 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformative Causality Extraction from Medical Literature via Dependency-tree based Patterns
Mar 13, 2022
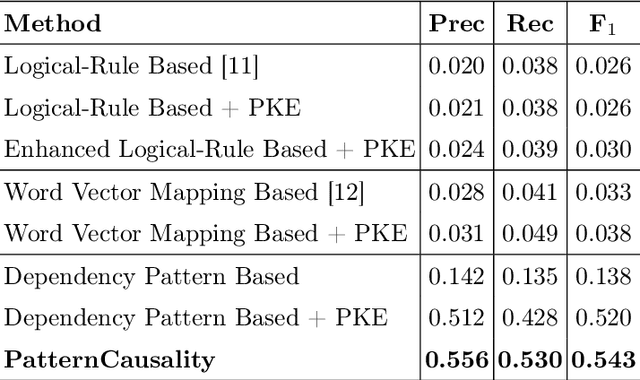
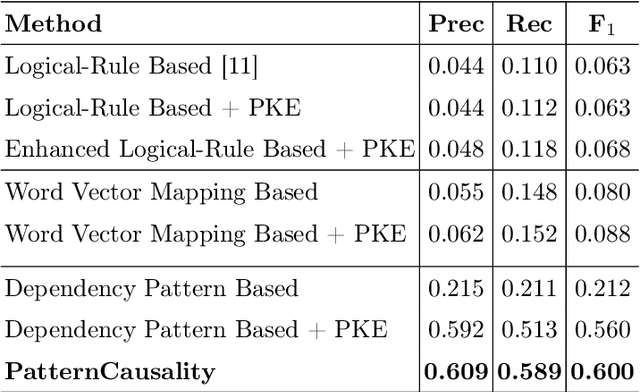
Extracting cause-effect entities from medical literature is an important task in medical information retrieval. A solution for solving this task can be used for compilation of various causality relations, such as, causality between disease and symptoms, between medications and side effects, between genes and diseases, etc. Existing solutions for extracting cause-effect entities work well for sentences where the cause and the effect phrases are name entities, single-word nouns, or noun phrases consisting of two to three words. Unfortunately, in medical literature, cause and effect phrases in a sentence are not simply nouns or noun phrases, rather they are complex phrases consisting of several words, and existing methods fail to correctly extract the cause and effect entities in such sentences. Partial extraction of cause and effect entities conveys poor quality, non informative, and often, contradictory facts, comparing to the one intended in the given sentence. In this work, we solve this problem by designing an unsupervised method for cause and effect phrase extraction, PatternCausality, which is specifically suitable for the medical literature. Our proposed approach first uses a collection of cause-effect dependency patterns as template to extract head words of cause and effect phrases and then it uses a novel phrase extraction method to obtain complete and meaningful cause and effect phrases from a sentence. Experiments on a cause-effect dataset built from sentences from PubMed articles show that for extracting cause and effect entities, PatternCausality is substantially better than the existing methods with an order of magnitude improvement in the F-score metric over the best of the existing methods.
* 22 pages without comment
ORDSIM: Ordinal Regression for E-Commerce Query Similarity Prediction
Mar 13, 2022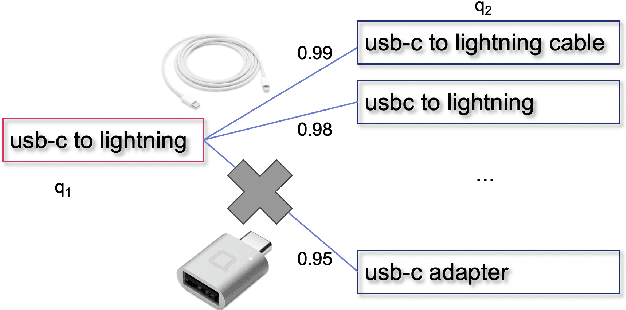
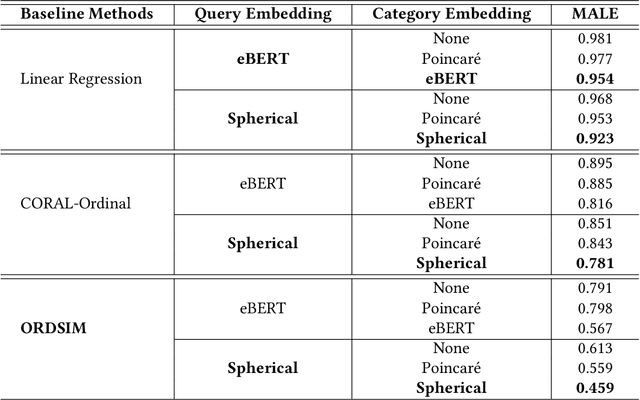
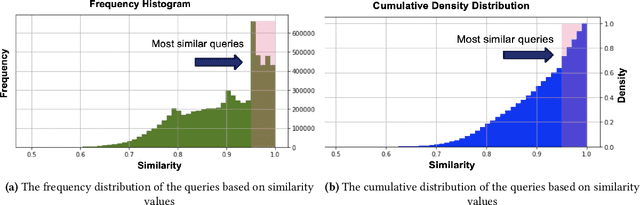
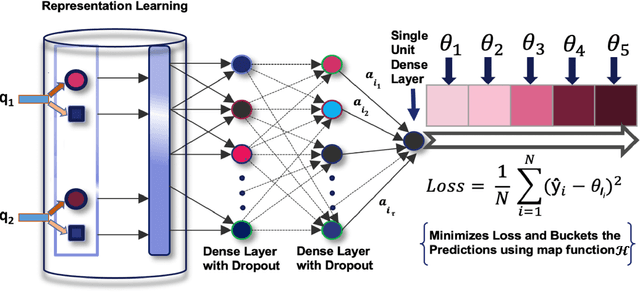
Query similarity prediction task is generally solved by regression based models with square loss. Such a model is agnostic of absolute similarity values and it penalizes the regression error at all ranges of similarity values at the same scale. However, to boost e-commerce platform's monetization, it is important to predict high-level similarity more accurately than low-level similarity, as highly similar queries retrieves items according to user-intents, whereas moderately similar item retrieves related items, which may not lead to a purchase. Regression models fail to customize its loss function to concentrate around the high-similarity band, resulting poor performance in query similarity prediction task. We address the above challenge by considering the query prediction as an ordinal regression problem, and thereby propose a model, ORDSIM (ORDinal Regression for SIMilarity Prediction). ORDSIM exploits variable-width buckets to model ordinal loss, which penalizes errors in high-level similarity harshly, and thus enable the regression model to obtain better prediction results for high similarity values. We evaluate ORDSIM on a dataset of over 10 millions e-commerce queries from eBay platform and show that ORDSIM achieves substantially smaller prediction error compared to the competing regression methods on this dataset.
* 9 pages
ASPER: Attention-based Approach to Extract Syntactic Patterns denoting Semantic Relations in Sentential Context
Apr 04, 2021

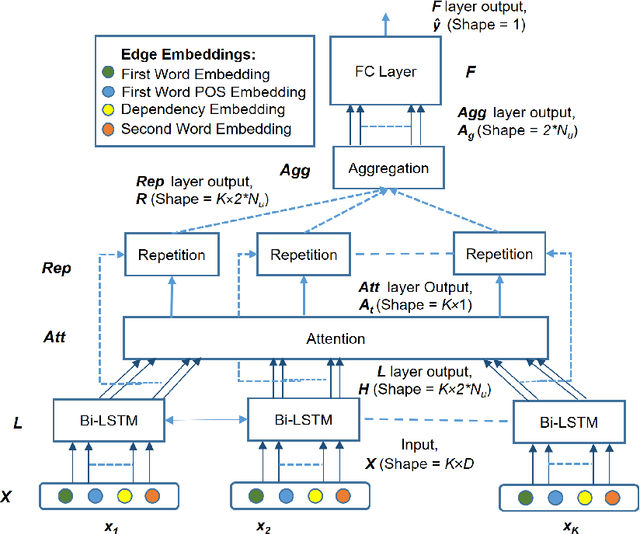
Semantic relationships, such as hyponym-hypernym, cause-effect, meronym-holonym etc. between a pair of entities in a sentence are usually reflected through syntactic patterns. Automatic extraction of such patterns benefits several downstream tasks, including, entity extraction, ontology building, and question answering. Unfortunately, automatic extraction of such patterns has not yet received much attention from NLP and information retrieval researchers. In this work, we propose an attention-based supervised deep learning model, ASPER, which extracts syntactic patterns between entities exhibiting a given semantic relation in the sentential context. We validate the performance of ASPER on three distinct semantic relations -- hyponym-hypernym, cause-effect, and meronym-holonym on six datasets. Experimental results show that for all these semantic relations, ASPER can automatically identify a collection of syntactic patterns reflecting the existence of such a relation between a pair of entities in a sentence. In comparison to the existing methodologies of syntactic pattern extraction, ASPER's performance is substantially superior.