 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable and Steerable Concept Bottleneck Sparse Autoencoders
Dec 11, 2025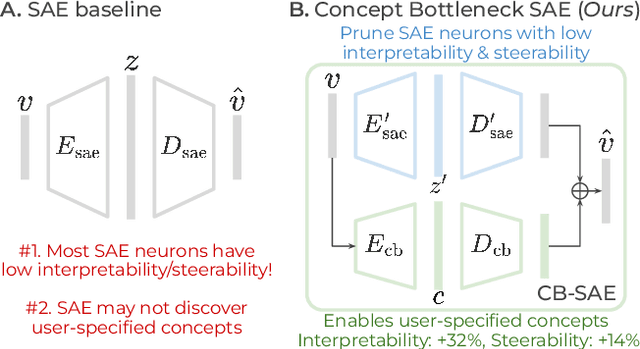



Sparse autoencoders (SAEs) promise a unified approach for mechanistic interpretability, concept discovery, and model steering in LLMs and LVLMs. However, realizing this potential requires that the learned features be both interpretable and steerable. To that end, we introduce two new computationally inexpensive interpretability and steerability metrics and conduct a systematic analysis on LVLMs. Our analysis uncovers two observations; (i) a majority of SAE neurons exhibit either low interpretability or low steerability or both, rendering them ineffective for downstream use; and (ii) due to the unsupervised nature of SAEs, user-desired concepts are often absent in the learned dictionary, thus limiting their practical utility. To address these limitations, we propose Concept Bottleneck Sparse Autoencoders (CB-SAE) - a novel post-hoc framework that prunes low-utility neurons and augments the latent space with a lightweight concept bottleneck aligned to a user-defined concept set. The resulting CB-SAE improves interpretability by +32.1% and steerability by +14.5% across LVLMs and image generation tasks. We will make our code and model weights available.
Rethinking Crowd-Sourced Evaluation of Neuron Explanations
Jun 09, 2025Interpreting individual neurons or directions in activations space is an important component of mechanistic interpretability. As such, many algorithms have been proposed to automatically produce neuron explanations, but it is often not clear how reliable these explanations are, or which methods produce the best explanations. This can be measured via crowd-sourced evaluations, but they can often be noisy and expensive, leading to unreliable results. In this paper, we carefully analyze the evaluation pipeline and develop a cost-effective and highly accurate crowdsourced evaluation strategy. In contrast to previous human studies that only rate whether the explanation matches the most highly activating inputs, we estimate whether the explanation describes neuron activations across all inputs. To estimate this effectively, we introduce a novel application of importance sampling to determine which inputs are the most valuable to show to raters, leading to around 30x cost reduction compared to uniform sampling. We also analyze the label noise present in crowd-sourced evaluations and propose a Bayesian method to aggregate multiple ratings leading to a further ~5x reduction in number of ratings required for the same accuracy. Finally, we use these methods to conduct a large-scale study comparing the quality of neuron explanations produced by the most popular methods for two different vision models.
Interpretable Generative Models through Post-hoc Concept Bottlenecks
Mar 25, 2025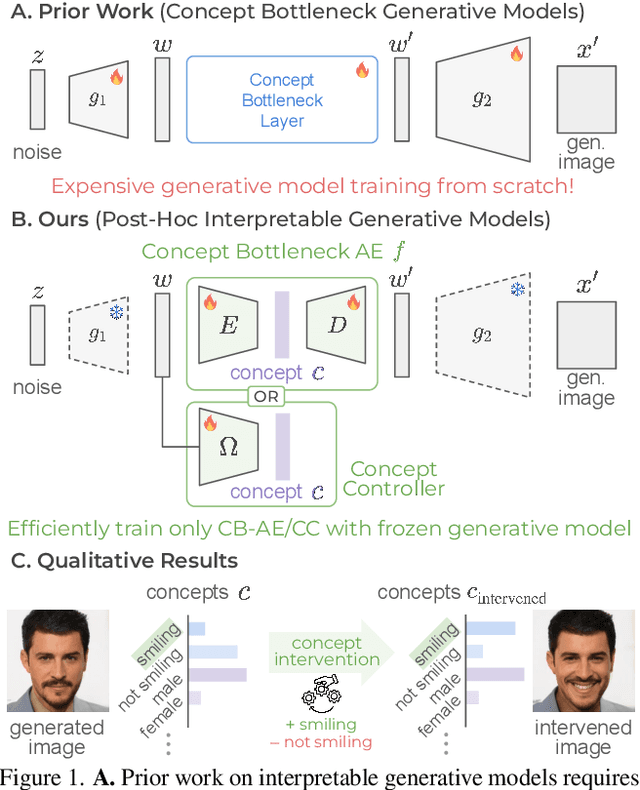



Concept bottleneck models (CBM) aim to produce inherently interpretable models that rely on human-understandable concepts for their predictions. However, existing approaches to design interpretable generative models based on CBMs are not yet efficient and scalable, as they require expensive generative model training from scratch as well as real images with labor-intensive concept supervision. To address these challenges, we present two novel and low-cost methods to build interpretable generative models through post-hoc techniques and we name our approaches: concept-bottleneck autoencoder (CB-AE) and concept controller (CC). Our proposed approaches enable efficient and scalable training without the need of real data and require only minimal to no concept supervision. Additionally, our methods generalize across modern generative model families including generative adversarial networks and diffusion models. We demonstrate the superior interpretability and steerability of our methods on numerous standard datasets like CelebA, CelebA-HQ, and CUB with large improvements (average ~25%) over the prior work, while being 4-15x faster to train. Finally, a large-scale user study is performed to validate the interpretability and steerability of our methods.
Aligning Non-Causal Factors for Transformer-Based Source-Free Domain Adaptation
Nov 27, 2023
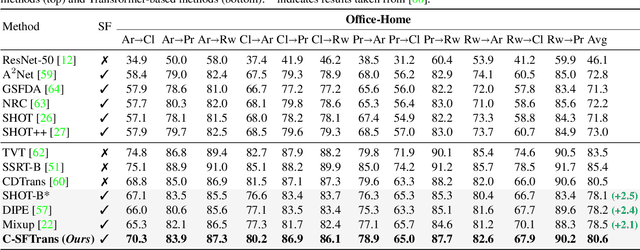


Conventional domain adaptation algorithms aim to achieve better generalization by aligning only the task-discriminative causal factors between a source and target domain. However, we find that retaining the spurious correlation between causal and non-causal factors plays a vital role in bridging the domain gap and improving target adaptation. Therefore, we propose to build a framework that disentangles and supports causal factor alignment by aligning the non-causal factors first. We also investigate and find that the strong shape bias of vision transformers, coupled with its multi-head attention, make it a suitable architecture for realizing our proposed disentanglement. Hence, we propose to build a Causality-enforcing Source-Free Transformer framework (C-SFTrans) to achieve disentanglement via a novel two-stage alignment approach: a) non-causal factor alignment: non-causal factors are aligned using a style classification task which leads to an overall global alignment, b) task-discriminative causal factor alignment: causal factors are aligned via target adaptation. We are the first to investigate the role of vision transformers (ViTs) in a privacy-preserving source-free setting. Our approach achieves state-of-the-art results in several DA benchmarks.
Domain-Specificity Inducing Transformers for Source-Free Domain Adaptation
Aug 27, 2023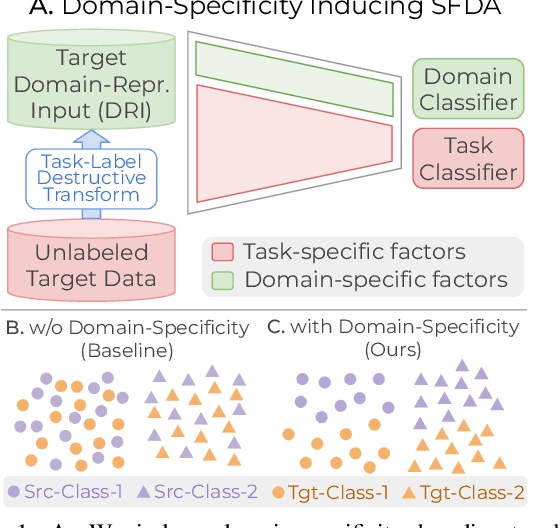
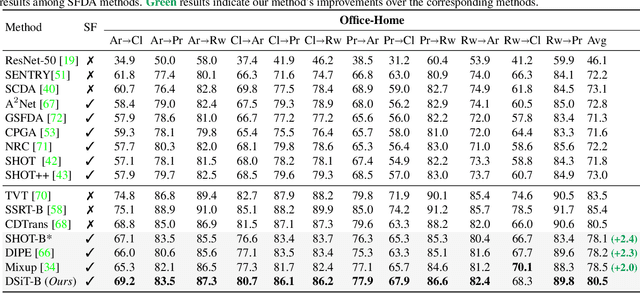
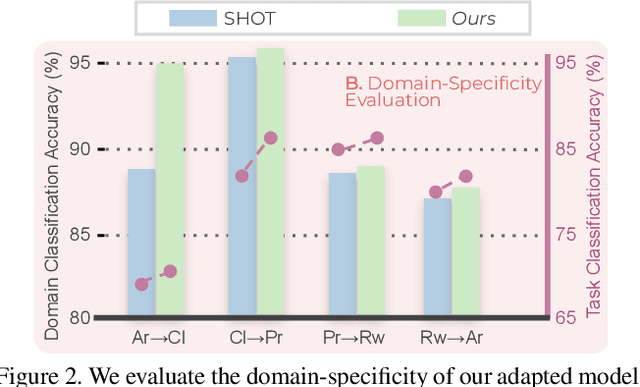

Conventional Domain Adaptation (DA) methods aim to learn domain-invariant feature representations to improve the target adaptation performance. However, we motivate that domain-specificity is equally important since in-domain trained models hold crucial domain-specific properties that are beneficial for adaptation. Hence, we propose to build a framework that supports disentanglement and learning of domain-specific factors and task-specific factors in a unified model. Motivated by the success of vision transformers in several multi-modal vision problems, we find that queries could be leveraged to extract the domain-specific factors. Hence, we propose a novel Domain-specificity-inducing Transformer (DSiT) framework for disentangling and learning both domain-specific and task-specific factors. To achieve disentanglement, we propose to construct novel Domain-Representative Inputs (DRI) with domain-specific information to train a domain classifier with a novel domain token. We are the first to utilize vision transformers for domain adaptation in a privacy-oriented source-free setting, and our approach achieves state-of-the-art performance on single-source, multi-source, and multi-target benchmarks
Subsidiary Prototype Alignment for Universal Domain Adaptation
Oct 28, 2022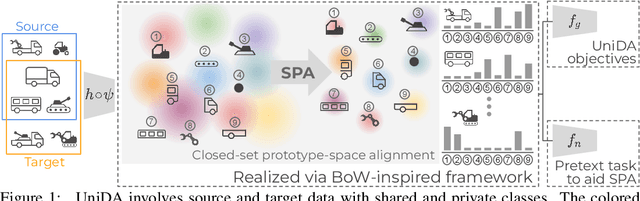
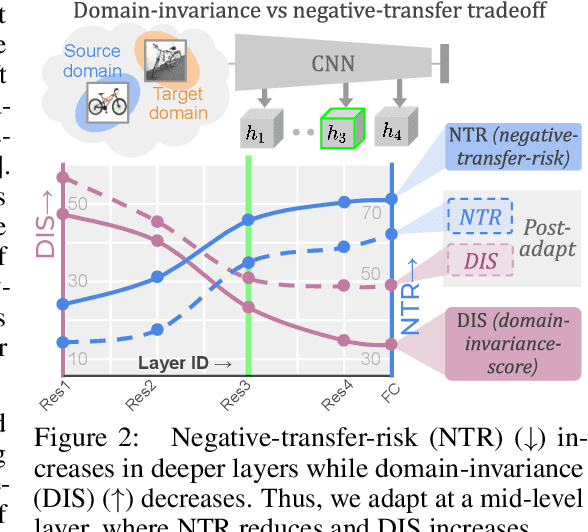
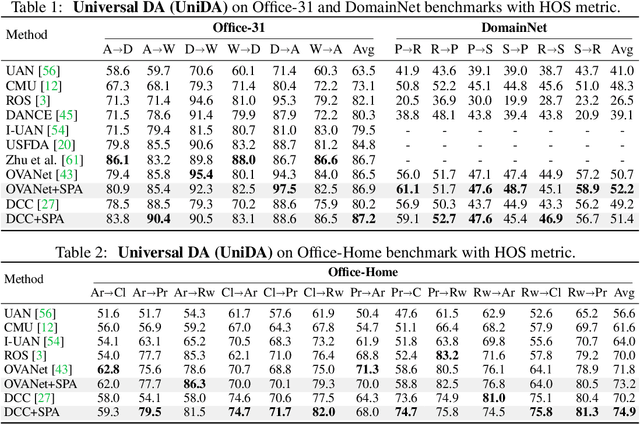
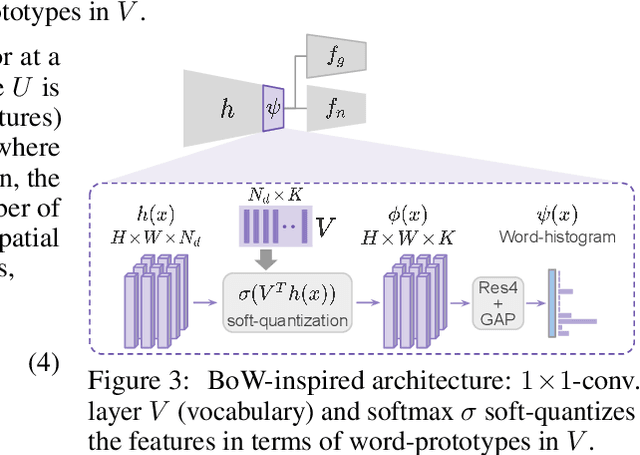
Universal Domain Adaptation (UniDA) deals with the problem of knowledge transfer between two datasets with domain-shift as well as category-shift. The goal is to categorize unlabeled target samples, either into one of the "known" categories or into a single "unknown" category. A major problem in UniDA is negative transfer, i.e. misalignment of "known" and "unknown" classes. To this end, we first uncover an intriguing tradeoff between negative-transfer-risk and domain-invariance exhibited at different layers of a deep network. It turns out we can strike a balance between these two metrics at a mid-level layer. Towards designing an effective framework based on this insight, we draw motivation from Bag-of-visual-Words (BoW). Word-prototypes in a BoW-like representation of a mid-level layer would represent lower-level visual primitives that are likely to be unaffected by the category-shift in the high-level features. We develop modifications that encourage learning of word-prototypes followed by word-histogram based classification. Following this, subsidiary prototype-space alignment (SPA) can be seen as a closed-set alignment problem, thereby avoiding negative transfer. We realize this with a novel word-histogram-related pretext task to enable closed-set SPA, operating in conjunction with goal task UniDA. We demonstrate the efficacy of our approach on top of existing UniDA techniques, yielding state-of-the-art performance across three standard UniDA and Open-Set DA object recognition benchmarks.
Concurrent Subsidiary Supervision for Unsupervised Source-Free Domain Adaptation
Jul 27, 2022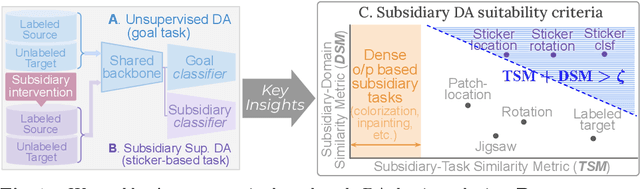
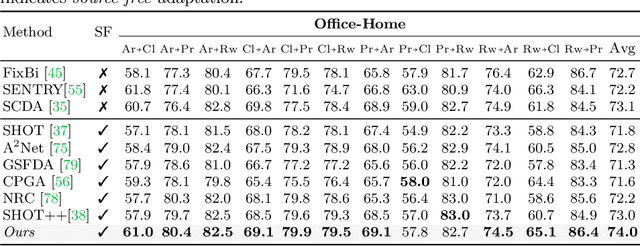
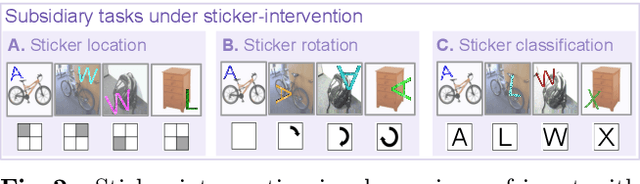
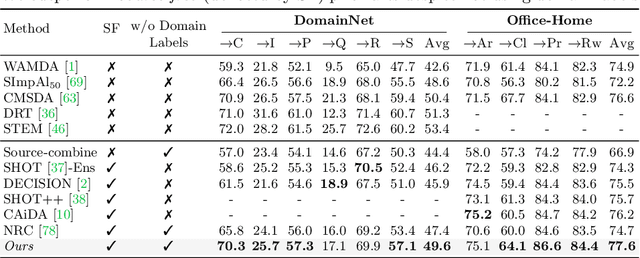
The prime challenge in unsupervised domain adaptation (DA) is to mitigate the domain shift between the source and target domains. Prior DA works show that pretext tasks could be used to mitigate this domain shift by learning domain invariant representations. However, in practice, we find that most existing pretext tasks are ineffective against other established techniques. Thus, we theoretically analyze how and when a subsidiary pretext task could be leveraged to assist the goal task of a given DA problem and develop objective subsidiary task suitability criteria. Based on this criteria, we devise a novel process of sticker intervention and cast sticker classification as a supervised subsidiary DA problem concurrent to the goal task unsupervised DA. Our approach not only improves goal task adaptation performance, but also facilitates privacy-oriented source-free DA i.e. without concurrent source-target access. Experiments on the standard Office-31, Office-Home, DomainNet, and VisDA benchmarks demonstrate our superiority for both single-source and multi-source source-free DA. Our approach also complements existing non-source-free works, achieving leading performance.
Balancing Discriminability and Transferability for Source-Free Domain Adaptation
Jun 16, 2022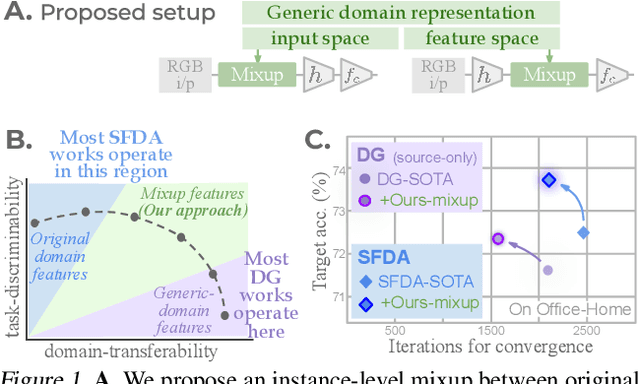
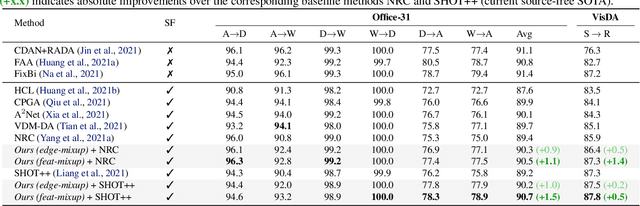
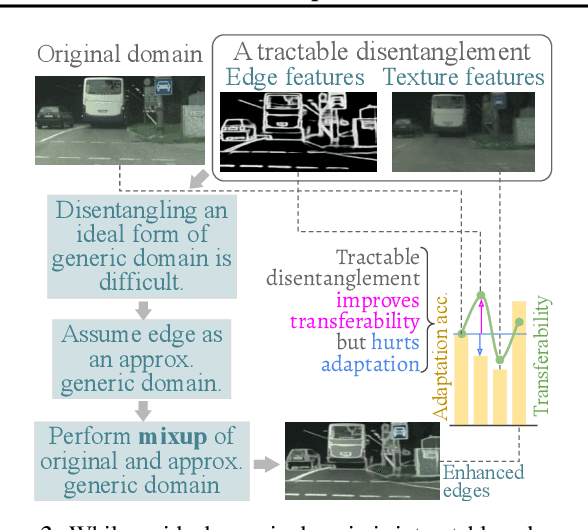
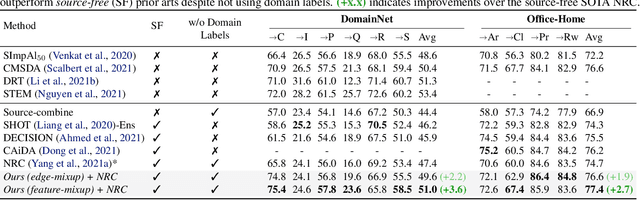
Conventional domain adaptation (DA) techniques aim to improve domain transferability by learning domain-invariant representations; while concurrently preserving the task-discriminability knowledge gathered from the labeled source data. However, the requirement of simultaneous access to labeled source and unlabeled target renders them unsuitable for the challenging source-free DA setting. The trivial solution of realizing an effective original to generic domain mapping improves transferability but degrades task discriminability. Upon analyzing the hurdles from both theoretical and empirical standpoints, we derive novel insights to show that a mixup between original and corresponding translated generic samples enhances the discriminability-transferability trade-off while duly respecting the privacy-oriented source-free setting. A simple but effective realization of the proposed insights on top of the existing source-free DA approaches yields state-of-the-art performance with faster convergence. Beyond single-source, we also outperform multi-source prior-arts across both classification and semantic segmentation benchmarks.
Amplitude Spectrum Transformation for Open Compound Domain Adaptive Semantic Segmentation
Feb 09, 2022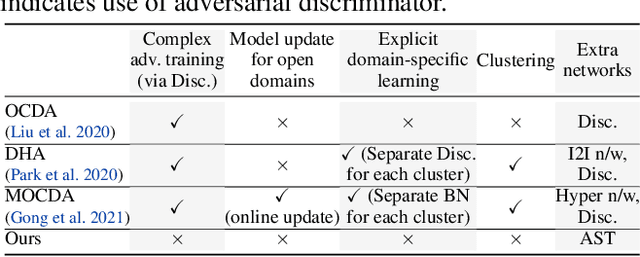
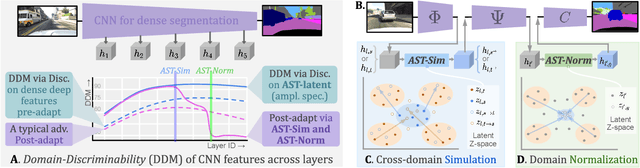
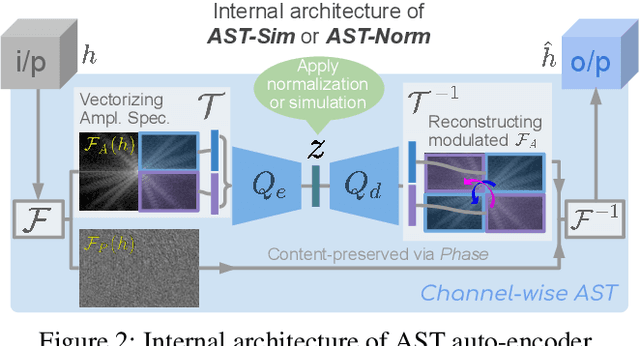
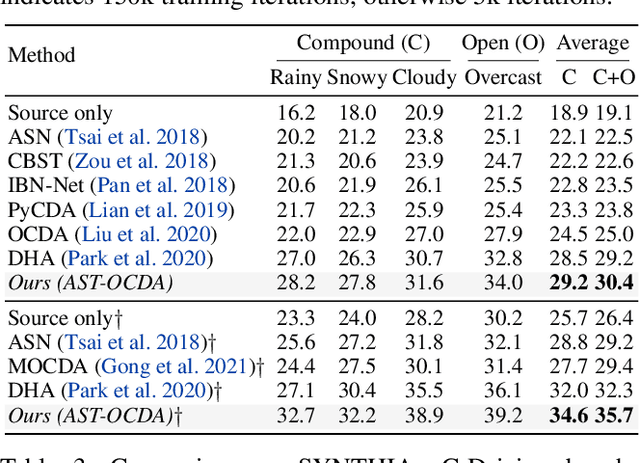
Open compound domain adaptation (OCDA) has emerged as a practical adaptation setting which considers a single labeled source domain against a compound of multi-modal unlabeled target data in order to generalize better on novel unseen domains. We hypothesize that an improved disentanglement of domain-related and task-related factors of dense intermediate layer features can greatly aid OCDA. Prior-arts attempt this indirectly by employing adversarial domain discriminators on the spatial CNN output. However, we find that latent features derived from the Fourier-based amplitude spectrum of deep CNN features hold a more tractable mapping with domain discrimination. Motivated by this, we propose a novel feature space Amplitude Spectrum Transformation (AST). During adaptation, we employ the AST auto-encoder for two purposes. First, carefully mined source-target instance pairs undergo a simulation of cross-domain feature stylization (AST-Sim) at a particular layer by altering the AST-latent. Second, AST operating at a later layer is tasked to normalize (AST-Norm) the domain content by fixing its latent to a mean prototype. Our simplified adaptation technique is not only clustering-free but also free from complex adversarial alignment. We achieve leading performance against the prior arts on the OCDA scene segmentation benchmarks.
Generalize then Adapt: Source-Free Domain Adaptive Semantic Segmentation
Aug 25, 2021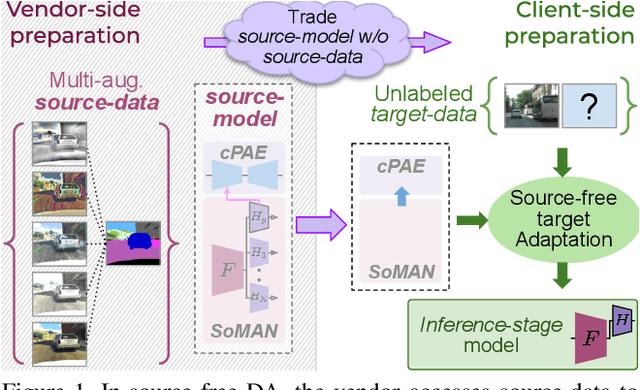
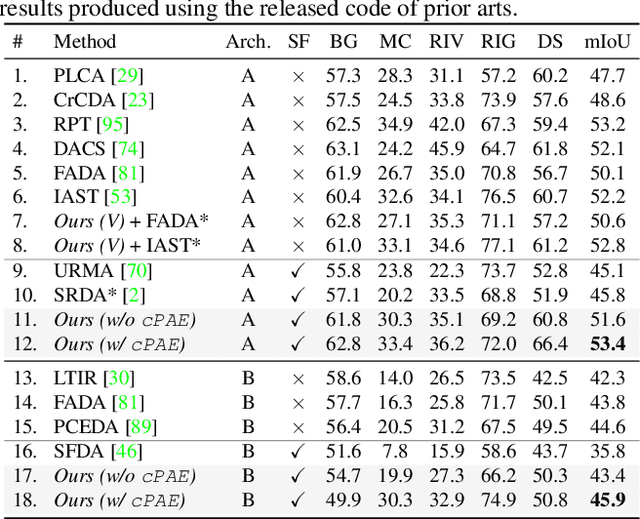

Unsupervised domain adaptation (DA) has gained substantial interest in semantic segmentation. However, almost all prior arts assume concurrent access to both labeled source and unlabeled target, making them unsuitable for scenarios demanding source-free adaptation. In this work, we enable source-free DA by partitioning the task into two: a) source-only domain generalization and b) source-free target adaptation. Towards the former, we provide theoretical insights to develop a multi-head framework trained with a virtually extended multi-source dataset, aiming to balance generalization and specificity. Towards the latter, we utilize the multi-head framework to extract reliable target pseudo-labels for self-training. Additionally, we introduce a novel conditional prior-enforcing auto-encoder that discourages spatial irregularities, thereby enhancing the pseudo-label quality. Experiments on the standard GTA5-to-Cityscapes and SYNTHIA-to-Cityscapes benchmarks show our superiority even against the non-source-free prior-arts. Further, we show our compatibility with online adaptation enabling deployment in a sequentially changing environment.