 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Zero-Shot Learning with DNA as Side Information
Sep 29, 2021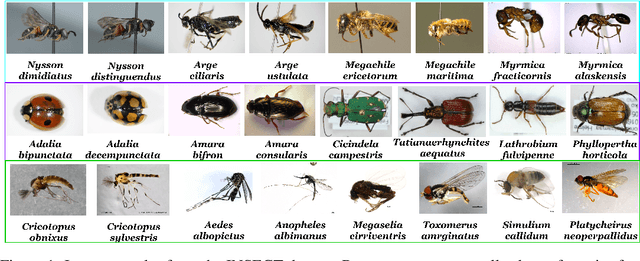
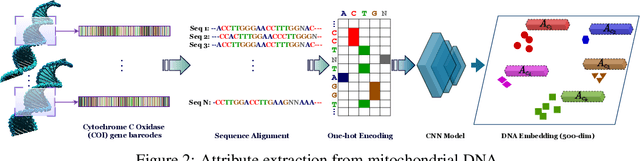
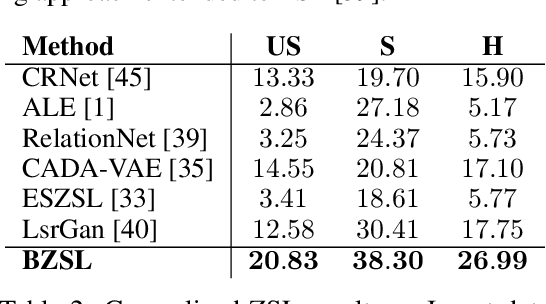
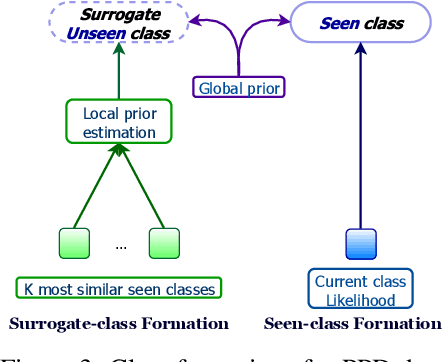
Fine-grained zero-shot learning task requires some form of side-information to transfer discriminative information from seen to unseen classes. As manually annotated visual attributes are extremely costly and often impractical to obtain for a large number of classes, in this study we use DNA as side information for the first time for fine-grained zero-shot classification of species. Mitochondrial DNA plays an important role as a genetic marker in evolutionary biology and has been used to achieve near-perfect accuracy in the species classification of living organisms. We implement a simple hierarchical Bayesian model that uses DNA information to establish the hierarchy in the image space and employs local priors to define surrogate classes for unseen ones. On the benchmark CUB dataset, we show that DNA can be equally promising yet in general a more accessible alternative than word vectors as a side information. This is especially important as obtaining robust word representations for fine-grained species names is not a practicable goal when information about these species in free-form text is limited. On a newly compiled fine-grained insect dataset that uses DNA information from over a thousand species, we show that the Bayesian approach outperforms state-of-the-art by a wide margin.
Open Set Authorship Attribution toward Demystifying Victorian Periodicals
Dec 17, 2019



Existing research in computational authorship attribution (AA) has primarily focused on attribution tasks with a limited number of authors in a closed-set configuration. This restricted set-up is far from being realistic in dealing with highly entangled real-world AA tasks that involve a large number of candidate authors for attribution during test time. In this paper, we study AA in historical texts using anew data set compiled from the Victorian literature. We investigate the predictive capacity of most common English words in distinguishing writings of most prominent Victorian novelists. We challenged the closed-set classification assumption and discussed the limitations of standard machine learning techniques in dealing with the open set AA task. Our experiments suggest that a linear classifier can achieve near perfect attribution accuracy under closed set assumption yet, the need for more robust approaches becomes evident once a large candidate pool has to be considered in the open-set classification setting.
Machine-Learning-Driven New Geologic Discoveries at Mars Rover Landing Sites: Jezero and NE Syrtis
Sep 05, 2019



A hierarchical Bayesian classifier is trained at pixel scale with spectral data from the CRISM (Compact Reconnaissance Imaging Spectrometer for Mars) imagery. Its utility in detecting rare phases is demonstrated with new geologic discoveries near the Mars-2020 rover landing site. Akaganeite is found in sediments on the Jezero crater floor and in fluvial deposits at NE Syrtis. Jarosite and silica are found on the Jezero crater floor while chlorite-smectite and Al phyllosilicates are found in the Jezero crater walls. These detections point to a multi-stage, multi-chemistry history of water in Jezero crater and the surrounding region and provide new information for guiding the Mars-2020 rover's landed exploration. In particular, the akaganeite, silica, and jarosite in the floor deposits suggest either a later episode of salty, Fe-rich waters that post-date Jezero delta or groundwater alteration of portions of the Jezero sedimentary sequence.
Bayesian Nonparametrics for Non-exhaustive Learning
Aug 26, 2019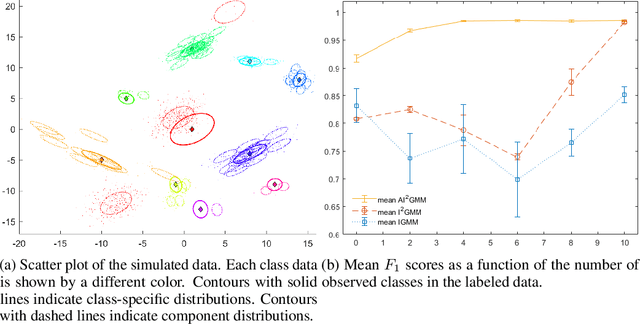
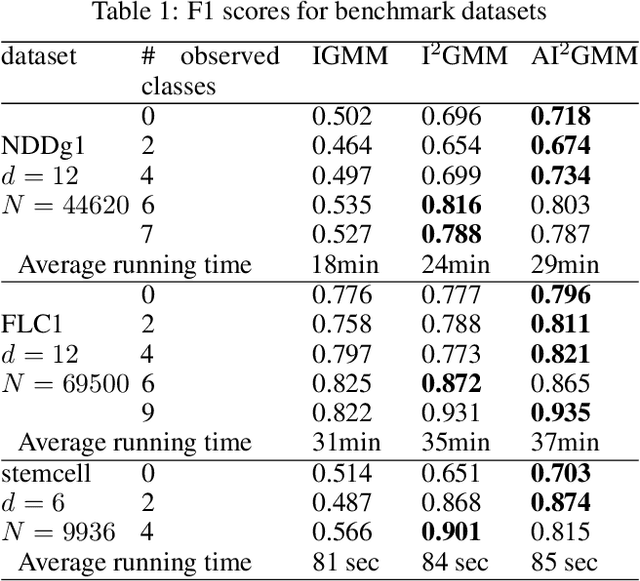
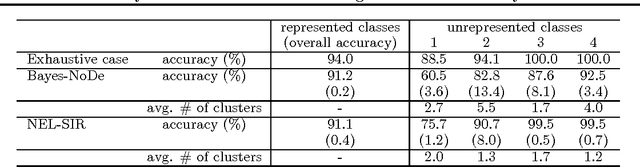
Non-exhaustive learning (NEL) is an emerging machine-learning paradigm designed to confront the challenge of non-stationary environments characterized by anon-exhaustive training sets lacking full information about the available classes.Unlike traditional supervised learning that relies on fixed models, NEL utilizes self-adjusting machine learning to better accommodate the non-stationary nature of the real-world problem, which is at the root of many recently discovered limitations of deep learning. Some of these hurdles led to a surge of interest in several research areas relevant to NEL such as open set classification or zero-shot learning. The presented study which has been motivated by two important applications proposes a NEL algorithm built on a highly flexible, doubly non-parametric Bayesian Gaussian mixture model that can grow arbitrarily large in terms of the number of classes and their components. We report several experiments that demonstrate the promising performance of the introduced model for NEL.
Bayesian Zero-Shot Learning
Jul 25, 2019

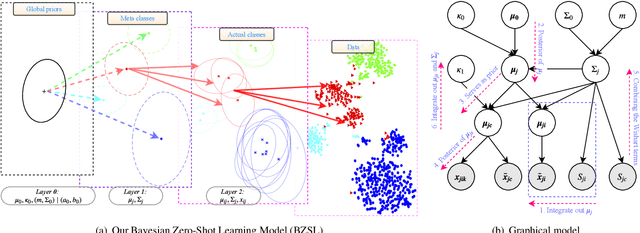

Object classes that surround us have a natural tendency to emerge at varying levels of abstraction. We propose a Bayesian approach to zero-shot learning (ZSL) that introduces the notion of meta-classes and implements a Bayesian hierarchy around these classes to effectively blend data likelihood with local and global priors. Local priors driven by data from seen classes, i.e. classes that are available at training time, become instrumental in recovering unseen classes, i.e. classes that are missing at training time, in a generalized ZSL setting. Hyperparameters of the Bayesian model offer a convenient way to optimize the trade-off between seen and unseen class accuracy in addition to guiding other aspects of model fitting. We conduct experiments on seven benchmark datasets including the large scale ImageNet and show that our model improves the current state of the art in the challenging generalized ZSL setting.
Bayesian Nonexhaustive Learning for Online Discovery and Modeling of Emerging Classes
Jun 18, 2012
We present a framework for online inference in the presence of a nonexhaustively defined set of classes that incorporates supervised classification with class discovery and modeling. A Dirichlet process prior (DPP) model defined over class distributions ensures that both known and unknown class distributions originate according to a common base distribution. In an attempt to automatically discover potentially interesting class formations, the prior model is coupled with a suitably chosen data model, and sequential Monte Carlo sampling is used to perform online inference. Our research is driven by a biodetection application, where a new class of pathogen may suddenly appear, and the rapid increase in the number of samples originating from this class indicates the onset of an outbreak.