 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthTextEval: Synthetic Text Data Generation and Evaluation for High-Stakes Domains
Jul 09, 2025We present SynthTextEval, a toolkit for conducting comprehensive evaluations of synthetic text. The fluency of large language model (LLM) outputs has made synthetic text potentially viable for numerous applications, such as reducing the risks of privacy violations in the development and deployment of AI systems in high-stakes domains. Realizing this potential, however, requires principled consistent evaluations of synthetic data across multiple dimensions: its utility in downstream systems, the fairness of these systems, the risk of privacy leakage, general distributional differences from the source text, and qualitative feedback from domain experts. SynthTextEval allows users to conduct evaluations along all of these dimensions over synthetic data that they upload or generate using the toolkit's generation module. While our toolkit can be run over any data, we highlight its functionality and effectiveness over datasets from two high-stakes domains: healthcare and law. By consolidating and standardizing evaluation metrics, we aim to improve the viability of synthetic text, and in-turn, privacy-preservation in AI development.
Improving Equity in Health Modeling with GPT4-Turbo Generated Synthetic Data: A Comparative Study
Dec 20, 2024
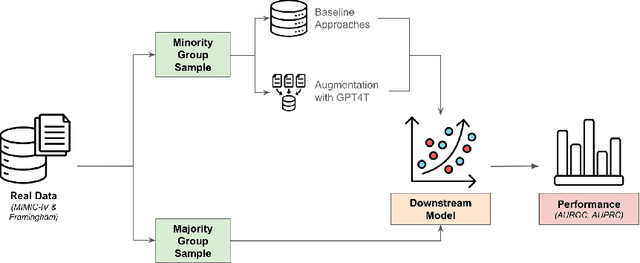
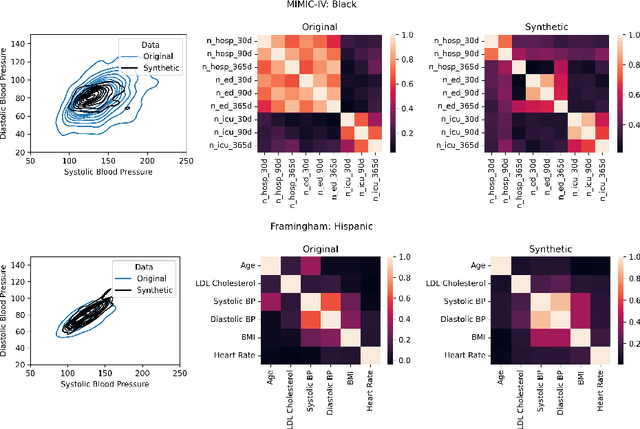

Objective. Demographic groups are often represented at different rates in medical datasets. These differences can create bias in machine learning algorithms, with higher levels of performance for better-represented groups. One promising solution to this problem is to generate synthetic data to mitigate potential adverse effects of non-representative data sets. Methods. We build on recent advances in LLM-based synthetic data generation to create a pipeline where the synthetic data is generated separately for each demographic group. We conduct our study using MIMIC-IV and Framingham "Offspring and OMNI-1 Cohorts" datasets. We prompt GPT4-Turbo to create group-specific data, providing training examples and the dataset context. An exploratory analysis is conducted to ascertain the quality of the generated data. We then evaluate the utility of the synthetic data for augmentation of a training dataset in a downstream machine learning task, focusing specifically on model performance metrics across groups. Results. The performance of GPT4-Turbo augmentation is generally superior but not always. In the majority of experiments our method outperforms standard modeling baselines, however, prompting GPT-4-Turbo to produce data specific to a group provides little to no additional benefit over a prompt that does not specify the group. Conclusion. We developed a method for using LLMs out-of-the-box to synthesize group-specific data to address imbalances in demographic representation in medical datasets. As another "tool in the toolbox", this method can improve model fairness and thus health equity. More research is needed to understand the conditions under which LLM generated synthetic data is useful for non-representative medical data sets.
DemOpts: Fairness corrections in COVID-19 case prediction models
May 15, 2024



COVID-19 forecasting models have been used to inform decision making around resource allocation and intervention decisions e.g., hospital beds or stay-at-home orders. State of the art deep learning models often use multimodal data such as mobility or socio-demographic data to enhance COVID-19 case prediction models. Nevertheless, related work has revealed under-reporting bias in COVID-19 cases as well as sampling bias in mobility data for certain minority racial and ethnic groups, which could in turn affect the fairness of the COVID-19 predictions along race labels. In this paper, we show that state of the art deep learning models output mean prediction errors that are significantly different across racial and ethnic groups; and which could, in turn, support unfair policy decisions. We also propose a novel de-biasing method, DemOpts, to increase the fairness of deep learning based forecasting models trained on potentially biased datasets. Our results show that DemOpts can achieve better error parity that other state of the art de-biasing approaches, thus effectively reducing the differences in the mean error distributions across more racial and ethnic groups.
Coupled IGMM-GANs for deep multimodal anomaly detection in human mobility data
Sep 08, 2018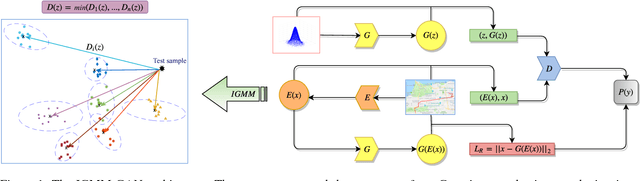

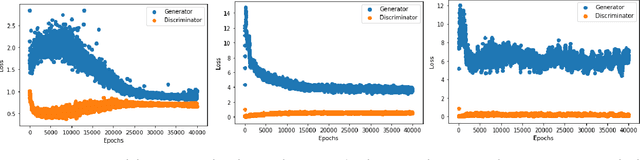
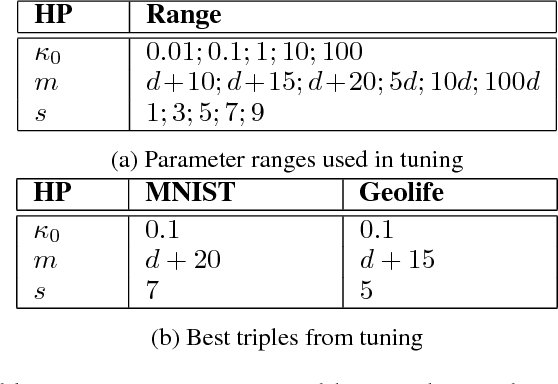
Detecting anomalous activity in human mobility data has a number of applications including road hazard sensing, telematic based insurance, and fraud detection in taxi services and ride sharing. In this paper we address two challenges that arise in the study of anomalous human trajectories: 1) a lack of ground truth data on what defines an anomaly and 2) the dependence of existing methods on significant pre-processing and feature engineering. While generative adversarial networks seem like a natural fit for addressing these challenges, we find that existing GAN based anomaly detection algorithms perform poorly due to their inability to handle multimodal patterns. For this purpose we introduce an infinite Gaussian mixture model coupled with (bi-directional) generative adversarial networks, IGMM-GAN, that is able to generate synthetic, yet realistic, human mobility data and simultaneously facilitates multimodal anomaly detection. Through estimation of a generative probability density on the space of human trajectories, we are able to generate realistic synthetic datasets that can be used to benchmark existing anomaly detection methods. The estimated multimodal density also allows for a natural definition of outlier that we use for detecting anomalous trajectories. We illustrate our methodology and its improvement over existing GAN anomaly detection on several human mobility datasets, along with MNIST.