 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Multimodal Misinformation Detection by Replaying the Whole Story from Image Modality Perspective
Nov 09, 2025
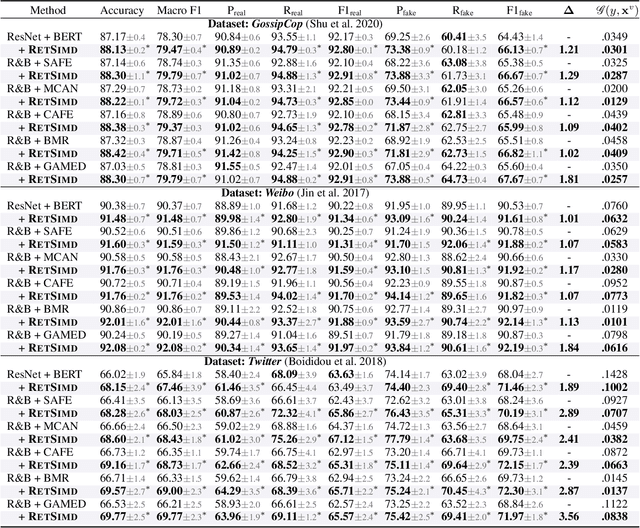
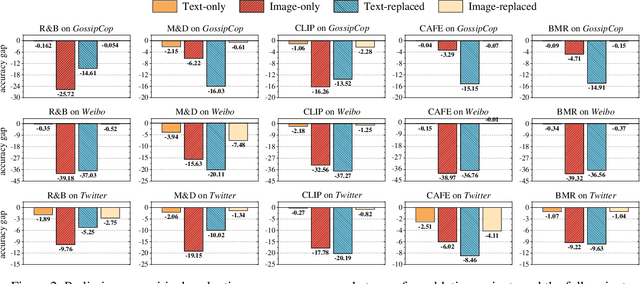
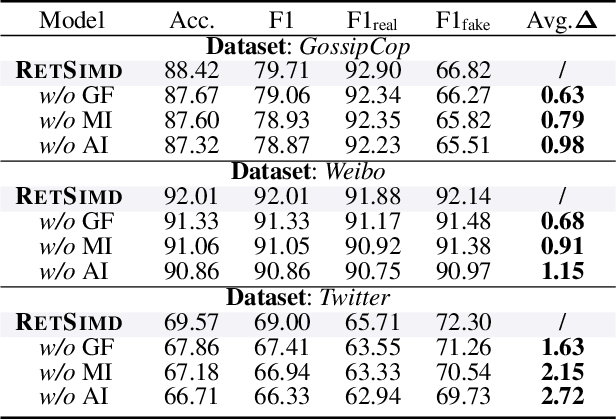
Multimodal Misinformation Detection (MMD) refers to the task of detecting social media posts involving misinformation, where the post often contains text and image modalities. However, by observing the MMD posts, we hold that the text modality may be much more informative than the image modality because the text generally describes the whole event/story of the current post but the image often presents partial scenes only. Our preliminary empirical results indicate that the image modality exactly contributes less to MMD. Upon this idea, we propose a new MMD method named RETSIMD. Specifically, we suppose that each text can be divided into several segments, and each text segment describes a partial scene that can be presented by an image. Accordingly, we split the text into a sequence of segments, and feed these segments into a pre-trained text-to-image generator to augment a sequence of images. We further incorporate two auxiliary objectives concerning text-image and image-label mutual information, and further post-train the generator over an auxiliary text-to-image generation benchmark dataset. Additionally, we propose a graph structure by defining three heuristic relationships between images, and use a graph neural network to generate the fused features. Extensive empirical results validate the effectiveness of RETSIMD.
AToken: A Unified Tokenizer for Vision
Sep 19, 2025We present AToken, the first unified visual tokenizer that achieves both high-fidelity reconstruction and semantic understanding across images, videos, and 3D assets. Unlike existing tokenizers that specialize in either reconstruction or understanding for single modalities, AToken encodes these diverse visual inputs into a shared 4D latent space, unifying both tasks and modalities in a single framework. Specifically, we introduce a pure transformer architecture with 4D rotary position embeddings to process visual inputs of arbitrary resolutions and temporal durations. To ensure stable training, we introduce an adversarial-free training objective that combines perceptual and Gram matrix losses, achieving state-of-the-art reconstruction quality. By employing a progressive training curriculum, AToken gradually expands from single images, videos, and 3D, and supports both continuous and discrete latent tokens. AToken achieves 0.21 rFID with 82.2% ImageNet accuracy for images, 3.01 rFVD with 40.2% MSRVTT retrieval for videos, and 28.28 PSNR with 90.9% classification accuracy for 3D.. In downstream applications, AToken enables both visual generation tasks (e.g., image generation with continuous and discrete tokens, text-to-video generation, image-to-3D synthesis) and understanding tasks (e.g., multimodal LLMs), achieving competitive performance across all benchmarks. These results shed light on the next-generation multimodal AI systems built upon unified visual tokenization.
3DLLM-Mem: Long-Term Spatial-Temporal Memory for Embodied 3D Large Language Model
May 28, 2025Humans excel at performing complex tasks by leveraging long-term memory across temporal and spatial experiences. In contrast, current Large Language Models (LLMs) struggle to effectively plan and act in dynamic, multi-room 3D environments. We posit that part of this limitation is due to the lack of proper 3D spatial-temporal memory modeling in LLMs. To address this, we first introduce 3DMem-Bench, a comprehensive benchmark comprising over 26,000 trajectories and 2,892 embodied tasks, question-answering and captioning, designed to evaluate an agent's ability to reason over long-term memory in 3D environments. Second, we propose 3DLLM-Mem, a novel dynamic memory management and fusion model for embodied spatial-temporal reasoning and actions in LLMs. Our model uses working memory tokens, which represents current observations, as queries to selectively attend to and fuse the most useful spatial and temporal features from episodic memory, which stores past observations and interactions. Our approach allows the agent to focus on task-relevant information while maintaining memory efficiency in complex, long-horizon environments. Experimental results demonstrate that 3DLLM-Mem achieves state-of-the-art performance across various tasks, outperforming the strongest baselines by 16.5% in success rate on 3DMem-Bench's most challenging in-the-wild embodied tasks.
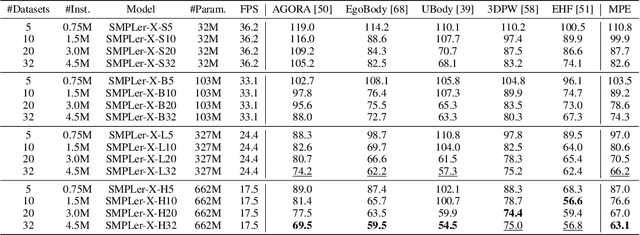
SMPLest-X: Ultimate Scaling for Expressive Human Pose and Shape Estimation
Jan 16, 2025Expressive human pose and shape estimation (EHPS) unifies body, hands, and face motion capture with numerous applications. Despite encouraging progress, current state-of-the-art methods focus on training innovative architectural designs on confined datasets. In this work, we investigate the impact of scaling up EHPS towards a family of generalist foundation models. 1) For data scaling, we perform a systematic investigation on 40 EHPS datasets, encompassing a wide range of scenarios that a model trained on any single dataset cannot handle. More importantly, capitalizing on insights obtained from the extensive benchmarking process, we optimize our training scheme and select datasets that lead to a significant leap in EHPS capabilities. Ultimately, we achieve diminishing returns at 10M training instances from diverse data sources. 2) For model scaling, we take advantage of vision transformers (up to ViT-Huge as the backbone) to study the scaling law of model sizes in EHPS. To exclude the influence of algorithmic design, we base our experiments on two minimalist architectures: SMPLer-X, which consists of an intermediate step for hand and face localization, and SMPLest-X, an even simpler version that reduces the network to its bare essentials and highlights significant advances in the capture of articulated hands. With big data and the large model, the foundation models exhibit strong performance across diverse test benchmarks and excellent transferability to even unseen environments. Moreover, our finetuning strategy turns the generalist into specialist models, allowing them to achieve further performance boosts. Notably, our foundation models consistently deliver state-of-the-art results on seven benchmarks such as AGORA, UBody, EgoBody, and our proposed SynHand dataset for comprehensive hand evaluation. (Code is available at: https://github.com/wqyin/SMPLest-X).
Approximately Aligned Decoding
Oct 01, 2024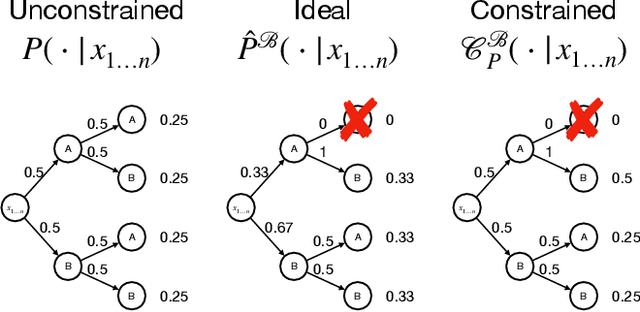
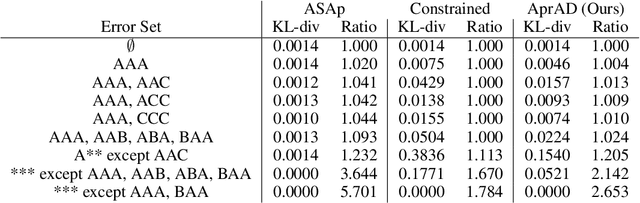

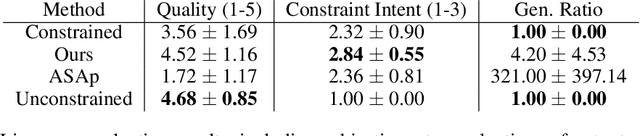
It is common to reject undesired outputs of Large Language Models (LLMs); however, current methods to do so require an excessive amount of computation, or severely distort the distribution of outputs. We present a method to balance the distortion of the output distribution with computational efficiency, allowing for the generation of long sequences of text with difficult-to-satisfy constraints, with less amplification of low probability outputs compared to existing methods. We show through a series of experiments that the task-specific performance of our method is comparable to methods that do not distort the output distribution, while being much more computationally efficient.
AiOS: All-in-One-Stage Expressive Human Pose and Shape Estimation
Mar 26, 2024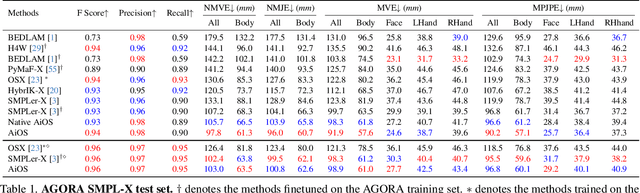
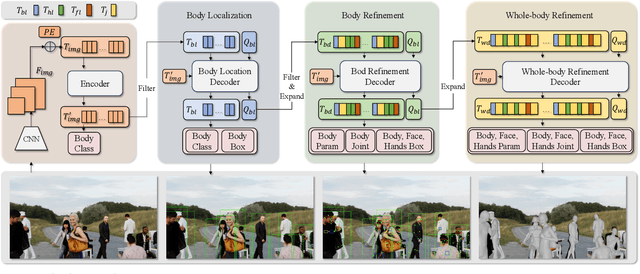
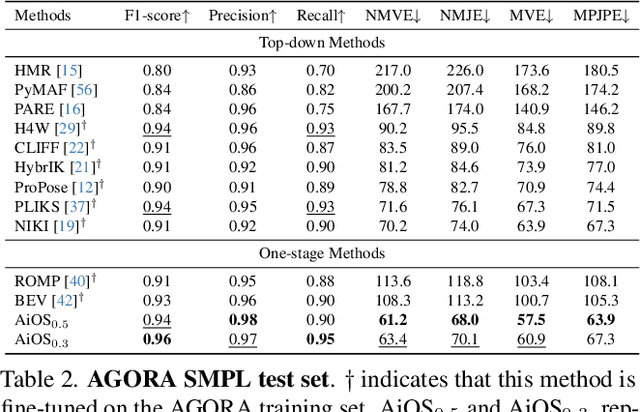
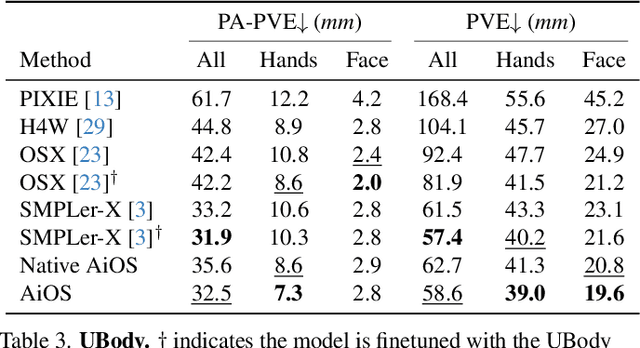
Expressive human pose and shape estimation (a.k.a. 3D whole-body mesh recovery) involves the human body, hand, and expression estimation. Most existing methods have tackled this task in a two-stage manner, first detecting the human body part with an off-the-shelf detection model and inferring the different human body parts individually. Despite the impressive results achieved, these methods suffer from 1) loss of valuable contextual information via cropping, 2) introducing distractions, and 3) lacking inter-association among different persons and body parts, inevitably causing performance degradation, especially for crowded scenes. To address these issues, we introduce a novel all-in-one-stage framework, AiOS, for multiple expressive human pose and shape recovery without an additional human detection step. Specifically, our method is built upon DETR, which treats multi-person whole-body mesh recovery task as a progressive set prediction problem with various sequential detection. We devise the decoder tokens and extend them to our task. Specifically, we first employ a human token to probe a human location in the image and encode global features for each instance, which provides a coarse location for the later transformer block. Then, we introduce a joint-related token to probe the human joint in the image and encoder a fine-grained local feature, which collaborates with the global feature to regress the whole-body mesh. This straightforward but effective model outperforms previous state-of-the-art methods by a 9% reduction in NMVE on AGORA, a 30% reduction in PVE on EHF, a 10% reduction in PVE on ARCTIC, and a 3% reduction in PVE on EgoBody.
AGSPNet: A framework for parcel-scale crop fine-grained semantic change detection from UAV high-resolution imagery with agricultural geographic scene constraints
Jan 11, 2024Real-time and accurate information on fine-grained changes in crop cultivation is of great significance for crop growth monitoring, yield prediction and agricultural structure adjustment. Aiming at the problems of serious spectral confusion in visible high-resolution unmanned aerial vehicle (UAV) images of different phases, interference of large complex background and salt-and-pepper noise by existing semantic change detection (SCD) algorithms, in order to effectively extract deep image features of crops and meet the demand of agricultural practical engineering applications, this paper designs and proposes an agricultural geographic scene and parcel-scale constrained SCD framework for crops (AGSPNet). AGSPNet framework contains three parts: agricultural geographic scene (AGS) division module, parcel edge extraction module and crop SCD module. Meanwhile, we produce and introduce an UAV image SCD dataset (CSCD) dedicated to agricultural monitoring, encompassing multiple semantic variation types of crops in complex geographical scene. We conduct comparative experiments and accuracy evaluations in two test areas of this dataset, and the results show that the crop SCD results of AGSPNet consistently outperform other deep learning SCD models in terms of quantity and quality, with the evaluation metrics F1-score, kappa, OA, and mIoU obtaining improvements of 0.038, 0.021, 0.011 and 0.062, respectively, on average over the sub-optimal method. The method proposed in this paper can clearly detect the fine-grained change information of crop types in complex scenes, which can provide scientific and technical support for smart agriculture monitoring and management, food policy formulation and food security assurance.
SMPLer-X: Scaling Up Expressive Human Pose and Shape Estimation
Sep 29, 2023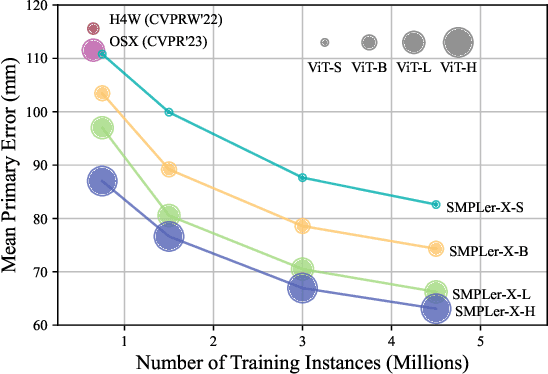
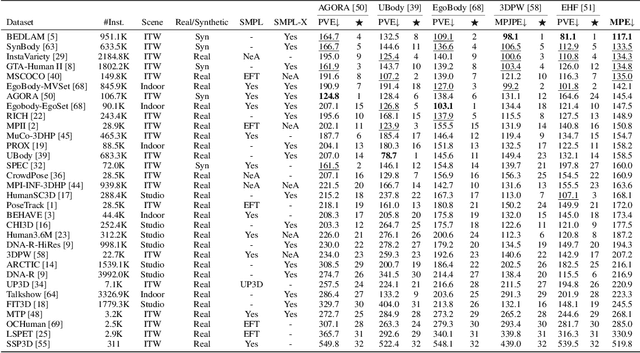
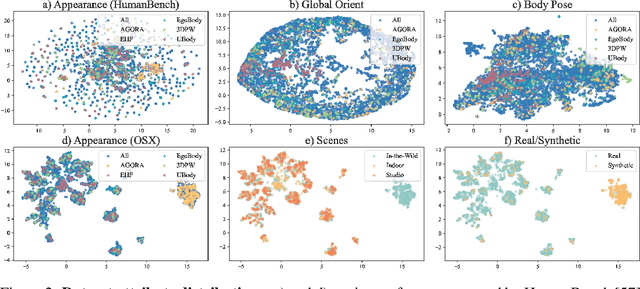
Expressive human pose and shape estimation (EHPS) unifies body, hands, and face motion capture with numerous applications. Despite encouraging progress, current state-of-the-art methods still depend largely on confined training datasets. In this work, we investigate scaling up EHPS towards the first generalist foundation model (dubbed SMPLer-X), with up to ViT-Huge as the backbone and training with up to 4.5M instances from diverse data sources. With big data and the large model, SMPLer-X exhibits strong performance across diverse test benchmarks and excellent transferability to even unseen environments. 1) For the data scaling, we perform a systematic investigation on 32 EHPS datasets, encompassing a wide range of scenarios that a model trained on any single dataset cannot handle. More importantly, capitalizing on insights obtained from the extensive benchmarking process, we optimize our training scheme and select datasets that lead to a significant leap in EHPS capabilities. 2) For the model scaling, we take advantage of vision transformers to study the scaling law of model sizes in EHPS. Moreover, our finetuning strategy turn SMPLer-X into specialist models, allowing them to achieve further performance boosts. Notably, our foundation model SMPLer-X consistently delivers state-of-the-art results on seven benchmarks such as AGORA (107.2 mm NMVE), UBody (57.4 mm PVE), EgoBody (63.6 mm PVE), and EHF (62.3 mm PVE without finetuning).
Learning Dense UV Completion for Human Mesh Recovery
Aug 10, 2023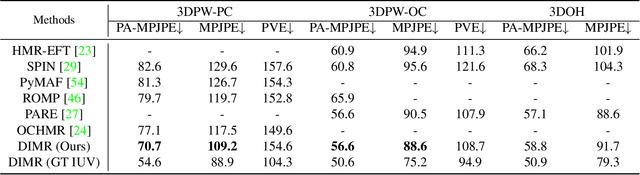
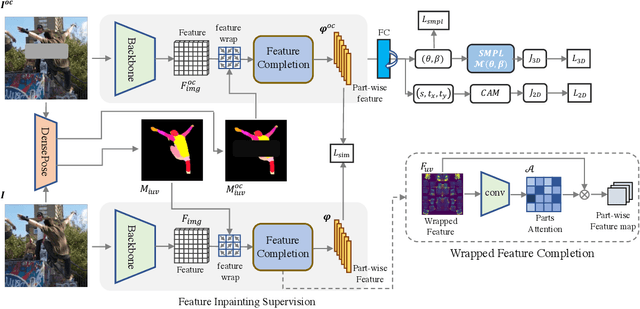
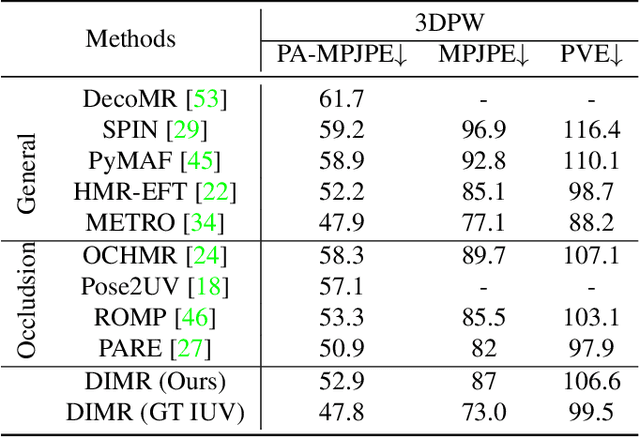

Human mesh reconstruction from a single image is challenging in the presence of occlusion, which can be caused by self, objects, or other humans. Existing methods either fail to separate human features accurately or lack proper supervision for feature completion. In this paper, we propose Dense Inpainting Human Mesh Recovery (DIMR), a two-stage method that leverages dense correspondence maps to handle occlusion. Our method utilizes a dense correspondence map to separate visible human features and completes human features on a structured UV map dense human with an attention-based feature completion module. We also design a feature inpainting training procedure that guides the network to learn from unoccluded features. We evaluate our method on several datasets and demonstrate its superior performance under heavily occluded scenarios compared to other methods. Extensive experiments show that our method obviously outperforms prior SOTA methods on heavily occluded images and achieves comparable results on the standard benchmarks (3DPW).
Integrating Listwise Ranking into Pairwise-based Image-Text Retrieval
May 26, 2023



Image-Text Retrieval (ITR) is essentially a ranking problem. Given a query caption, the goal is to rank candidate images by relevance, from large to small. The current ITR datasets are constructed in a pairwise manner. Image-text pairs are annotated as positive or negative. Correspondingly, ITR models mainly use pairwise losses, such as triplet loss, to learn to rank. Pairwise-based ITR increases positive pair similarity while decreasing negative pair similarity indiscriminately. However, the relevance between dissimilar negative pairs is different. Pairwise annotations cannot reflect this difference in relevance. In the current datasets, pairwise annotations miss many correlations. There are many potential positive pairs among the pairs labeled as negative. Pairwise-based ITR can only rank positive samples before negative samples, but cannot rank negative samples by relevance. In this paper, we integrate listwise ranking into conventional pairwise-based ITR. Listwise ranking optimizes the entire ranking list based on relevance scores. Specifically, we first propose a Relevance Score Calculation (RSC) module to calculate the relevance score of the entire ranked list. Then we choose the ranking metric, Normalized Discounted Cumulative Gain (NDCG), as the optimization objective. We transform the non-differentiable NDCG into a differentiable listwise loss, named Smooth-NDCG (S-NDCG). Our listwise ranking approach can be plug-and-play integrated into current pairwise-based ITR models. Experiments on ITR benchmarks show that integrating listwise ranking can improve the performance of current ITR models and provide more user-friendly retrieval results. The code is available at https://github.com/AAA-Zheng/Listwise_ITR.