 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatLLM: A Dataset for Evaluating the Performance of Large Language Models in Statistical Analysis
Feb 24, 2025
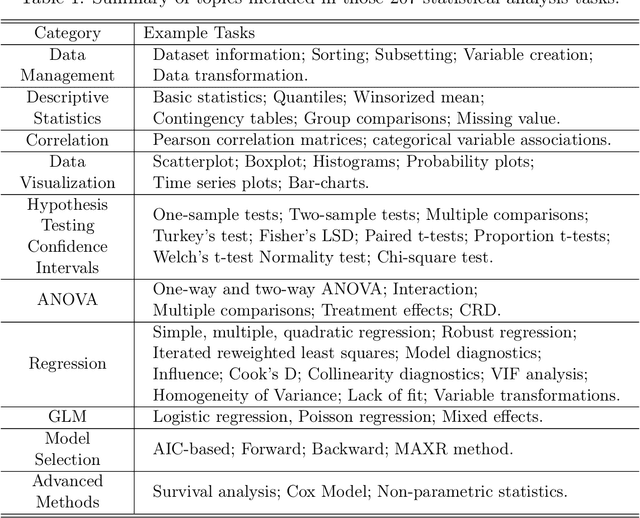
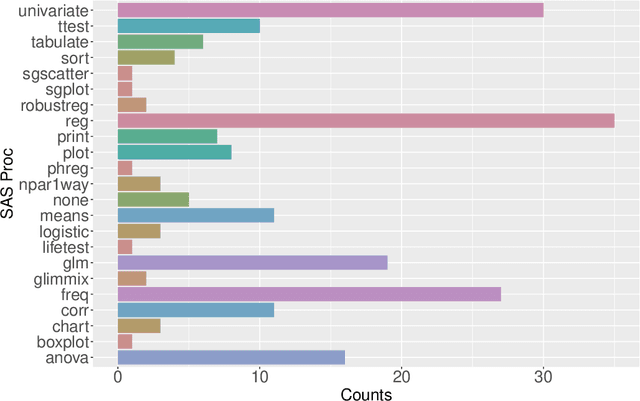
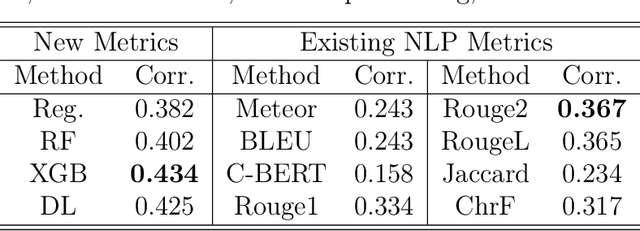
The coding capabilities of large language models (LLMs) have opened up new opportunities for automatic statistical analysis in machine learning and data science. However, before their widespread adoption, it is crucial to assess the accuracy of code generated by LLMs. A major challenge in this evaluation lies in the absence of a benchmark dataset for statistical code (e.g., SAS and R). To fill in this gap, this paper introduces StatLLM, an open-source dataset for evaluating the performance of LLMs in statistical analysis. The StatLLM dataset comprises three key components: statistical analysis tasks, LLM-generated SAS code, and human evaluation scores. The first component includes statistical analysis tasks spanning a variety of analyses and datasets, providing problem descriptions, dataset details, and human-verified SAS code. The second component features SAS code generated by ChatGPT 3.5, ChatGPT 4.0, and Llama 3.1 for those tasks. The third component contains evaluation scores from human experts in assessing the correctness, effectiveness, readability, executability, and output accuracy of the LLM-generated code. We also illustrate the unique potential of the established benchmark dataset for (1) evaluating and enhancing natural language processing metrics, (2) assessing and improving LLM performance in statistical coding, and (3) developing and testing of next-generation statistical software - advancements that are crucial for data science and machine learning research.
Time-to-event modeling of subreddits transitions to r/SuicideWatch
Feb 13, 2023



Recent data mining research has focused on the analysis of social media text, content and networks to identify suicide ideation online. However, there has been limited research on the temporal dynamics of users and suicide ideation. In this work, we use time-to-event modeling to identify which subreddits have a higher association with users transitioning to posting on r/suicidewatch. For this purpose we use a Cox proportional hazards model that takes as input text and subreddit network features and outputs a probability distribution for the time until a Reddit user posts on r/suicidewatch. In our analysis we find a number of statistically significant features that predict earlier transitions to r/suicidewatch. While some patterns match existing intuition, for example r/depression is positively associated with posting sooner on r/suicidewatch, others were more surprising (for example, the average time between a high risk post on r/Wishlist and a post on r/suicidewatch is 10.2 days). We then discuss these results as well as directions for future research.
Point Process Modeling of Drug Overdoses with Heterogeneous and Missing Data
Oct 12, 2020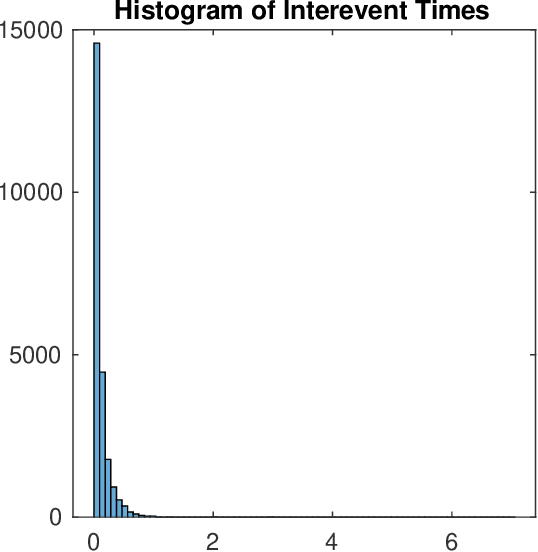
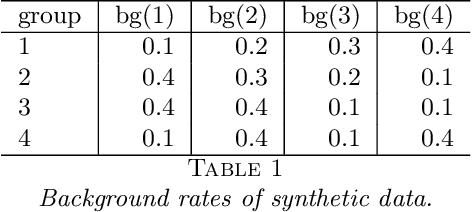
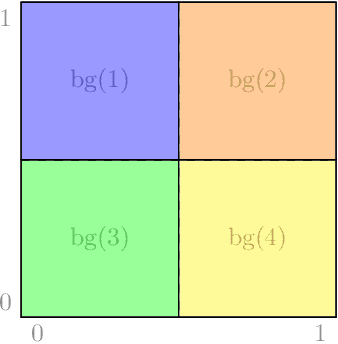
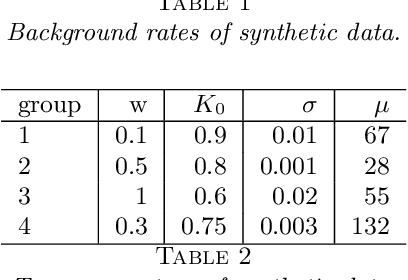
Opioid overdose rates have increased in the United States over the past decade and reflect a major public health crisis. Modeling and prediction of drug and opioid hotspots, where a high percentage of events fall in a small percentage of space-time, could help better focus limited social and health services. In this work we present a spatial-temporal point process model for drug overdose clustering. The data input into the model comes from two heterogeneous sources: 1) high volume emergency medical calls for service (EMS) records containing location and time, but no information on the type of non-fatal overdose and 2) fatal overdose toxicology reports from the coroner containing location and high-dimensional information from the toxicology screen on the drugs present at the time of death. We first use non-negative matrix factorization to cluster toxicology reports into drug overdose categories and we then develop an EM algorithm for integrating the two heterogeneous data sets, where the mark corresponding to overdose category is inferred for the EMS data and the high volume EMS data is used to more accurately predict drug overdose death hotspots. We apply the algorithm to drug overdose data from Indianapolis, showing that the point process defined on the integrated data outperforms point processes that use only homogeneous EMS (AUC improvement .72 to .8) or coroner data (AUC improvement .81 to .85).We also investigate the extent to which overdoses are contagious, as a function of the type of overdose, while controlling for exogenous fluctuations in the background rate that might also contribute to clustering. We find that drug and opioid overdose deaths exhibit significant excitation, with branching ratio ranging from .72 to .98.