 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Zero-Shot Learning with DNA as Side Information
Sep 29, 2021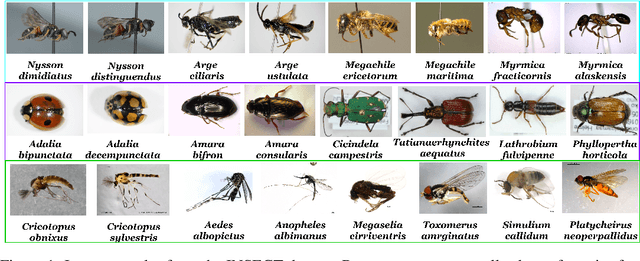
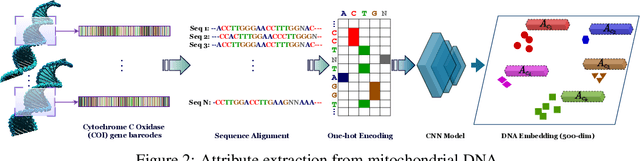
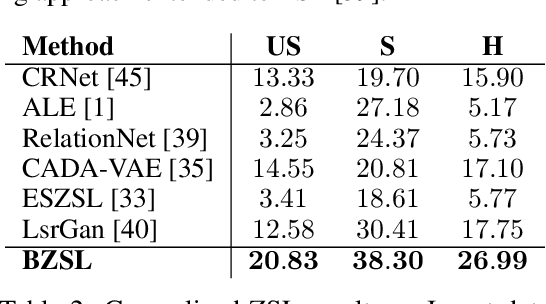
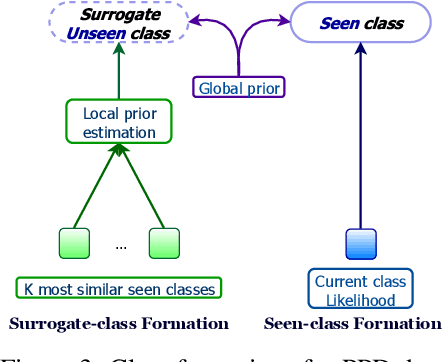
Fine-grained zero-shot learning task requires some form of side-information to transfer discriminative information from seen to unseen classes. As manually annotated visual attributes are extremely costly and often impractical to obtain for a large number of classes, in this study we use DNA as side information for the first time for fine-grained zero-shot classification of species. Mitochondrial DNA plays an important role as a genetic marker in evolutionary biology and has been used to achieve near-perfect accuracy in the species classification of living organisms. We implement a simple hierarchical Bayesian model that uses DNA information to establish the hierarchy in the image space and employs local priors to define surrogate classes for unseen ones. On the benchmark CUB dataset, we show that DNA can be equally promising yet in general a more accessible alternative than word vectors as a side information. This is especially important as obtaining robust word representations for fine-grained species names is not a practicable goal when information about these species in free-form text is limited. On a newly compiled fine-grained insect dataset that uses DNA information from over a thousand species, we show that the Bayesian approach outperforms state-of-the-art by a wide margin.
Gradient Boosting Neural Networks: GrowNet
Feb 19, 2020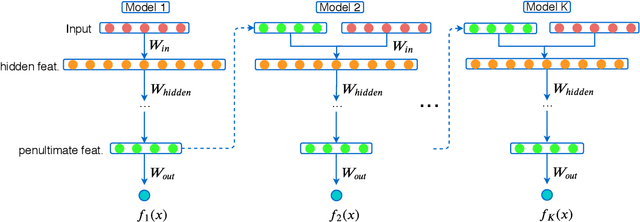
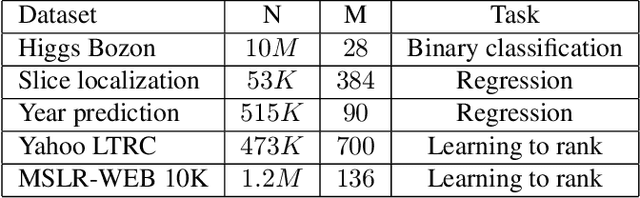

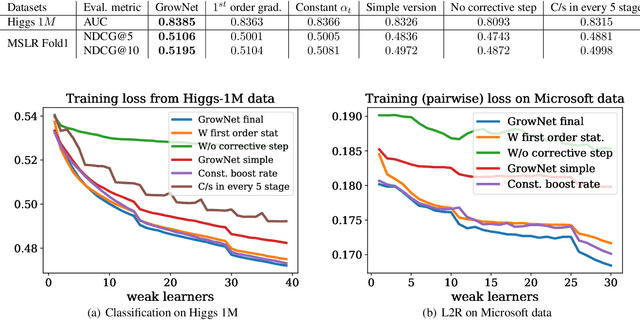
A novel gradient boosting framework is proposed where shallow neural networks are employed as "weak learners". General loss functions are considered under this unified framework with specific examples presented for classification, regression and learning to rank. A fully corrective step is incorporated to remedy the pitfall of greedy function approximation of classic gradient boosting decision tree. The proposed model rendered state-of-the-art results in all three tasks on multiple datasets. An ablation study is performed to shed light on the effect of each model components and model hyperparameters.
Open Set Authorship Attribution toward Demystifying Victorian Periodicals
Dec 17, 2019



Existing research in computational authorship attribution (AA) has primarily focused on attribution tasks with a limited number of authors in a closed-set configuration. This restricted set-up is far from being realistic in dealing with highly entangled real-world AA tasks that involve a large number of candidate authors for attribution during test time. In this paper, we study AA in historical texts using anew data set compiled from the Victorian literature. We investigate the predictive capacity of most common English words in distinguishing writings of most prominent Victorian novelists. We challenged the closed-set classification assumption and discussed the limitations of standard machine learning techniques in dealing with the open set AA task. Our experiments suggest that a linear classifier can achieve near perfect attribution accuracy under closed set assumption yet, the need for more robust approaches becomes evident once a large candidate pool has to be considered in the open-set classification setting.
Bayesian Zero-Shot Learning
Jul 25, 2019

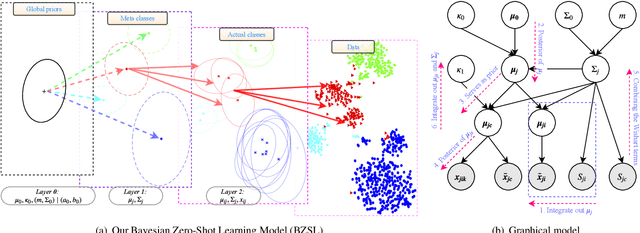

Object classes that surround us have a natural tendency to emerge at varying levels of abstraction. We propose a Bayesian approach to zero-shot learning (ZSL) that introduces the notion of meta-classes and implements a Bayesian hierarchy around these classes to effectively blend data likelihood with local and global priors. Local priors driven by data from seen classes, i.e. classes that are available at training time, become instrumental in recovering unseen classes, i.e. classes that are missing at training time, in a generalized ZSL setting. Hyperparameters of the Bayesian model offer a convenient way to optimize the trade-off between seen and unseen class accuracy in addition to guiding other aspects of model fitting. We conduct experiments on seven benchmark datasets including the large scale ImageNet and show that our model improves the current state of the art in the challenging generalized ZSL setting.
Coupled IGMM-GANs for deep multimodal anomaly detection in human mobility data
Sep 08, 2018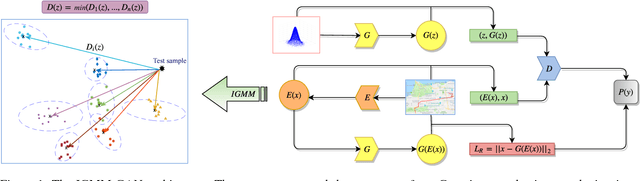

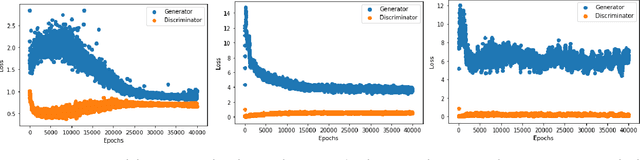
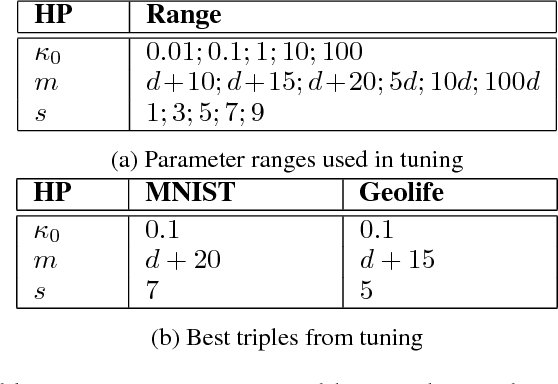
Detecting anomalous activity in human mobility data has a number of applications including road hazard sensing, telematic based insurance, and fraud detection in taxi services and ride sharing. In this paper we address two challenges that arise in the study of anomalous human trajectories: 1) a lack of ground truth data on what defines an anomaly and 2) the dependence of existing methods on significant pre-processing and feature engineering. While generative adversarial networks seem like a natural fit for addressing these challenges, we find that existing GAN based anomaly detection algorithms perform poorly due to their inability to handle multimodal patterns. For this purpose we introduce an infinite Gaussian mixture model coupled with (bi-directional) generative adversarial networks, IGMM-GAN, that is able to generate synthetic, yet realistic, human mobility data and simultaneously facilitates multimodal anomaly detection. Through estimation of a generative probability density on the space of human trajectories, we are able to generate realistic synthetic datasets that can be used to benchmark existing anomaly detection methods. The estimated multimodal density also allows for a natural definition of outlier that we use for detecting anomalous trajectories. We illustrate our methodology and its improvement over existing GAN anomaly detection on several human mobility datasets, along with MNIST.