 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Agents Already Know When to Call Tools -- Even Without Reasoning
May 10, 2026Tool-augmented LLM agents tend to call tools indiscriminately, even when the model can answer directly. Each unnecessary call wastes API fees and latency, yet no existing benchmark systematically studies when a tool call is actually needed. We propose When2Tool, a benchmark of 18 environments (15 single-hop, 3 multi-hop) spanning three categories of tool necessity -- computational scale, knowledge boundaries, and execution reliability -- each with controlled difficulty levels that create a clear decision boundary between tool-necessary and tool-unnecessary tasks. We evaluate two families of training-free baselines: Prompt-only (varying the prompt to discourage unnecessary calls) and Reason-then-Act (requiring the model to reason about tool necessity before acting). Both provide limited control: Prompt-only suppresses necessary calls alongside unnecessary ones, and Reason-then-Act still incurs a disproportionate accuracy cost on hard tasks. To understand why these baselines fail, we probe the models' hidden states and find that tool necessity is linearly decodable from the pre-generation representation with AUROC 0.89--0.96 across six models, substantially exceeding the model's own verbalized reasoning. This reveals that models already know when tools are needed, but fail to act on this knowledge during generation. Building on this finding, we propose Probe&Prefill, which uses a lightweight linear probe to read the hidden-state signal and prefills the model's response with a steering sentence. Across all models tested, Probe&Prefill reduces tool calls by 48% with only 1.7% accuracy loss, while the best baseline at comparable accuracy only reduces 6% of tool calls, or achieves a similar tool call reduction but incurs a 5$\times$ higher accuracy loss. Our code is available at https://github.com/Trustworthy-ML-Lab/when2tool
CI-CBM: Class-Incremental Concept Bottleneck Model for Interpretable Continual Learning
Apr 16, 2026Catastrophic forgetting remains a fundamental challenge in continual learning, in which models often forget previous knowledge when fine-tuned on a new task. This issue is especially pronounced in class incremental learning (CIL), which is the most challenging setting in continual learning. Existing methods to address catastrophic forgetting often sacrifice either model interpretability or accuracy. To address this challenge, we introduce ClassIncremental Concept Bottleneck Model (CI-CBM), which leverage effective techniques, including concept regularization and pseudo-concept generation to maintain interpretable decision processes throughout incremental learning phases. Through extensive evaluation on seven datasets, CI-CBM achieves comparable performance to black-box models and outperforms previous interpretable approaches in CIL, with an average 36% accuracy gain. CICBM provides interpretable decisions on individual inputs and understandable global decision rules, as shown in our experiments, thereby demonstrating that human understandable concepts can be maintained during incremental learning without compromising model performance. Our approach is effective in both pretrained and non-pretrained scenarios; in the latter, the backbone is trained from scratch during the first learning phase. Code is publicly available at github.com/importAmir/CI-CBM.
* 31 pages, 6 figures. Published in Transactions on Machine Learning Research (TMLR), 04/2026
Steer2Edit: From Activation Steering to Component-Level Editing
Feb 10, 2026Steering methods influence Large Language Model behavior by identifying semantic directions in hidden representations, but are typically realized through inference-time activation interventions that apply a fixed, global modification to the model's internal states. While effective, such interventions often induce unfavorable attribute-utility trade-offs under strong control, as they ignore the fact that many behaviors are governed by a small and heterogeneous subset of model components. We propose Steer2Edit, a theoretically grounded, training-free framework that transforms steering vectors from inference-time control signals into diagnostic signals for component-level rank-1 weight editing. Instead of uniformly injecting a steering direction during generation, Steer2Edit selectively redistributes behavioral influence across individual attention heads and MLP neurons, yielding interpretable edits that preserve the standard forward pass and remain compatible with optimized parallel inference. Across safety alignment, hallucination mitigation, and reasoning efficiency, Steer2Edit consistently achieves more favorable attribute-utility trade-offs: at matched downstream performance, it improves safety by up to 17.2%, increases truthfulness by 9.8%, and reduces reasoning length by 12.2% on average. Overall, Steer2Edit provides a principled bridge between representation steering and weight editing by translating steering signals into interpretable, training-free parameter updates.
Distance Marching for Generative Modeling
Feb 03, 2026Time-unconditional generative models learn time-independent denoising vector fields. But without time conditioning, the same noisy input may correspond to multiple noise levels and different denoising directions, which interferes with the supervision signal. Inspired by distance field modeling, we propose Distance Marching, a new time-unconditional approach with two principled inference methods. Crucially, we design losses that focus on closer targets. This yields denoising directions better directed toward the data manifold. Across architectures, Distance Marching consistently improves FID by 13.5% on CIFAR-10 and ImageNet over recent time-unconditional baselines. For class-conditional ImageNet generation, despite removing time input, Distance Marching surpasses flow matching using our losses and inference methods. It achieves lower FID than flow matching's final performance using 60% of the sampling steps and 13.6% lower FID on average across backbone sizes. Moreover, our distance prediction is also helpful for early stopping during sampling and for OOD detection. We hope distance field modeling can serve as a principled lens for generative modeling.
Resting Neurons, Active Insights: Improving Input Sparsification for Large Language Models
Dec 14, 2025Large Language Models (LLMs) achieve state-of-the-art performance across a wide range of applications, but their massive scale poses significant challenges for both efficiency and interpretability. Structural pruning, which reduces model size by removing redundant computational units such as neurons, has been widely explored as a solution, and this study devotes to input sparsification, an increasingly popular technique that improves efficiency by selectively activating only a subset of entry values for each input. However, existing approaches focus primarily on computational savings, often overlooking the representational consequences of sparsification and leaving a noticeable performance gap compared to full models. In this work, we first reinterpret input sparsification as a form of dynamic structural pruning. Motivated by the spontaneous baseline firing rates observed in biological neurons, we introduce a small set of trainable spontaneous neurons that act as compensatory units to stabilize activations in sparsified LLMs. Experiments demonstrate that these auxiliary neurons substantially reduce the sparsification-induced performance gap while generalizing effectively across tasks.
Interpretable and Steerable Concept Bottleneck Sparse Autoencoders
Dec 11, 2025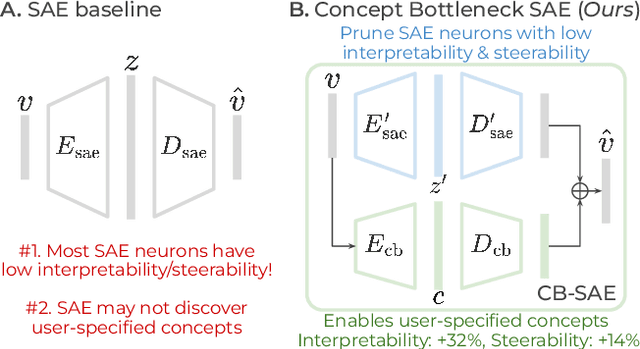



Sparse autoencoders (SAEs) promise a unified approach for mechanistic interpretability, concept discovery, and model steering in LLMs and LVLMs. However, realizing this potential requires that the learned features be both interpretable and steerable. To that end, we introduce two new computationally inexpensive interpretability and steerability metrics and conduct a systematic analysis on LVLMs. Our analysis uncovers two observations; (i) a majority of SAE neurons exhibit either low interpretability or low steerability or both, rendering them ineffective for downstream use; and (ii) due to the unsupervised nature of SAEs, user-desired concepts are often absent in the learned dictionary, thus limiting their practical utility. To address these limitations, we propose Concept Bottleneck Sparse Autoencoders (CB-SAE) - a novel post-hoc framework that prunes low-utility neurons and augments the latent space with a lightweight concept bottleneck aligned to a user-defined concept set. The resulting CB-SAE improves interpretability by +32.1% and steerability by +14.5% across LVLMs and image generation tasks. We will make our code and model weights available.
Graph Concept Bottleneck Models
Aug 19, 2025Concept Bottleneck Models (CBMs) provide explicit interpretations for deep neural networks through concepts and allow intervention with concepts to adjust final predictions. Existing CBMs assume concepts are conditionally independent given labels and isolated from each other, ignoring the hidden relationships among concepts. However, the set of concepts in CBMs often has an intrinsic structure where concepts are generally correlated: changing one concept will inherently impact its related concepts. To mitigate this limitation, we propose GraphCBMs: a new variant of CBM that facilitates concept relationships by constructing latent concept graphs, which can be combined with CBMs to enhance model performance while retaining their interpretability. Our experiment results on real-world image classification tasks demonstrate Graph CBMs offer the following benefits: (1) superior in image classification tasks while providing more concept structure information for interpretability; (2) able to utilize latent concept graphs for more effective interventions; and (3) robust in performance across different training and architecture settings.
Statistical Inference for Responsiveness Verification
Jul 02, 2025Many safety failures in machine learning arise when models are used to assign predictions to people (often in settings like lending, hiring, or content moderation) without accounting for how individuals can change their inputs. In this work, we introduce a formal validation procedure for the responsiveness of predictions with respect to interventions on their features. Our procedure frames responsiveness as a type of sensitivity analysis in which practitioners control a set of changes by specifying constraints over interventions and distributions over downstream effects. We describe how to estimate responsiveness for the predictions of any model and any dataset using only black-box access, and how to use these estimates to support tasks such as falsification and failure probability estimation. We develop algorithms that construct these estimates by generating a uniform sample of reachable points, and demonstrate how they can promote safety in real-world applications such as recidivism prediction, organ transplant prioritization, and content moderation.
Rethinking Crowd-Sourced Evaluation of Neuron Explanations
Jun 09, 2025Interpreting individual neurons or directions in activations space is an important component of mechanistic interpretability. As such, many algorithms have been proposed to automatically produce neuron explanations, but it is often not clear how reliable these explanations are, or which methods produce the best explanations. This can be measured via crowd-sourced evaluations, but they can often be noisy and expensive, leading to unreliable results. In this paper, we carefully analyze the evaluation pipeline and develop a cost-effective and highly accurate crowdsourced evaluation strategy. In contrast to previous human studies that only rate whether the explanation matches the most highly activating inputs, we estimate whether the explanation describes neuron activations across all inputs. To estimate this effectively, we introduce a novel application of importance sampling to determine which inputs are the most valuable to show to raters, leading to around 30x cost reduction compared to uniform sampling. We also analyze the label noise present in crowd-sourced evaluations and propose a Bayesian method to aggregate multiple ratings leading to a further ~5x reduction in number of ratings required for the same accuracy. Finally, we use these methods to conduct a large-scale study comparing the quality of neuron explanations produced by the most popular methods for two different vision models.
Evaluating Neuron Explanations: A Unified Framework with Sanity Checks
Jun 06, 2025Understanding the function of individual units in a neural network is an important building block for mechanistic interpretability. This is often done by generating a simple text explanation of the behavior of individual neurons or units. For these explanations to be useful, we must understand how reliable and truthful they are. In this work we unify many existing explanation evaluation methods under one mathematical framework. This allows us to compare existing evaluation metrics, understand the evaluation pipeline with increased clarity and apply existing statistical methods on the evaluation. In addition, we propose two simple sanity checks on the evaluation metrics and show that many commonly used metrics fail these tests and do not change their score after massive changes to the concept labels. Based on our experimental and theoretical results, we propose guidelines that future evaluations should follow and identify a set of reliable evaluation metrics.