use a Cox proportional hazards model that takes as input text and subreddit network features and outputs a probability distribution for the time until a Reddit user posts on r/suicidewatch. In our analysis we find a number of statistically significant features that predict earlier transitions to r/suicidewatch. While some patterns match existing intuition, for example r/depression is positively associated with posting sooner on r/suicidewatch, others were more surprising (for example, the average time between a high risk post on r/Wishlist and a post on r/suicidewatch is 10.2 days). We then discuss these results as well as directions for future research.
Fine-Grained Zero-Shot Learning with DNA as Side Information
Sep 29, 2021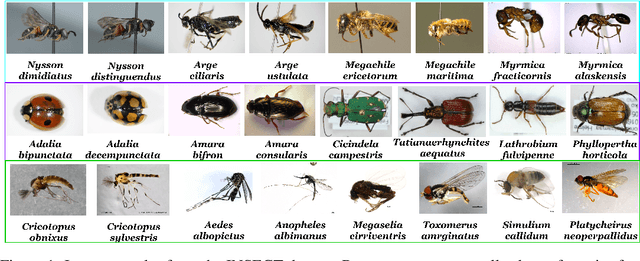
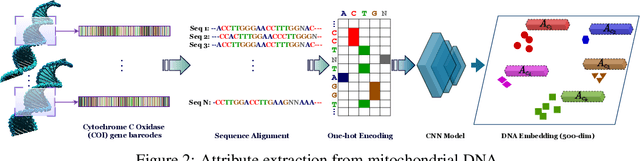
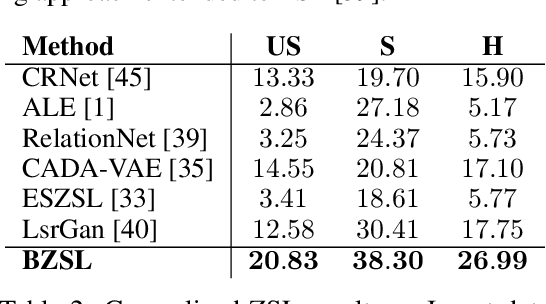
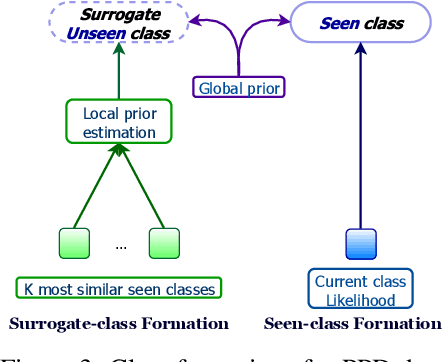
Fine-grained zero-shot learning task requires some form of side-information to transfer discriminative information from seen to unseen classes. As manually annotated visual attributes are extremely costly and often impractical to obtain for a large number of classes, in this study we use DNA as side information for the first time for fine-grained zero-shot classification of species. Mitochondrial DNA plays an important role as a genetic marker in evolutionary biology and has been used to achieve near-perfect accuracy in the species classification of living organisms. We implement a simple hierarchical Bayesian model that uses DNA information to establish the hierarchy in the image space and employs local priors to define surrogate classes for unseen ones. On the benchmark CUB dataset, we show that DNA can be equally promising yet in general a more accessible alternative than word vectors as a side information. This is especially important as obtaining robust word representations for fine-grained species names is not a practicable goal when information about these species in free-form text is limited. On a newly compiled fine-grained insect dataset that uses DNA information from over a thousand species, we show that the Bayesian approach outperforms state-of-the-art by a wide margin.
Point Process Modeling of Drug Overdoses with Heterogeneous and Missing Data
Oct 12, 2020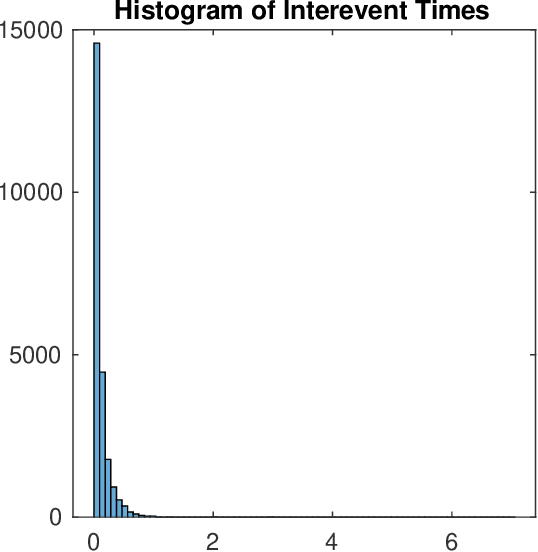
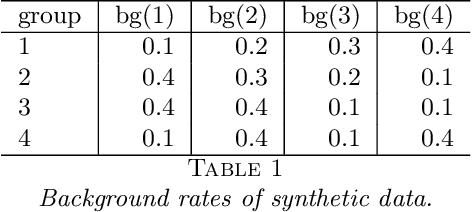
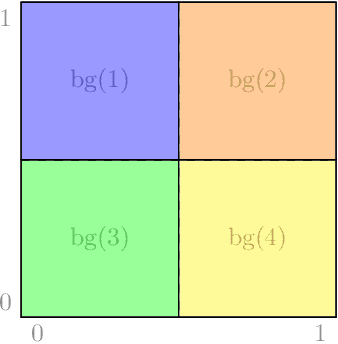
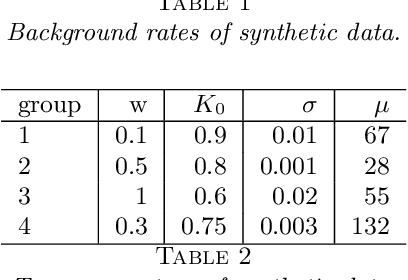
Opioid overdose rates have increased in the United States over the past decade and reflect a major public health crisis. Modeling and prediction of drug and opioid hotspots, where a high percentage of events fall in a small percentage of space-time, could help better focus limited social and health services. In this work we present a spatial-temporal point process model for drug overdose clustering. The data input into the model comes from two heterogeneous sources: 1) high volume emergency medical calls for service (EMS) records containing location and time, but no information on the type of non-fatal overdose and 2) fatal overdose toxicology reports from the coroner containing location and high-dimensional information from the toxicology screen on the drugs present at the time of death. We first use non-negative matrix factorization to cluster toxicology reports into drug overdose categories and we then develop an EM algorithm for integrating the two heterogeneous data sets, where the mark corresponding to overdose category is inferred for the EMS data and the high volume EMS data is used to more accurately predict drug overdose death hotspots. We apply the algorithm to drug overdose data from Indianapolis, showing that the point process defined on the integrated data outperforms point processes that use only homogeneous EMS (AUC improvement .72 to .8) or coroner data (AUC improvement .81 to .85).We also investigate the extent to which overdoses are contagious, as a function of the type of overdose, while controlling for exogenous fluctuations in the background rate that might also contribute to clustering. We find that drug and opioid overdose deaths exhibit significant excitation, with branching ratio ranging from .72 to .98.
Hawkes Process Multi-armed Bandits for Disaster Search and Rescue
Apr 03, 2020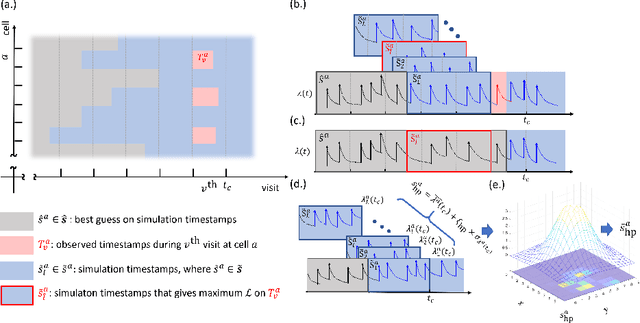
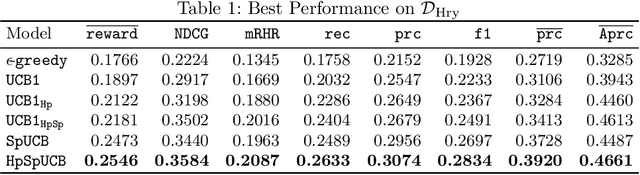
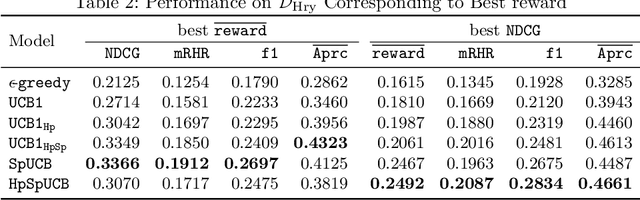
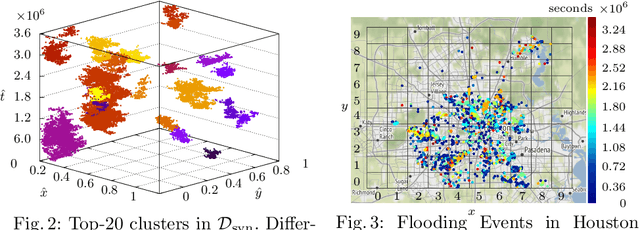
We propose a novel framework for integrating Hawkes processes with multi-armed bandit algorithms to solve spatio-temporal event forecasting and detection problems when data may be undersampled or spatially biased. In particular, we introduce an upper confidence bound algorithm using Bayesian spatial Hawkes process estimation for balancing the tradeoff between exploiting geographic regions where data has been collected and exploring geographic regions where data is unobserved. We first validate our model using simulated data and then apply it to the problem of disaster search and rescue using calls for service data from hurricane Harvey in 2017. Our model outperforms the state of the art baseline spatial MAB algorithms in terms of cumulative reward and several other ranking evaluation metrics.
Redditors in Recovery: Text Mining Reddit to Investigate Transitions into Drug Addiction
Mar 11, 2019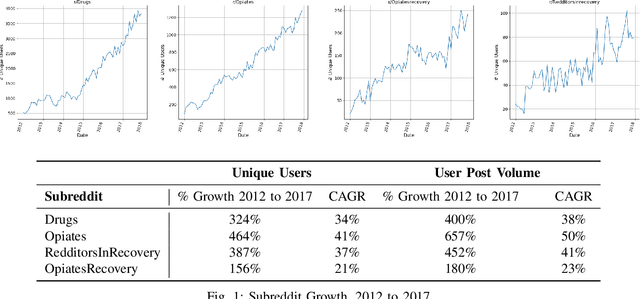
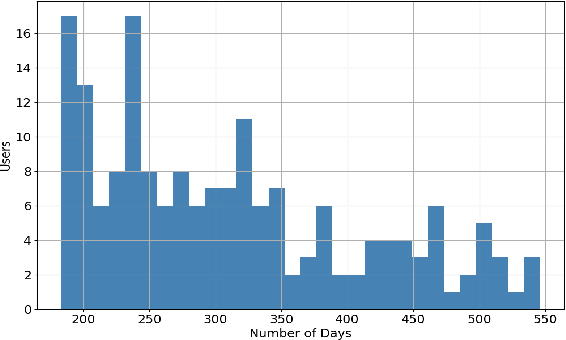
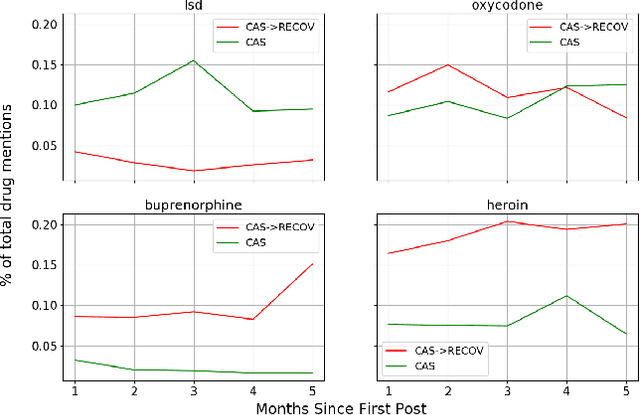
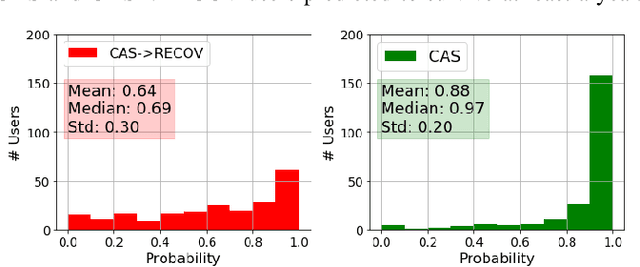
Increasing rates of opioid drug abuse and heightened prevalence of online support communities underscore the necessity of employing data mining techniques to better understand drug addiction using these rapidly developing online resources. In this work, we obtain data from Reddit, an online collection of forums, to gather insight into drug use/misuse using text data from users themselves. Specifically, using user posts, we trained 1) a binary classifier which predicts transitions from casual drug discussion forums to drug recovery forums and 2) a Cox regression model that outputs likelihoods of such transitions. In doing so, we found that utterances of select drugs and certain linguistic features contained in one's posts can help predict these transitions. Using unfiltered drug-related posts, our research delineates drugs that are associated with higher rates of transitions from recreational drug discussion to support/recovery discussion, offers insight into modern drug culture, and provides tools with potential applications in combating the opioid crisis.
Coupled IGMM-GANs for deep multimodal anomaly detection in human mobility data
Sep 08, 2018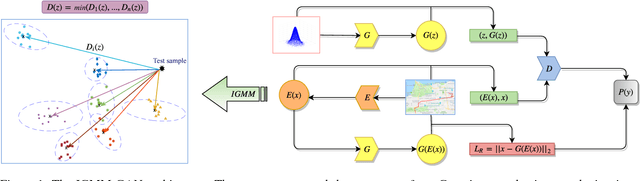

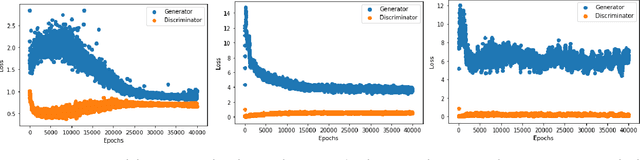
Detecting anomalous activity in human mobility data has a number of applications including road hazard sensing, telematic based insurance, and fraud detection in taxi services and ride sharing. In this paper we address two challenges that arise in the study of anomalous human trajectories: 1) a lack of ground truth data on what defines an anomaly and 2) the dependence of existing methods on significant pre-processing and feature engineering. While generative adversarial networks seem like a natural fit for addressing these challenges, we find that existing GAN based anomaly detection algorithms perform poorly due to their inability to handle multimodal patterns. For this purpose we introduce an infinite Gaussian mixture model coupled with (bi-directional) generative adversarial networks, IGMM-GAN, that is able to generate synthetic, yet realistic, human mobility data and simultaneously facilitates multimodal anomaly detection. Through estimation of a generative probability density on the space of human trajectories, we are able to generate realistic synthetic datasets that can be used to benchmark existing anomaly detection methods. The estimated multimodal density also allows for a natural definition of outlier that we use for detecting anomalous trajectories. We illustrate our methodology and its improvement over existing GAN anomaly detection on several human mobility datasets, along with MNIST.