 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuaranteeing Conservation of Integrals with Projection in Physics-Informed Neural Networks
Nov 12, 2025We propose a novel projection method that guarantees the conservation of integral quantities in Physics-Informed Neural Networks (PINNs). While the soft constraint that PINNs use to enforce the structure of partial differential equations (PDEs) enables necessary flexibility during training, it also permits the discovered solution to violate physical laws. To address this, we introduce a projection method that guarantees the conservation of the linear and quadratic integrals, both separately and jointly. We derived the projection formulae by solving constrained non-linear optimization problems and found that our PINN modified with the projection, which we call PINN-Proj, reduced the error in the conservation of these quantities by three to four orders of magnitude compared to the soft constraint and marginally reduced the PDE solution error. We also found evidence that the projection improved convergence through improving the conditioning of the loss landscape. Our method holds promise as a general framework to guarantee the conservation of any integral quantity in a PINN if a tractable solution exists.
Satori-SWE: Evolutionary Test-Time Scaling for Sample-Efficient Software Engineering
May 29, 2025
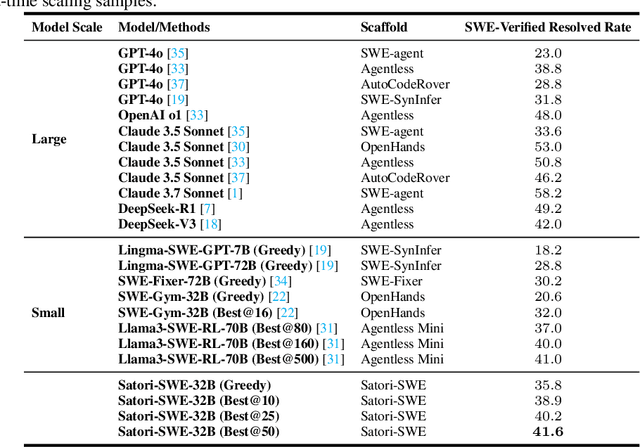
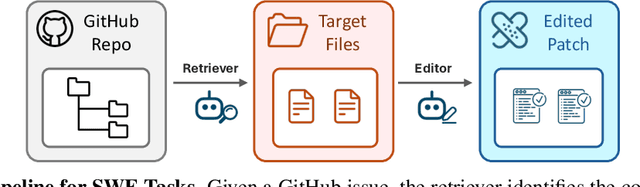

Language models (LMs) perform well on standardized coding benchmarks but struggle with real-world software engineering tasks such as resolving GitHub issues in SWE-Bench, especially when model parameters are less than 100B. While smaller models are preferable in practice due to their lower computational cost, improving their performance remains challenging. Existing approaches primarily rely on supervised fine-tuning (SFT) with high-quality data, which is expensive to curate at scale. An alternative is test-time scaling: generating multiple outputs, scoring them using a verifier, and selecting the best one. Although effective, this strategy often requires excessive sampling and costly scoring, limiting its practical application. We propose Evolutionary Test-Time Scaling (EvoScale), a sample-efficient method that treats generation as an evolutionary process. By iteratively refining outputs via selection and mutation, EvoScale shifts the output distribution toward higher-scoring regions, reducing the number of samples needed to find correct solutions. To reduce the overhead from repeatedly sampling and selection, we train the model to self-evolve using reinforcement learning (RL). Rather than relying on external verifiers at inference time, the model learns to self-improve the scores of its own generations across iterations. Evaluated on SWE-Bench-Verified, EvoScale enables our 32B model, Satori-SWE-32B, to match or exceed the performance of models with over 100B parameters while using a few samples. Code, data, and models will be fully open-sourced.
Satori: Reinforcement Learning with Chain-of-Action-Thought Enhances LLM Reasoning via Autoregressive Search
Feb 04, 2025



Large language models (LLMs) have demonstrated remarkable reasoning capabilities across diverse domains. Recent studies have shown that increasing test-time computation enhances LLMs' reasoning capabilities. This typically involves extensive sampling at inference time guided by an external LLM verifier, resulting in a two-player system. Despite external guidance, the effectiveness of this system demonstrates the potential of a single LLM to tackle complex tasks. Thus, we pose a new research problem: Can we internalize the searching capabilities to fundamentally enhance the reasoning abilities of a single LLM? This work explores an orthogonal direction focusing on post-training LLMs for autoregressive searching (i.e., an extended reasoning process with self-reflection and self-exploration of new strategies). To achieve this, we propose the Chain-of-Action-Thought (COAT) reasoning and a two-stage training paradigm: 1) a small-scale format tuning stage to internalize the COAT reasoning format and 2) a large-scale self-improvement stage leveraging reinforcement learning. Our approach results in Satori, a 7B LLM trained on open-source models and data. Extensive empirical evaluations demonstrate that Satori achieves state-of-the-art performance on mathematical reasoning benchmarks while exhibits strong generalization to out-of-domain tasks. Code, data, and models will be fully open-sourced.
Guaranteeing Conservation Laws with Projection in Physics-Informed Neural Networks
Oct 22, 2024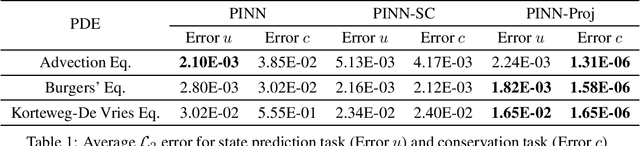
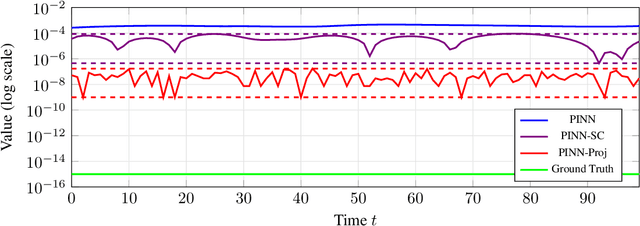
Physics-informed neural networks (PINNs) incorporate physical laws into their training to efficiently solve partial differential equations (PDEs) with minimal data. However, PINNs fail to guarantee adherence to conservation laws, which are also important to consider in modeling physical systems. To address this, we proposed PINN-Proj, a PINN-based model that uses a novel projection method to enforce conservation laws. We found that PINN-Proj substantially outperformed PINN in conserving momentum and lowered prediction error by three to four orders of magnitude from the best benchmark tested. PINN-Proj also performed marginally better in the separate task of state prediction on three PDE datasets.
The RealHumanEval: Evaluating Large Language Models' Abilities to Support Programmers
Apr 03, 2024



Evaluation of large language models (LLMs) for code has primarily relied on static benchmarks, including HumanEval (Chen et al., 2021), which measure the ability of LLMs to generate complete code that passes unit tests. As LLMs are increasingly used as programmer assistants, we study whether gains on existing benchmarks translate to gains in programmer productivity when coding with LLMs, including time spent coding. In addition to static benchmarks, we investigate the utility of preference metrics that might be used as proxies to measure LLM helpfulness, such as code acceptance or copy rates. To do so, we introduce RealHumanEval, a web interface to measure the ability of LLMs to assist programmers, through either autocomplete or chat support. We conducted a user study (N=213) using RealHumanEval in which users interacted with six LLMs of varying base model performance. Despite static benchmarks not incorporating humans-in-the-loop, we find that improvements in benchmark performance lead to increased programmer productivity; however gaps in benchmark versus human performance are not proportional -- a trend that holds across both forms of LLM support. In contrast, we find that programmer preferences do not correlate with their actual performance, motivating the need for better, human-centric proxy signals. We also open-source RealHumanEval to enable human-centric evaluation of new models and the study data to facilitate efforts to improve code models.
Improved Evidential Deep Learning via a Mixture of Dirichlet Distributions
Feb 09, 2024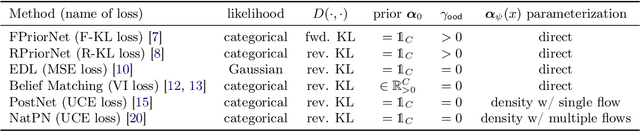
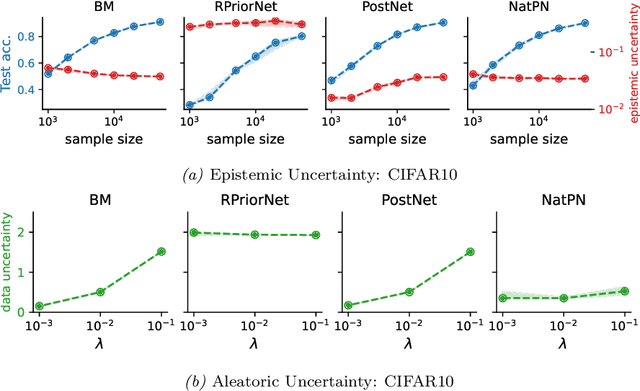
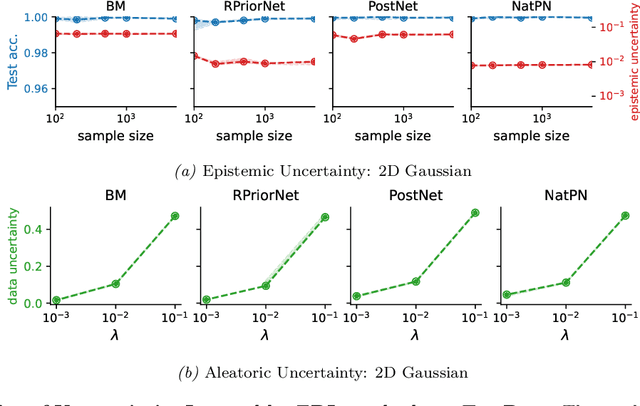
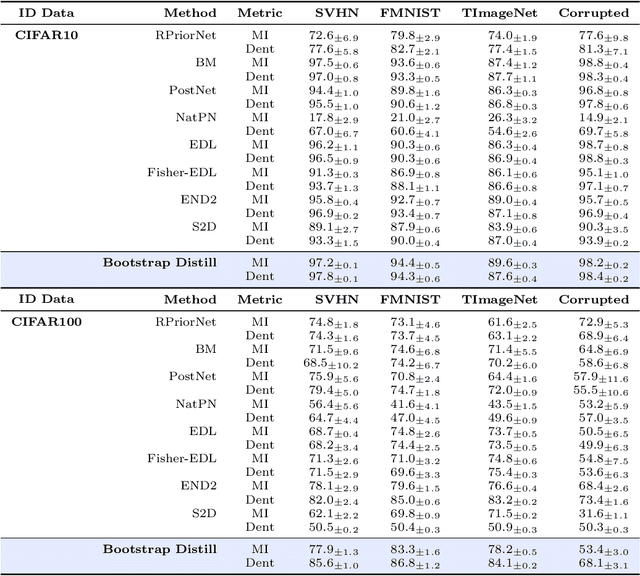
This paper explores a modern predictive uncertainty estimation approach, called evidential deep learning (EDL), in which a single neural network model is trained to learn a meta distribution over the predictive distribution by minimizing a specific objective function. Despite their strong empirical performance, recent studies by Bengs et al. identify a fundamental pitfall of the existing methods: the learned epistemic uncertainty may not vanish even in the infinite-sample limit. We corroborate the observation by providing a unifying view of a class of widely used objectives from the literature. Our analysis reveals that the EDL methods essentially train a meta distribution by minimizing a certain divergence measure between the distribution and a sample-size-independent target distribution, resulting in spurious epistemic uncertainty. Grounded in theoretical principles, we propose learning a consistent target distribution by modeling it with a mixture of Dirichlet distributions and learning via variational inference. Afterward, a final meta distribution model distills the learned uncertainty from the target model. Experimental results across various uncertainty-based downstream tasks demonstrate the superiority of our proposed method, and illustrate the practical implications arising from the consistency and inconsistency of learned epistemic uncertainty.
One step closer to unbiased aleatoric uncertainty estimation
Dec 20, 2023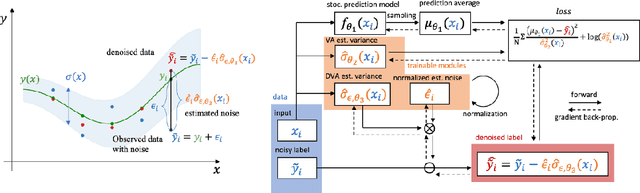


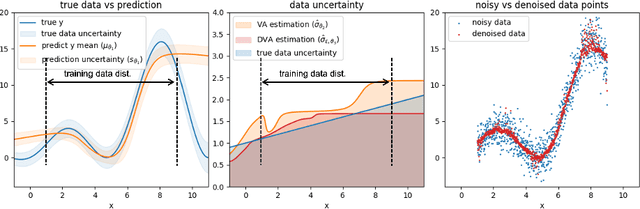
Neural networks are powerful tools in various applications, and quantifying their uncertainty is crucial for reliable decision-making. In the deep learning field, the uncertainties are usually categorized into aleatoric (data) and epistemic (model) uncertainty. In this paper, we point out that the existing popular variance attenuation method highly overestimates aleatoric uncertainty. To address this issue, we propose a new estimation method by actively de-noising the observed data. By conducting a broad range of experiments, we demonstrate that our proposed approach provides a much closer approximation to the actual data uncertainty than the standard method.
Correlated Attention in Transformers for Multivariate Time Series
Nov 20, 2023
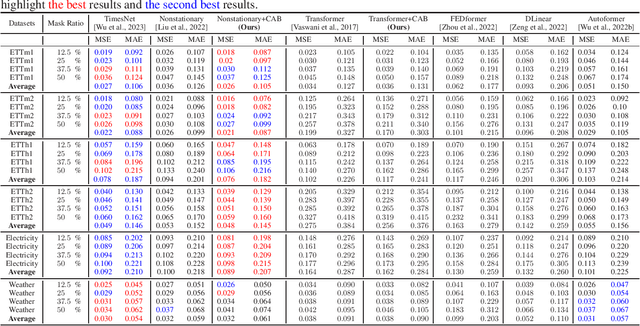

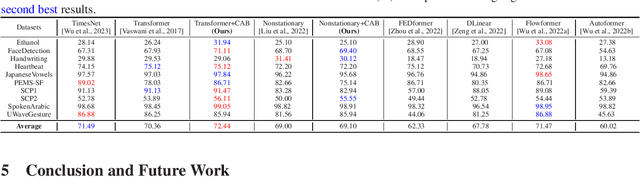
Multivariate time series (MTS) analysis prevails in real-world applications such as finance, climate science and healthcare. The various self-attention mechanisms, the backbone of the state-of-the-art Transformer-based models, efficiently discover the temporal dependencies, yet cannot well capture the intricate cross-correlation between different features of MTS data, which inherently stems from complex dynamical systems in practice. To this end, we propose a novel correlated attention mechanism, which not only efficiently captures feature-wise dependencies, but can also be seamlessly integrated within the encoder blocks of existing well-known Transformers to gain efficiency improvement. In particular, correlated attention operates across feature channels to compute cross-covariance matrices between queries and keys with different lag values, and selectively aggregate representations at the sub-series level. This architecture facilitates automated discovery and representation learning of not only instantaneous but also lagged cross-correlations, while inherently capturing time series auto-correlation. When combined with prevalent Transformer baselines, correlated attention mechanism constitutes a better alternative for encoder-only architectures, which are suitable for a wide range of tasks including imputation, anomaly detection and classification. Extensive experiments on the aforementioned tasks consistently underscore the advantages of correlated attention mechanism in enhancing base Transformer models, and demonstrate our state-of-the-art results in imputation, anomaly detection and classification.
Effective Human-AI Teams via Learned Natural Language Rules and Onboarding
Nov 07, 2023People are relying on AI agents to assist them with various tasks. The human must know when to rely on the agent, collaborate with the agent, or ignore its suggestions. In this work, we propose to learn rules, grounded in data regions and described in natural language, that illustrate how the human should collaborate with the AI. Our novel region discovery algorithm finds local regions in the data as neighborhoods in an embedding space where prior human behavior should be corrected. Each region is then described using a large language model in an iterative and contrastive procedure. We then teach these rules to the human via an onboarding stage. Through user studies on object detection and question-answering tasks, we show that our method can lead to more accurate human-AI teams. We also evaluate our region discovery and description algorithms separately.
Non-asymptotic System Identification for Linear Systems with Nonlinear Policies
Jun 17, 2023

This paper considers a single-trajectory system identification problem for linear systems under general nonlinear and/or time-varying policies with i.i.d. random excitation noises. The problem is motivated by safe learning-based control for constrained linear systems, where the safe policies during the learning process are usually nonlinear and time-varying for satisfying the state and input constraints. In this paper, we provide a non-asymptotic error bound for least square estimation when the data trajectory is generated by any nonlinear and/or time-varying policies as long as the generated state and action trajectories are bounded. This significantly generalizes the existing non-asymptotic guarantees for linear system identification, which usually consider i.i.d. random inputs or linear policies. Interestingly, our error bound is consistent with that for linear policies with respect to the dependence on the trajectory length, system dimensions, and excitation levels. Lastly, we demonstrate the applications of our results by safe learning with robust model predictive control and provide numerical analysis.