 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForecasting Application Counts in Talent Acquisition Platforms: Harnessing Multimodal Signals using LMs
Nov 19, 2024As recruitment and talent acquisition have become more and more competitive, recruitment firms have become more sophisticated in using machine learning (ML) methodologies for optimizing their day to day activities. But, most of published ML based methodologies in this area have been limited to the tasks like candidate matching, job to skill matching, job classification and normalization. In this work, we discuss a novel task in the recruitment domain, namely, application count forecasting, motivation of which comes from designing of effective outreach activities to attract qualified applicants. We show that existing auto-regressive based time series forecasting methods perform poorly for this task. Henceforth, we propose a multimodal LM-based model which fuses job-posting metadata of various modalities through a simple encoder. Experiments from large real-life datasets from CareerBuilder LLC show the effectiveness of the proposed method over existing state-of-the-art methods.
Binder: Hierarchical Concept Representation through Order Embedding of Binary Vectors
Apr 16, 2024For natural language understanding and generation, embedding concepts using an order-based representation is an essential task. Unlike traditional point vector based representation, an order-based representation imposes geometric constraints on the representation vectors for explicitly capturing various semantic relationships that may exist between a pair of concepts. In existing literature, several approaches on order-based embedding have been proposed, mostly focusing on capturing hierarchical relationships; examples include vectors in Euclidean space, complex, Hyperbolic, order, and Box Embedding. Box embedding creates region-based rich representation of concepts, but along the process it sacrifices simplicity, requiring a custom-made optimization scheme for learning the representation. Hyperbolic embedding improves embedding quality by exploiting the ever-expanding property of Hyperbolic space, but it also suffers from the same fate as box embedding as gradient descent like optimization is not simple in the Hyperbolic space. In this work, we propose Binder, a novel approach for order-based representation. Binder uses binary vectors for embedding, so the embedding vectors are compact with an order of magnitude smaller footprint than other methods. Binder uses a simple and efficient optimization scheme for learning representation vectors with a linear time complexity. Our comprehensive experimental results show that Binder is very accurate, yielding competitive results on the representation task. But Binder stands out from its competitors on the transitive closure link prediction task as it can learn concept embeddings just from the direct edges, whereas all existing order-based approaches rely on the indirect edges.
Robust Node Representation Learning via Graph Variational Diffusion Networks
Dec 18, 2023Node representation learning by using Graph Neural Networks (GNNs) has been widely explored. However, in recent years, compelling evidence has revealed that GNN-based node representation learning can be substantially deteriorated by delicately-crafted perturbations in a graph structure. To learn robust node representation in the presence of perturbations, various works have been proposed to safeguard GNNs. Within these existing works, Bayesian label transition has been proven to be more effective, but this method is extensively reliant on a well-built prior distribution. The variational inference could address this limitation by sampling the latent node embedding from a Gaussian prior distribution. Besides, leveraging the Gaussian distribution (noise) in hidden layers is an appealing strategy to strengthen the robustness of GNNs. However, our experiments indicate that such a strategy can cause over-smoothing issues during node aggregation. In this work, we propose the Graph Variational Diffusion Network (GVDN), a new node encoder that effectively manipulates Gaussian noise to safeguard robustness on perturbed graphs while alleviating over-smoothing issues through two mechanisms: Gaussian diffusion and node embedding propagation. Thanks to these two mechanisms, our model can generate robust node embeddings for recovery. Specifically, we design a retraining mechanism using the generated node embedding to recover the performance of node classifications in the presence of perturbations. The experiments verify the effectiveness of our proposed model across six public datasets.
Force-directed graph embedding with hops distance
Sep 11, 2023Graph embedding has become an increasingly important technique for analyzing graph-structured data. By representing nodes in a graph as vectors in a low-dimensional space, graph embedding enables efficient graph processing and analysis tasks like node classification, link prediction, and visualization. In this paper, we propose a novel force-directed graph embedding method that utilizes the steady acceleration kinetic formula to embed nodes in a way that preserves graph topology and structural features. Our method simulates a set of customized attractive and repulsive forces between all node pairs with respect to their hop distance. These forces are then used in Newton's second law to obtain the acceleration of each node. The method is intuitive, parallelizable, and highly scalable. We evaluate our method on several graph analysis tasks and show that it achieves competitive performance compared to state-of-the-art unsupervised embedding techniques.
Robust Node Classification on Graphs: Jointly from Bayesian Label Transition and Topology-based Label Propagation
Aug 21, 2022
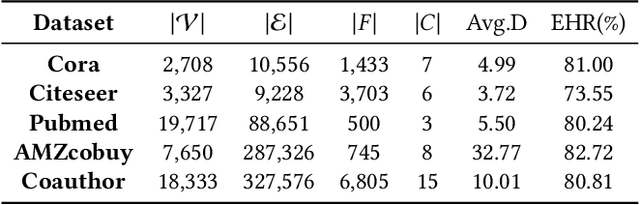

Node classification using Graph Neural Networks (GNNs) has been widely applied in various real-world scenarios. However, in recent years, compelling evidence emerges that the performance of GNN-based node classification may deteriorate substantially by topological perturbation, such as random connections or adversarial attacks. Various solutions, such as topological denoising methods and mechanism design methods, have been proposed to develop robust GNN-based node classifiers but none of these works can fully address the problems related to topological perturbations. Recently, the Bayesian label transition model is proposed to tackle this issue but its slow convergence may lead to inferior performance. In this work, we propose a new label inference model, namely LInDT, which integrates both Bayesian label transition and topology-based label propagation for improving the robustness of GNNs against topological perturbations. LInDT is superior to existing label transition methods as it improves the label prediction of uncertain nodes by utilizing neighborhood-based label propagation leading to better convergence of label inference. Besides, LIndT adopts asymmetric Dirichlet distribution as a prior, which also helps it to improve label inference. Extensive experiments on five graph datasets demonstrate the superiority of LInDT for GNN-based node classification under three scenarios of topological perturbations.
Informative Causality Extraction from Medical Literature via Dependency-tree based Patterns
Mar 13, 2022
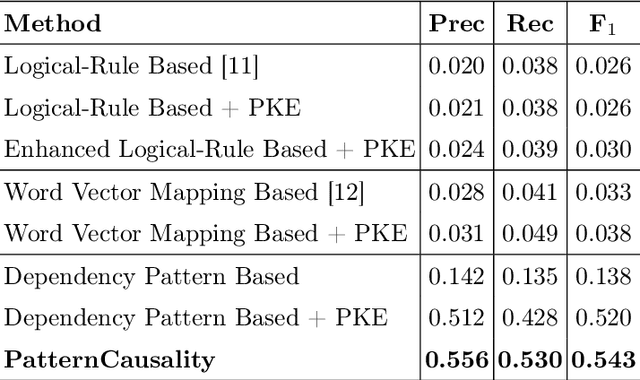
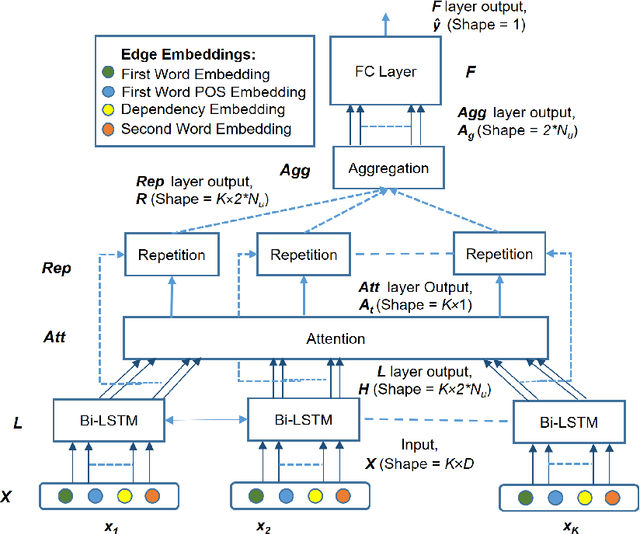
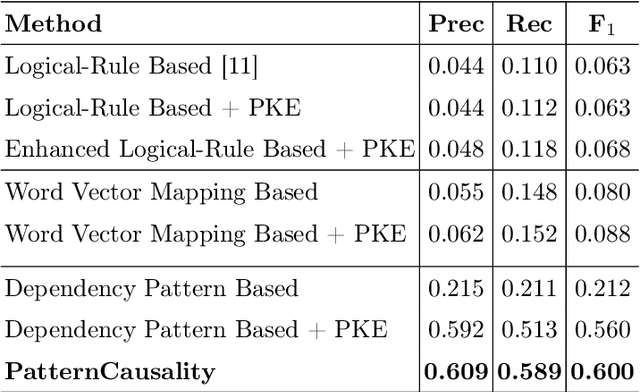
Extracting cause-effect entities from medical literature is an important task in medical information retrieval. A solution for solving this task can be used for compilation of various causality relations, such as, causality between disease and symptoms, between medications and side effects, between genes and diseases, etc. Existing solutions for extracting cause-effect entities work well for sentences where the cause and the effect phrases are name entities, single-word nouns, or noun phrases consisting of two to three words. Unfortunately, in medical literature, cause and effect phrases in a sentence are not simply nouns or noun phrases, rather they are complex phrases consisting of several words, and existing methods fail to correctly extract the cause and effect entities in such sentences. Partial extraction of cause and effect entities conveys poor quality, non informative, and often, contradictory facts, comparing to the one intended in the given sentence. In this work, we solve this problem by designing an unsupervised method for cause and effect phrase extraction, PatternCausality, which is specifically suitable for the medical literature. Our proposed approach first uses a collection of cause-effect dependency patterns as template to extract head words of cause and effect phrases and then it uses a novel phrase extraction method to obtain complete and meaningful cause and effect phrases from a sentence. Experiments on a cause-effect dataset built from sentences from PubMed articles show that for extracting cause and effect entities, PatternCausality is substantially better than the existing methods with an order of magnitude improvement in the F-score metric over the best of the existing methods.
* 22 pages without comment
ORDSIM: Ordinal Regression for E-Commerce Query Similarity Prediction
Mar 13, 2022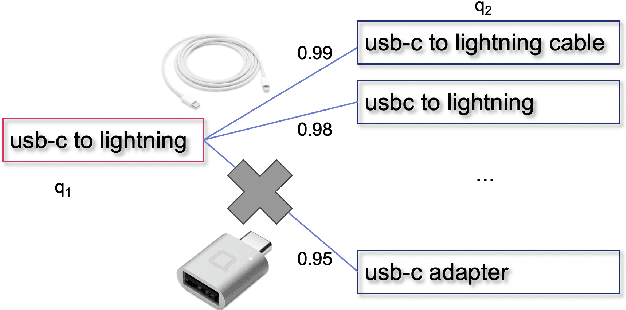
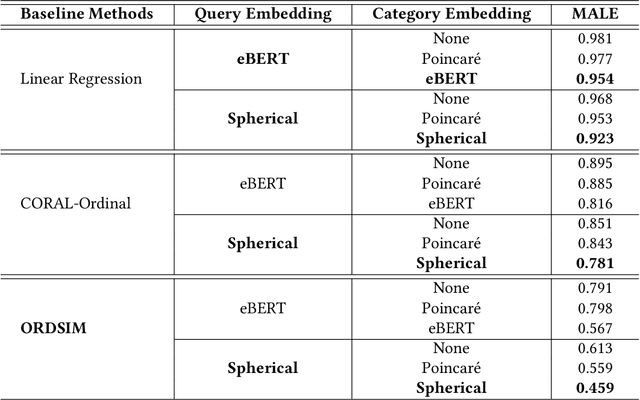
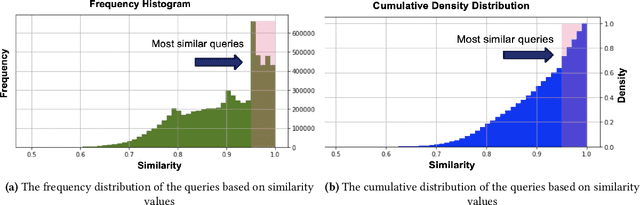
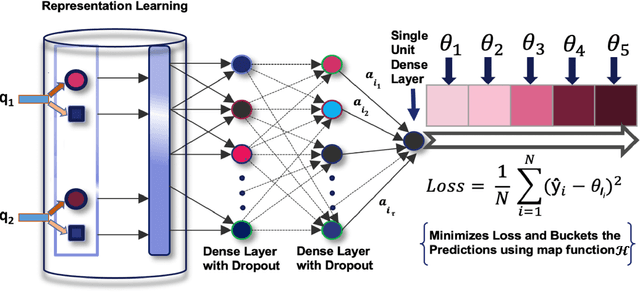
Query similarity prediction task is generally solved by regression based models with square loss. Such a model is agnostic of absolute similarity values and it penalizes the regression error at all ranges of similarity values at the same scale. However, to boost e-commerce platform's monetization, it is important to predict high-level similarity more accurately than low-level similarity, as highly similar queries retrieves items according to user-intents, whereas moderately similar item retrieves related items, which may not lead to a purchase. Regression models fail to customize its loss function to concentrate around the high-similarity band, resulting poor performance in query similarity prediction task. We address the above challenge by considering the query prediction as an ordinal regression problem, and thereby propose a model, ORDSIM (ORDinal Regression for SIMilarity Prediction). ORDSIM exploits variable-width buckets to model ordinal loss, which penalizes errors in high-level similarity harshly, and thus enable the regression model to obtain better prediction results for high similarity values. We evaluate ORDSIM on a dataset of over 10 millions e-commerce queries from eBay platform and show that ORDSIM achieves substantially smaller prediction error compared to the competing regression methods on this dataset.
* 9 pages
Defending Graph Convolutional Networks against Dynamic Graph Perturbations via Bayesian Self-supervision
Mar 07, 2022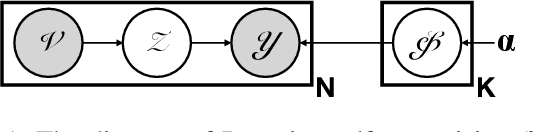

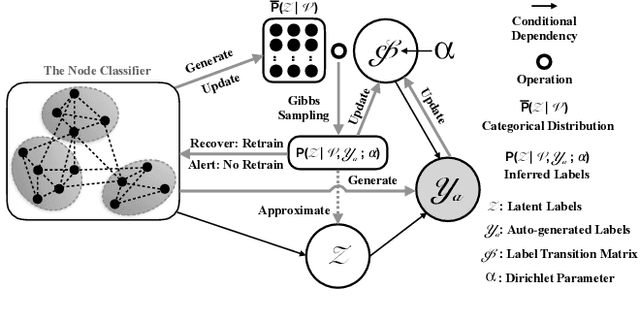

In recent years, plentiful evidence illustrates that Graph Convolutional Networks (GCNs) achieve extraordinary accomplishments on the node classification task. However, GCNs may be vulnerable to adversarial attacks on label-scarce dynamic graphs. Many existing works aim to strengthen the robustness of GCNs; for instance, adversarial training is used to shield GCNs against malicious perturbations. However, these works fail on dynamic graphs for which label scarcity is a pressing issue. To overcome label scarcity, self-training attempts to iteratively assign pseudo-labels to highly confident unlabeled nodes but such attempts may suffer serious degradation under dynamic graph perturbations. In this paper, we generalize noisy supervision as a kind of self-supervised learning method and then propose a novel Bayesian self-supervision model, namely GraphSS, to address the issue. Extensive experiments demonstrate that GraphSS can not only affirmatively alert the perturbations on dynamic graphs but also effectively recover the prediction of a node classifier when the graph is under such perturbations. These two advantages prove to be generalized over three classic GCNs across five public graph datasets.
Non-Exhaustive Learning Using Gaussian Mixture Generative Adversarial Networks
Jul 02, 2021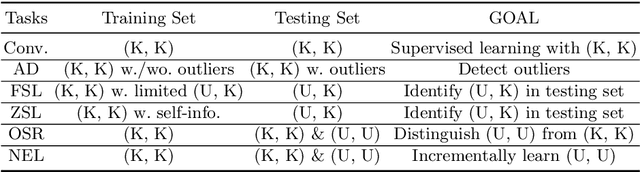
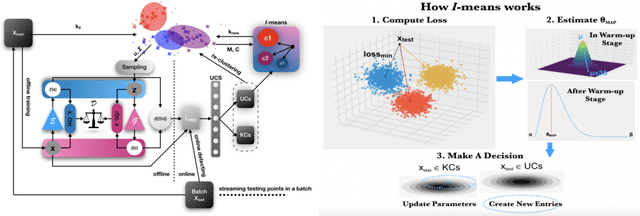

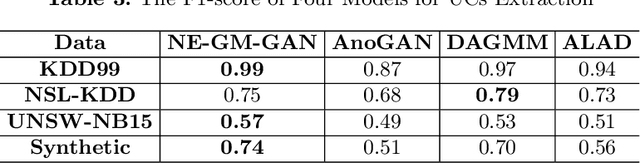
Supervised learning, while deployed in real-life scenarios, often encounters instances of unknown classes. Conventional algorithms for training a supervised learning model do not provide an option to detect such instances, so they miss-classify such instances with 100% probability. Open Set Recognition (OSR) and Non-Exhaustive Learning (NEL) are potential solutions to overcome this problem. Most existing methods of OSR first classify members of existing classes and then identify instances of new classes. However, many of the existing methods of OSR only makes a binary decision, i.e., they only identify the existence of the unknown class. Hence, such methods cannot distinguish test instances belonging to incremental unseen classes. On the other hand, the majority of NEL methods often make a parametric assumption over the data distribution, which either fail to return good results, due to the reason that real-life complex datasets may not follow a well-known data distribution. In this paper, we propose a new online non-exhaustive learning model, namely, Non-Exhaustive Gaussian Mixture Generative Adversarial Networks (NE-GM-GAN) to address these issues. Our proposed model synthesizes Gaussian mixture based latent representation over a deep generative model, such as GAN, for incremental detection of instances of emerging classes in the test data. Extensive experimental results on several benchmark datasets show that NE-GM-GAN significantly outperforms the state-of-the-art methods in detecting instances of novel classes in streaming data.
ASPER: Attention-based Approach to Extract Syntactic Patterns denoting Semantic Relations in Sentential Context
Apr 04, 2021
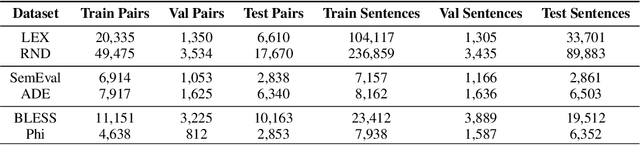
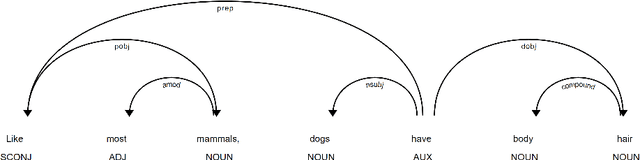

Semantic relationships, such as hyponym-hypernym, cause-effect, meronym-holonym etc. between a pair of entities in a sentence are usually reflected through syntactic patterns. Automatic extraction of such patterns benefits several downstream tasks, including, entity extraction, ontology building, and question answering. Unfortunately, automatic extraction of such patterns has not yet received much attention from NLP and information retrieval researchers. In this work, we propose an attention-based supervised deep learning model, ASPER, which extracts syntactic patterns between entities exhibiting a given semantic relation in the sentential context. We validate the performance of ASPER on three distinct semantic relations -- hyponym-hypernym, cause-effect, and meronym-holonym on six datasets. Experimental results show that for all these semantic relations, ASPER can automatically identify a collection of syntactic patterns reflecting the existence of such a relation between a pair of entities in a sentence. In comparison to the existing methodologies of syntactic pattern extraction, ASPER's performance is substantially superior.