 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextWeaver: Selective and Dependency-Structured Memory Construction for LLM Agents
Apr 24, 2026Large language model (LLM) agents often struggle in long-context interactions. As the agent accumulates more interaction history, context management approaches such as sliding window and prompt compression may omit earlier structured information that later steps rely on. Recent retrieval-based memory systems surface relevant content but still overlook the causal and logical structure needed for multi-step reasoning. We introduce ContextWeaver, a selective and dependency-structured memory framework that organizes an agent's interaction trace into a graph of reasoning steps and selects the relevant context for future actions. Unlike prior context management approaches, ContextWeaver supports: (1) dependency-based construction and traversal that link each step to the earlier steps it relies on; (2) compact dependency summarization that condenses root-to-step reasoning paths into reusable units; and (3) a lightweight validation layer that incorporates execution feedback. On the SWE-Bench Verified and Lite benchmarks, ContextWeaver improves performance over a sliding-window baseline in pass@1, while reducing reasoning steps and token usage. Our observations suggest that modeling logical dependencies provides a stable and scalable memory mechanism for LLM agents that use tools.
ExecTune: Effective Steering of Black-Box LLMs with Guide Models
Apr 09, 2026For large language models deployed through black-box APIs, recurring inference costs often exceed one-time training costs. This motivates composed agentic systems that amortize expensive reasoning into reusable intermediate representations. We study a broad class of such systems, termed Guide-Core Policies (GCoP), in which a guide model generates a structured strategy that is executed by a black-box core model. This abstraction subsumes base, supervised, and advisor-style approaches, which differ primarily in how the guide is trained. We formalize GCoP under a cost-sensitive utility objective and show that end-to-end performance is governed by guide-averaged executability: the probability that a strategy generated by the guide can be faithfully executed by the core. Our analysis shows that existing GCoP instantiations often fail to optimize executability under deployment constraints, resulting in brittle strategies and inefficient computation. Motivated by these insights, we propose ExecTune, a principled training recipe that combines teacher-guided acceptance sampling, supervised fine-tuning, and structure-aware reinforcement learning to directly optimize syntactic validity, execution success, and cost efficiency. Across mathematical reasoning and code-generation benchmarks, GCoP with ExecTune improves accuracy by up to 9.2% over prior state-of-the-art baselines while reducing inference cost by up to 22.4%. It enables Claude Haiku 3.5 to outperform Sonnet 3.5 on both math and code tasks, and to come within 1.7% absolute accuracy of Sonnet 4 at 38% lower cost. Beyond efficiency, GCoP also supports modular adaptation by updating the guide without retraining the core.
TerraFormer: Automated Infrastructure-as-Code with LLMs Fine-Tuned via Policy-Guided Verifier Feedback
Jan 13, 2026Automating Infrastructure-as-Code (IaC) is challenging, and large language models (LLMs) often produce incorrect configurations from natural language (NL). We present TerraFormer, a neuro-symbolic framework for IaC generation and mutation that combines supervised fine-tuning with verifier-guided reinforcement learning, using formal verification tools to provide feedback on syntax, deployability, and policy compliance. We curate two large, high-quality NL-to-IaC datasets, TF-Gen (152k instances) and TF-Mutn (52k instances), via multi-stage verification and iterative LLM self-correction. Evaluations against 17 state-of-the-art LLMs, including ~50x larger models like Sonnet 3.7, DeepSeek-R1, and GPT-4.1, show that TerraFormer improves correctness over its base LLM by 15.94% on IaC-Eval, 11.65% on TF-Gen (Test), and 19.60% on TF-Mutn (Test). It outperforms larger models on both TF-Gen (Test) and TF-Mutn (Test), ranks third on IaC-Eval, and achieves top best-practices and security compliance.
Empowering Multi-Turn Tool-Integrated Reasoning with Group Turn Policy Optimization
Nov 18, 2025
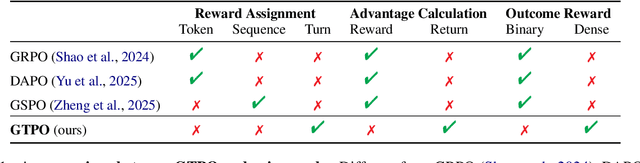
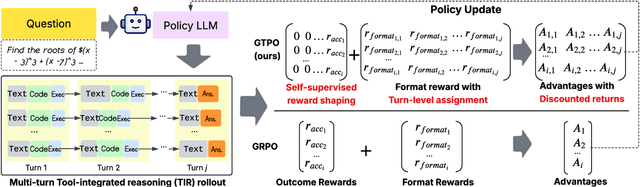
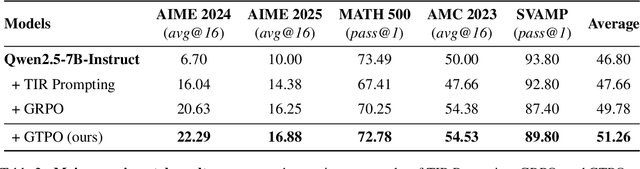
Training Large Language Models (LLMs) for multi-turn Tool-Integrated Reasoning (TIR) - where models iteratively reason, generate code, and verify through execution - remains challenging for existing reinforcement learning (RL) approaches. Current RL methods, exemplified by Group Relative Policy Optimization (GRPO), suffer from coarse-grained, trajectory-level rewards that provide insufficient learning signals for complex multi-turn interactions, leading to training stagnation. To address this issue, we propose Group Turn Policy Optimization (GTPO), a novel RL algorithm specifically designed for training LLMs on multi-turn TIR tasks. GTPO introduces three key innovations: (1) turn-level reward assignment that provides fine-grained feedback for individual turns, (2) return-based advantage estimation where normalized discounted returns are calculated as advantages, and (3) self-supervised reward shaping that exploits self-supervision signals from generated code to densify sparse binary outcome-based rewards. Our comprehensive evaluation demonstrates that GTPO outperforms GRPO by 3.0% on average across diverse reasoning benchmarks, establishing its effectiveness for advancing complex mathematical reasoning in the real world.
MURPHY: Multi-Turn GRPO for Self Correcting Code Generation
Nov 11, 2025Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a powerful framework for enhancing the reasoning capabilities of large language models (LLMs). However, existing approaches such as Group Relative Policy Optimization (GRPO) and its variants, while effective on reasoning benchmarks, struggle with agentic tasks that require iterative decision-making. We introduce Murphy, a multi-turn reflective optimization framework that extends GRPO by incorporating iterative self-correction during training. By leveraging both quantitative and qualitative execution feedback, Murphy enables models to progressively refine their reasoning across multiple turns. Evaluations on code generation benchmarks with model families such as Qwen and OLMo show that Murphy consistently improves performance, achieving up to a 8% relative gain in pass@1 over GRPO, on similar compute budgets.
Approximately Aligned Decoding
Oct 01, 2024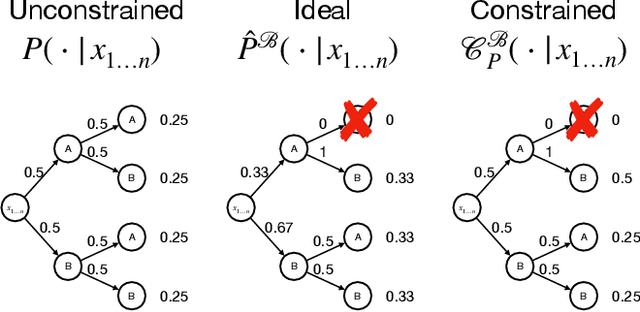
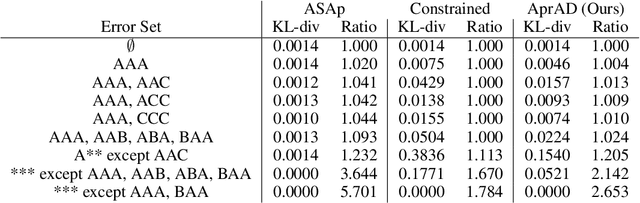

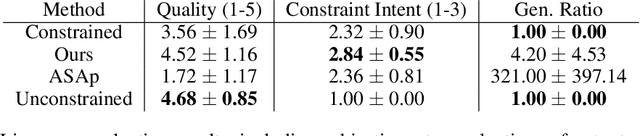
It is common to reject undesired outputs of Large Language Models (LLMs); however, current methods to do so require an excessive amount of computation, or severely distort the distribution of outputs. We present a method to balance the distortion of the output distribution with computational efficiency, allowing for the generation of long sequences of text with difficult-to-satisfy constraints, with less amplification of low probability outputs compared to existing methods. We show through a series of experiments that the task-specific performance of our method is comparable to methods that do not distort the output distribution, while being much more computationally efficient.
Training LLMs to Better Self-Debug and Explain Code
May 28, 2024



In the domain of code generation, self-debugging is crucial. It allows LLMs to refine their generated code based on execution feedback. This is particularly important because generating correct solutions in one attempt proves challenging for complex tasks. Prior works on self-debugging mostly focus on prompting methods by providing LLMs with few-shot examples, which work poorly on small open-sourced LLMs. In this work, we propose a training framework that significantly improves self-debugging capability of LLMs. Intuitively, we observe that a chain of explanations on the wrong code followed by code refinement helps LLMs better analyze the wrong code and do refinement. We thus propose an automated pipeline to collect a high-quality dataset for code explanation and refinement by generating a number of explanations and refinement trajectories and filtering via execution verification. We perform supervised fine-tuning (SFT) and further reinforcement learning (RL) on both success and failure trajectories with a novel reward design considering code explanation and refinement quality. SFT improves the pass@1 by up to 15.92% and pass@10 by 9.30% over four benchmarks. RL training brings additional up to 3.54% improvement on pass@1 and 2.55% improvement on pass@10. The trained LLMs show iterative refinement ability, and can keep refining code continuously. Lastly, our human evaluation shows that the LLMs trained with our framework generate more useful code explanations and help developers better understand bugs in source code.
Automated Evaluation of Retrieval-Augmented Language Models with Task-Specific Exam Generation
May 22, 2024



We propose a new method to measure the task-specific accuracy of Retrieval-Augmented Large Language Models (RAG). Evaluation is performed by scoring the RAG on an automatically-generated synthetic exam composed of multiple choice questions based on the corpus of documents associated with the task. Our method is an automated, cost-efficient, interpretable, and robust strategy to select the optimal components for a RAG system. We leverage Item Response Theory (IRT) to estimate the quality of an exam and its informativeness on task-specific accuracy. IRT also provides a natural way to iteratively improve the exam by eliminating the exam questions that are not sufficiently informative about a model's ability. We demonstrate our approach on four new open-ended Question-Answering tasks based on Arxiv abstracts, StackExchange questions, AWS DevOps troubleshooting guides, and SEC filings. In addition, our experiments reveal more general insights into factors impacting RAG performance like size, retrieval mechanism, prompting and fine-tuning. Most notably, our findings show that choosing the right retrieval algorithms often leads to bigger performance gains than simply using a larger language model.
Collage: Light-Weight Low-Precision Strategy for LLM Training
May 06, 2024



Large models training is plagued by the intense compute cost and limited hardware memory. A practical solution is low-precision representation but is troubled by loss in numerical accuracy and unstable training rendering the model less useful. We argue that low-precision floating points can perform well provided the error is properly compensated at the critical locations in the training process. We propose Collage which utilizes multi-component float representation in low-precision to accurately perform operations with numerical errors accounted. To understand the impact of imprecision to training, we propose a simple and novel metric which tracks the lost information during training as well as differentiates various precision strategies. Our method works with commonly used low-precision such as half-precision ($16$-bit floating points) and can be naturally extended to work with even lower precision such as $8$-bit. Experimental results show that pre-training using Collage removes the requirement of using $32$-bit floating-point copies of the model and attains similar/better training performance compared to $(16, 32)$-bit mixed-precision strategy, with up to $3.7\times$ speedup and $\sim 15\%$ to $23\%$ less memory usage in practice.
BASS: Batched Attention-optimized Speculative Sampling
Apr 24, 2024



Speculative decoding has emerged as a powerful method to improve latency and throughput in hosting large language models. However, most existing implementations focus on generating a single sequence. Real-world generative AI applications often require multiple responses and how to perform speculative decoding in a batched setting while preserving its latency benefits poses non-trivial challenges. This paper describes a system of batched speculative decoding that sets a new state of the art in multi-sequence generation latency and that demonstrates superior GPU utilization as well as quality of generations within a time budget. For example, for a 7.8B-size model on a single A100 GPU and with a batch size of 8, each sequence is generated at an average speed of 5.8ms per token, the overall throughput being 1.1K tokens per second. These results represent state-of-the-art latency and a 2.15X speed-up over optimized regular decoding. Within a time budget that regular decoding does not finish, our system is able to generate sequences with HumanEval Pass@First of 43% and Pass@All of 61%, far exceeding what's feasible with single-sequence speculative decoding. Our peak GPU utilization during decoding reaches as high as 15.8%, more than 3X the highest of that of regular decoding and around 10X of single-sequence speculative decoding.