 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-trained Recommender Systems: A Causal Debiasing Perspective
Oct 30, 2023



Recent studies on pre-trained vision/language models have demonstrated the practical benefit of a new, promising solution-building paradigm in AI where models can be pre-trained on broad data describing a generic task space and then adapted successfully to solve a wide range of downstream tasks, even when training data is severely limited (e.g., in zero- or few-shot learning scenarios). Inspired by such progress, we investigate in this paper the possibilities and challenges of adapting such a paradigm to the context of recommender systems, which is less investigated from the perspective of pre-trained model. In particular, we propose to develop a generic recommender that captures universal interaction patterns by training on generic user-item interaction data extracted from different domains, which can then be fast adapted to improve few-shot learning performance in unseen new domains (with limited data). However, unlike vision/language data which share strong conformity in the semantic space, universal patterns underlying recommendation data collected across different domains (e.g., different countries or different E-commerce platforms) are often occluded by both in-domain and cross-domain biases implicitly imposed by the cultural differences in their user and item bases, as well as their uses of different e-commerce platforms. As shown in our experiments, such heterogeneous biases in the data tend to hinder the effectiveness of the pre-trained model. To address this challenge, we further introduce and formalize a causal debiasing perspective, which is substantiated via a hierarchical Bayesian deep learning model, named PreRec. Our empirical studies on real-world data show that the proposed model could significantly improve the recommendation performance in zero- and few-shot learning settings under both cross-market and cross-platform scenarios.
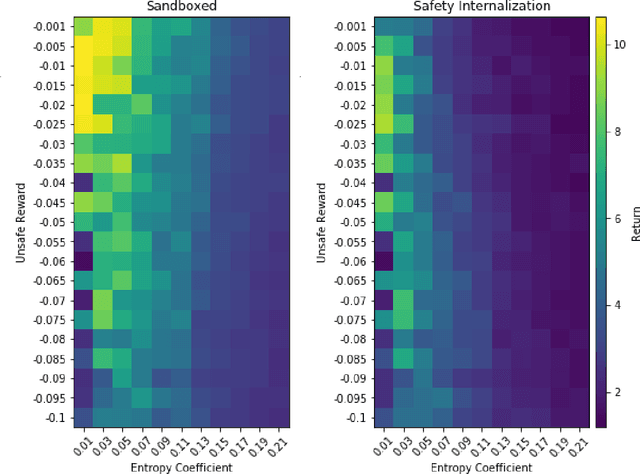
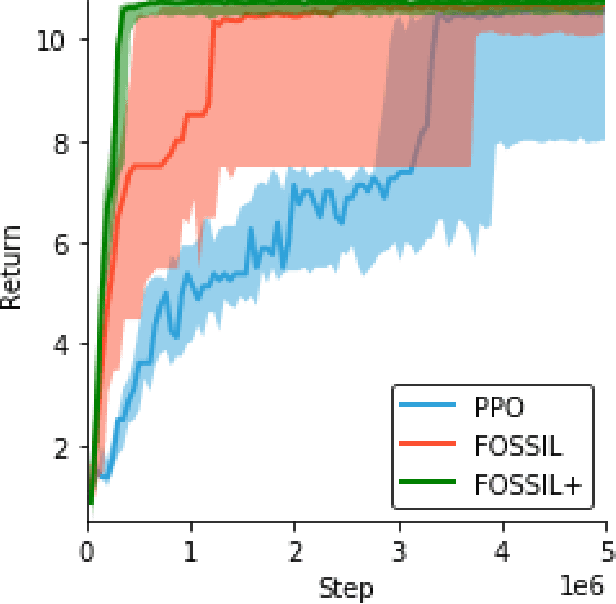
Verifiably Safe Exploration for End-to-End Reinforcement Learning
Jul 02, 2020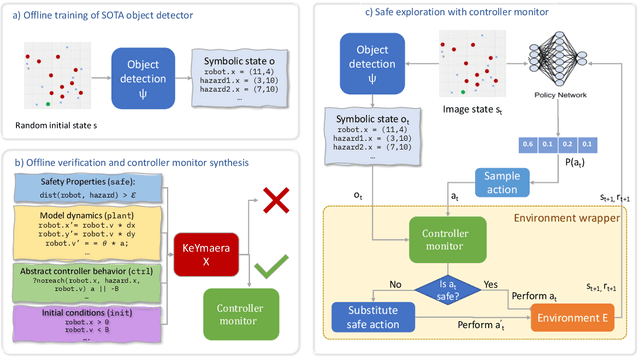
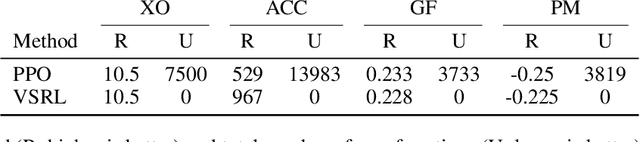

Deploying deep reinforcement learning in safety-critical settings requires developing algorithms that obey hard constraints during exploration. This paper contributes a first approach toward enforcing formal safety constraints on end-to-end policies with visual inputs. Our approach draws on recent advances in object detection and automated reasoning for hybrid dynamical systems. The approach is evaluated on a novel benchmark that emphasizes the challenge of safely exploring in the presence of hard constraints. Our benchmark draws from several proposed problem sets for safe learning and includes problems that emphasize challenges such as reward signals that are not aligned with safety constraints. On each of these benchmark problems, our algorithm completely avoids unsafe behavior while remaining competitive at optimizing for as much reward as is safe. We also prove that our method of enforcing the safety constraints preserves all safe policies from the original environment.
Formal Verification of End-to-End Learning in Cyber-Physical Systems: Progress and Challenges
Jun 15, 2020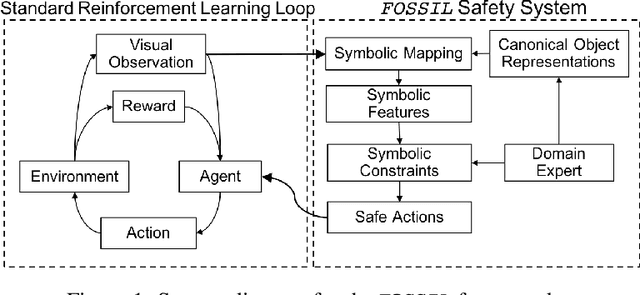
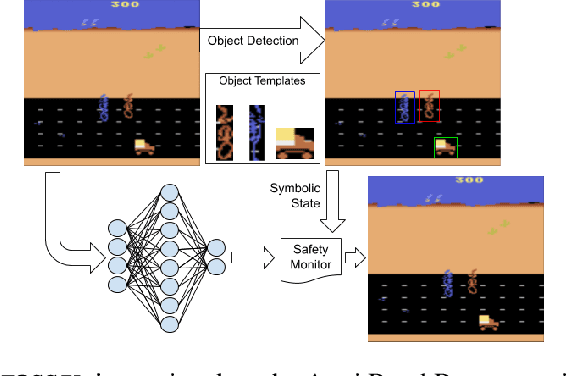
Autonomous systems -- such as self-driving cars, autonomous drones, and automated trains -- must come with strong safety guarantees. Over the past decade, techniques based on formal methods have enjoyed some success in providing strong correctness guarantees for large software systems including operating system kernels, cryptographic protocols, and control software for drones. These successes suggest it might be possible to ensure the safety of autonomous systems by constructing formal, computer-checked correctness proofs. This paper identifies three assumptions underlying existing formal verification techniques, explains how each of these assumptions limits the applicability of verification in autonomous systems, and summarizes preliminary work toward improving the strength of evidence provided by formal verification.
On the Design of Black-box Adversarial Examples by Leveraging Gradient-free Optimization and Operator Splitting Method
Jul 26, 2019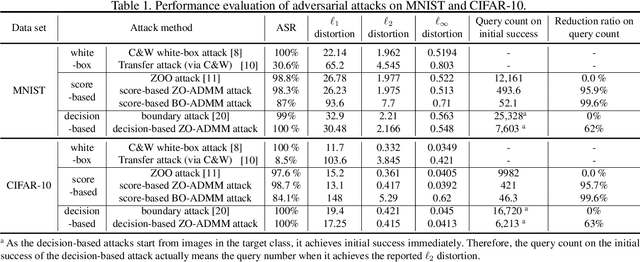

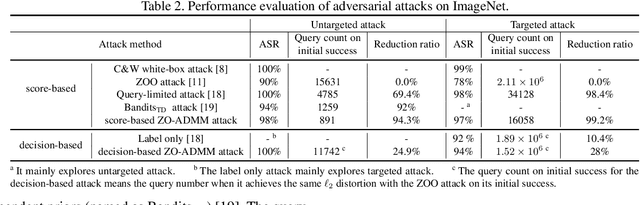
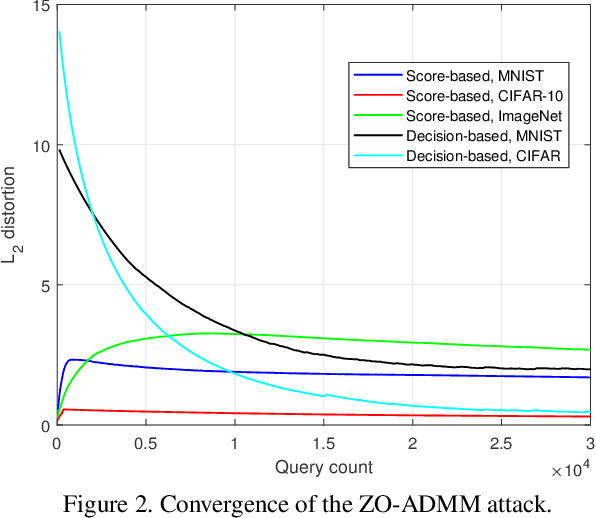
Robust machine learning is currently one of the most prominent topics which could potentially help shaping a future of advanced AI platforms that not only perform well in average cases but also in worst cases or adverse situations. Despite the long-term vision, however, existing studies on black-box adversarial attacks are still restricted to very specific settings of threat models (e.g., single distortion metric and restrictive assumption on target model's feedback to queries) and/or suffer from prohibitively high query complexity. To push for further advances in this field, we introduce a general framework based on an operator splitting method, the alternating direction method of multipliers (ADMM) to devise efficient, robust black-box attacks that work with various distortion metrics and feedback settings without incurring high query complexity. Due to the black-box nature of the threat model, the proposed ADMM solution framework is integrated with zeroth-order (ZO) optimization and Bayesian optimization (BO), and thus is applicable to the gradient-free regime. This results in two new black-box adversarial attack generation methods, ZO-ADMM and BO-ADMM. Our empirical evaluations on image classification datasets show that our proposed approaches have much lower function query complexities compared to state-of-the-art attack methods, but achieve very competitive attack success rates.