 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistance Marching for Generative Modeling
Feb 03, 2026Time-unconditional generative models learn time-independent denoising vector fields. But without time conditioning, the same noisy input may correspond to multiple noise levels and different denoising directions, which interferes with the supervision signal. Inspired by distance field modeling, we propose Distance Marching, a new time-unconditional approach with two principled inference methods. Crucially, we design losses that focus on closer targets. This yields denoising directions better directed toward the data manifold. Across architectures, Distance Marching consistently improves FID by 13.5% on CIFAR-10 and ImageNet over recent time-unconditional baselines. For class-conditional ImageNet generation, despite removing time input, Distance Marching surpasses flow matching using our losses and inference methods. It achieves lower FID than flow matching's final performance using 60% of the sampling steps and 13.6% lower FID on average across backbone sizes. Moreover, our distance prediction is also helpful for early stopping during sampling and for OOD detection. We hope distance field modeling can serve as a principled lens for generative modeling.
ReflCtrl: Controlling LLM Reflection via Representation Engineering
Dec 16, 2025Large language models (LLMs) with Chain-of-Thought (CoT) reasoning have achieved strong performance across diverse tasks, including mathematics, coding, and general reasoning. A distinctive ability of these reasoning models is self-reflection: the ability to review and revise previous reasoning steps. While self-reflection enhances reasoning performance, it also increases inference cost. In this work, we study self-reflection through the lens of representation engineering. We segment the model's reasoning into steps, identify the steps corresponding to reflection, and extract a reflection direction in the latent space that governs this behavior. Using this direction, we propose a stepwise steering method that can control reflection frequency. We call our framework ReflCtrl. Our experiments show that (1) in many cases reflections are redundant, especially in stronger models (in our experiments, we can save up to 33.6 percent of reasoning tokens while preserving performance), and (2) the model's reflection behavior is highly correlated with an internal uncertainty signal, implying self-reflection may be controlled by the model's uncertainty.
Effective Skill Unlearning through Intervention and Abstention
Mar 27, 2025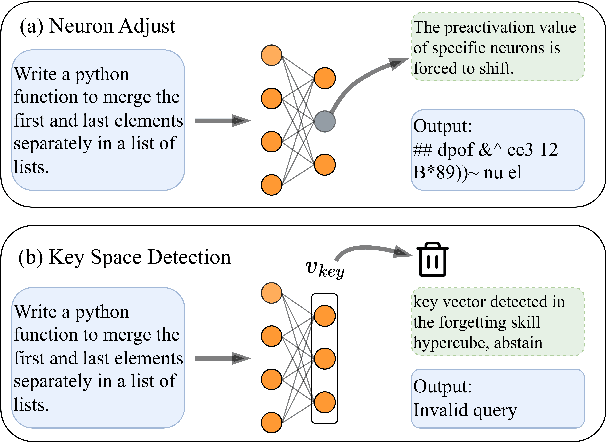
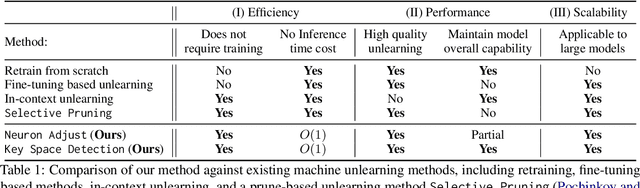
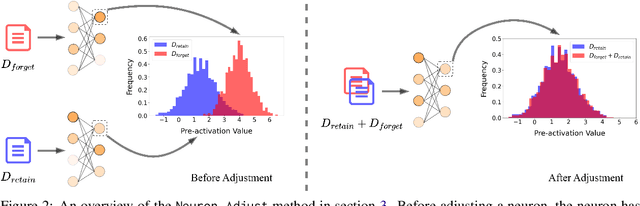
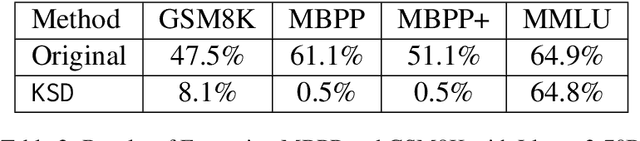
Large language Models (LLMs) have demonstrated remarkable skills across various domains. Understanding the mechanisms behind their abilities and implementing controls over them is becoming increasingly important for developing better models. In this paper, we focus on skill unlearning in LLMs, specifically unlearning a particular skill while retaining their overall capabilities. We introduce two lightweight, training-free machine skill unlearning techniques for LLMs. First, we observe that the pre-activation distribution of neurons in each Feed-Forward Layer (FFL) differs when the model demonstrates different skills. Additionally, we find that queries triggering the same skill cluster within the FFL key space and can be separated from other queries using a hypercube. Based on these observations, we propose two lightweight, training-free skill unlearning methods via \textit{intervention} and \textit{abstention} respectively: \texttt{Neuron Adjust} and \texttt{Key Space Detection}. We evaluate our methods on unlearning math-solving, Python-coding, and comprehension skills across seven different languages. The results demonstrate their strong unlearning capabilities for the designated skills. Specifically, \texttt{Key Space Detection} achieves over 80\% relative performance drop on the forgetting skill and less than 10\% relative performance drop on other skills and the model's general knowledge (MMLU) for most unlearning tasks. Our code is available at https://github.com/Trustworthy-ML-Lab/effective_skill_unlearning
ThinkEdit: Interpretable Weight Editing to Mitigate Overly Short Thinking in Reasoning Models
Mar 27, 2025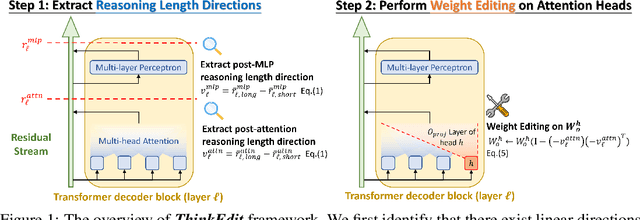

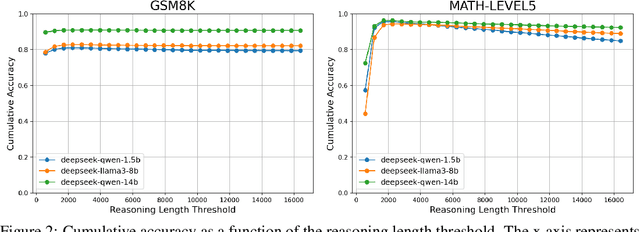

Recent studies have shown that Large Language Models (LLMs) augmented with chain-of-thought (CoT) reasoning demonstrate impressive problem-solving abilities. However, in this work, we identify a recurring issue where these models occasionally generate overly short reasoning, leading to degraded performance on even simple mathematical problems. Specifically, we investigate how reasoning length is embedded in the hidden representations of reasoning models and its impact on accuracy. Our analysis reveals that reasoning length is governed by a linear direction in the representation space, allowing us to induce overly short reasoning by steering the model along this direction. Building on this insight, we introduce ThinkEdit, a simple yet effective weight-editing approach to mitigate the issue of overly short reasoning. We first identify a small subset of attention heads (approximately 2%) that predominantly drive short reasoning behavior. We then edit the output projection weights of these heads to suppress the short reasoning direction. With changes to only 0.1% of the model's parameters, ThinkEdit effectively reduces overly short reasoning and yields notable accuracy gains for short reasoning outputs (+5.44%), along with an overall improvement across multiple math benchmarks (+2.43%). Our findings provide new mechanistic insights into how reasoning length is controlled within LLMs and highlight the potential of fine-grained model interventions to improve reasoning quality. Our code is available at https://github.com/Trustworthy-ML-Lab/ThinkEdit
Interpretable Generative Models through Post-hoc Concept Bottlenecks
Mar 25, 2025Concept bottleneck models (CBM) aim to produce inherently interpretable models that rely on human-understandable concepts for their predictions. However, existing approaches to design interpretable generative models based on CBMs are not yet efficient and scalable, as they require expensive generative model training from scratch as well as real images with labor-intensive concept supervision. To address these challenges, we present two novel and low-cost methods to build interpretable generative models through post-hoc techniques and we name our approaches: concept-bottleneck autoencoder (CB-AE) and concept controller (CC). Our proposed approaches enable efficient and scalable training without the need of real data and require only minimal to no concept supervision. Additionally, our methods generalize across modern generative model families including generative adversarial networks and diffusion models. We demonstrate the superior interpretability and steerability of our methods on numerous standard datasets like CelebA, CelebA-HQ, and CUB with large improvements (average ~25%) over the prior work, while being 4-15x faster to train. Finally, a large-scale user study is performed to validate the interpretability and steerability of our methods.
Concept Bottleneck Large Language Models
Dec 11, 2024



We introduce the Concept Bottleneck Large Language Model (CB-LLM), a pioneering approach to creating inherently interpretable Large Language Models (LLMs). Unlike traditional black-box LLMs that rely on post-hoc interpretation methods with limited neuron function insights, CB-LLM sets a new standard with its built-in interpretability, scalability, and ability to provide clear, accurate explanations. We investigate two essential tasks in the NLP domain: text classification and text generation. In text classification, CB-LLM narrows the performance gap with traditional black-box models and provides clear interpretability. In text generation, we show how interpretable neurons in CB-LLM can be used for concept detection and steering text generation. Our CB-LLMs enable greater interaction between humans and LLMs across a variety of tasks -- a feature notably absent in existing LLMs. Our code is available at https://github.com/Trustworthy-ML-Lab/CB-LLMs.
Iterative Self-Tuning LLMs for Enhanced Jailbreaking Capabilities
Oct 24, 2024



Recent research has shown that Large Language Models (LLMs) are vulnerable to automated jailbreak attacks, where adversarial suffixes crafted by algorithms appended to harmful queries bypass safety alignment and trigger unintended responses. Current methods for generating these suffixes are computationally expensive and have low Attack Success Rates (ASR), especially against well-aligned models like Llama2 and Llama3. To overcome these limitations, we introduce ADV-LLM, an iterative self-tuning process that crafts adversarial LLMs with enhanced jailbreak ability. Our framework significantly reduces the computational cost of generating adversarial suffixes while achieving nearly 100\% ASR on various open-source LLMs. Moreover, it exhibits strong attack transferability to closed-source models, achieving 99% ASR on GPT-3.5 and 49% ASR on GPT-4, despite being optimized solely on Llama3. Beyond improving jailbreak ability, ADV-LLM provides valuable insights for future safety alignment research through its ability to generate large datasets for studying LLM safety. Our code is available at: https://github.com/SunChungEn/ADV-LLM
Crafting Large Language Models for Enhanced Interpretability
Jul 05, 2024



We introduce the Concept Bottleneck Large Language Model (CB-LLM), a pioneering approach to creating inherently interpretable Large Language Models (LLMs). Unlike traditional black-box LLMs that rely on post-hoc interpretation methods with limited neuron function insights, CB-LLM sets a new standard with its built-in interpretability, scalability, and ability to provide clear, accurate explanations. This innovation not only advances transparency in language models but also enhances their effectiveness. Our unique Automatic Concept Correction (ACC) strategy successfully narrows the performance gap with conventional black-box LLMs, positioning CB-LLM as a model that combines the high accuracy of traditional LLMs with the added benefit of clear interpretability -- a feature markedly absent in existing LLMs.
Breaking the Barrier: Enhanced Utility and Robustness in Smoothed DRL Agents
Jun 26, 2024



Robustness remains a paramount concern in deep reinforcement learning (DRL), with randomized smoothing emerging as a key technique for enhancing this attribute. However, a notable gap exists in the performance of current smoothed DRL agents, often characterized by significantly low clean rewards and weak robustness. In response to this challenge, our study introduces innovative algorithms aimed at training effective smoothed robust DRL agents. We propose S-DQN and S-PPO, novel approaches that demonstrate remarkable improvements in clean rewards, empirical robustness, and robustness guarantee across standard RL benchmarks. Notably, our S-DQN and S-PPO agents not only significantly outperform existing smoothed agents by an average factor of $2.16\times$ under the strongest attack, but also surpass previous robustly-trained agents by an average factor of $2.13\times$. This represents a significant leap forward in the field. Furthermore, we introduce Smoothed Attack, which is $1.89\times$ more effective in decreasing the rewards of smoothed agents than existing adversarial attacks.
NTIRE 2020 Challenge on NonHomogeneous Dehazing
May 07, 2020
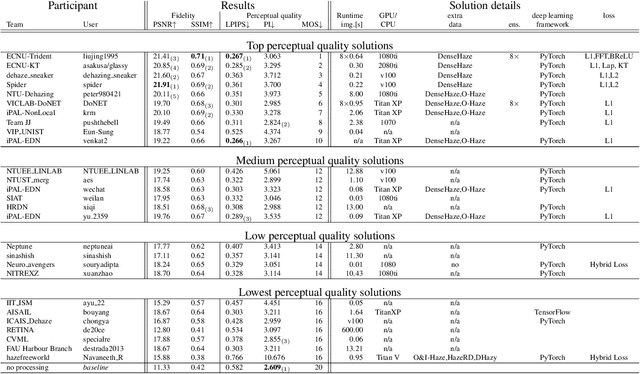
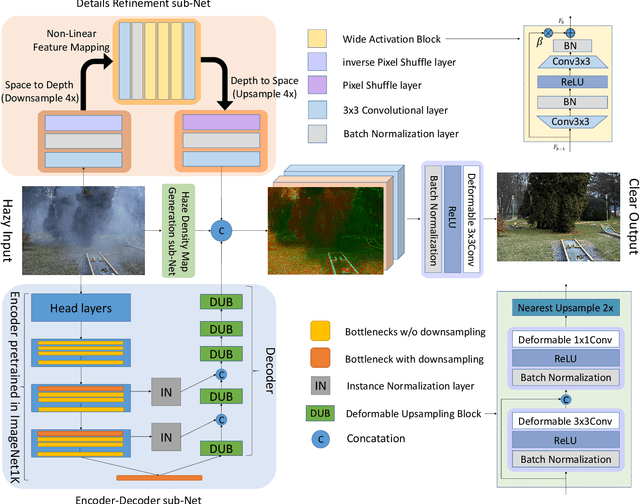
This paper reviews the NTIRE 2020 Challenge on NonHomogeneous Dehazing of images (restoration of rich details in hazy image). We focus on the proposed solutions and their results evaluated on NH-Haze, a novel dataset consisting of 55 pairs of real haze free and nonhomogeneous hazy images recorded outdoor. NH-Haze is the first realistic nonhomogeneous haze dataset that provides ground truth images. The nonhomogeneous haze has been produced using a professional haze generator that imitates the real conditions of haze scenes. 168 participants registered in the challenge and 27 teams competed in the final testing phase. The proposed solutions gauge the state-of-the-art in image dehazing.