 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Concept Bottleneck Models
Jun 18, 2026Concept Bottleneck Models (CBMs) enhance the interpretability of deep learning networks by aligning the features extracted from images with natural concepts. However, existing CBMs are constrained in their ability to generalize beyond a fixed set of predefined classes and the risk of non-concept information leakage, where predictive signals outside the intended concepts are inadvertently exploited. In this paper, we propose Multimodal Concept Bottleneck Model (MM-CBM) to address these issues and extend CBMs into CLIP. MM-CBM utilizes dual Concept Bottleneck Layers (CBLs) to align both the image and text embeddings into interpretable features. This allows us to perform new vision tasks like zero-shot classification or image retrieval in an interpretable way. Compared to existing methods, MM-CBM achieves up to 51.26% accuracy improvement on average across four standard benchmarks. Our method maintains high accuracy, staying within ~5% of black-box performance while offering greater interpretability.
CI-CBM: Class-Incremental Concept Bottleneck Model for Interpretable Continual Learning
Apr 16, 2026Catastrophic forgetting remains a fundamental challenge in continual learning, in which models often forget previous knowledge when fine-tuned on a new task. This issue is especially pronounced in class incremental learning (CIL), which is the most challenging setting in continual learning. Existing methods to address catastrophic forgetting often sacrifice either model interpretability or accuracy. To address this challenge, we introduce ClassIncremental Concept Bottleneck Model (CI-CBM), which leverage effective techniques, including concept regularization and pseudo-concept generation to maintain interpretable decision processes throughout incremental learning phases. Through extensive evaluation on seven datasets, CI-CBM achieves comparable performance to black-box models and outperforms previous interpretable approaches in CIL, with an average 36% accuracy gain. CICBM provides interpretable decisions on individual inputs and understandable global decision rules, as shown in our experiments, thereby demonstrating that human understandable concepts can be maintained during incremental learning without compromising model performance. Our approach is effective in both pretrained and non-pretrained scenarios; in the latter, the backbone is trained from scratch during the first learning phase. Code is publicly available at github.com/importAmir/CI-CBM.
* 31 pages, 6 figures. Published in Transactions on Machine Learning Research (TMLR), 04/2026
Faithful and Stable Neuron Explanations for Trustworthy Mechanistic Interpretability
Dec 19, 2025Neuron identification is a popular tool in mechanistic interpretability, aiming to uncover the human-interpretable concepts represented by individual neurons in deep networks. While algorithms such as Network Dissection and CLIP-Dissect achieve great empirical success, a rigorous theoretical foundation remains absent, which is crucial to enable trustworthy and reliable explanations. In this work, we observe that neuron identification can be viewed as the inverse process of machine learning, which allows us to derive guarantees for neuron explanations. Based on this insight, we present the first theoretical analysis of two fundamental challenges: (1) Faithfulness: whether the identified concept faithfully represents the neuron's underlying function and (2) Stability: whether the identification results are consistent across probing datasets. We derive generalization bounds for widely used similarity metrics (e.g. accuracy, AUROC, IoU) to guarantee faithfulness, and propose a bootstrap ensemble procedure that quantifies stability along with BE (Bootstrap Explanation) method to generate concept prediction sets with guaranteed coverage probability. Experiments on both synthetic and real data validate our theoretical results and demonstrate the practicality of our method, providing an important step toward trustworthy neuron identification.
Rethinking Crowd-Sourced Evaluation of Neuron Explanations
Jun 09, 2025Interpreting individual neurons or directions in activations space is an important component of mechanistic interpretability. As such, many algorithms have been proposed to automatically produce neuron explanations, but it is often not clear how reliable these explanations are, or which methods produce the best explanations. This can be measured via crowd-sourced evaluations, but they can often be noisy and expensive, leading to unreliable results. In this paper, we carefully analyze the evaluation pipeline and develop a cost-effective and highly accurate crowdsourced evaluation strategy. In contrast to previous human studies that only rate whether the explanation matches the most highly activating inputs, we estimate whether the explanation describes neuron activations across all inputs. To estimate this effectively, we introduce a novel application of importance sampling to determine which inputs are the most valuable to show to raters, leading to around 30x cost reduction compared to uniform sampling. We also analyze the label noise present in crowd-sourced evaluations and propose a Bayesian method to aggregate multiple ratings leading to a further ~5x reduction in number of ratings required for the same accuracy. Finally, we use these methods to conduct a large-scale study comparing the quality of neuron explanations produced by the most popular methods for two different vision models.
Evaluating Neuron Explanations: A Unified Framework with Sanity Checks
Jun 06, 2025Understanding the function of individual units in a neural network is an important building block for mechanistic interpretability. This is often done by generating a simple text explanation of the behavior of individual neurons or units. For these explanations to be useful, we must understand how reliable and truthful they are. In this work we unify many existing explanation evaluation methods under one mathematical framework. This allows us to compare existing evaluation metrics, understand the evaluation pipeline with increased clarity and apply existing statistical methods on the evaluation. In addition, we propose two simple sanity checks on the evaluation metrics and show that many commonly used metrics fail these tests and do not change their score after massive changes to the concept labels. Based on our experimental and theoretical results, we propose guidelines that future evaluations should follow and identify a set of reliable evaluation metrics.
Interpretable Generative Models through Post-hoc Concept Bottlenecks
Mar 25, 2025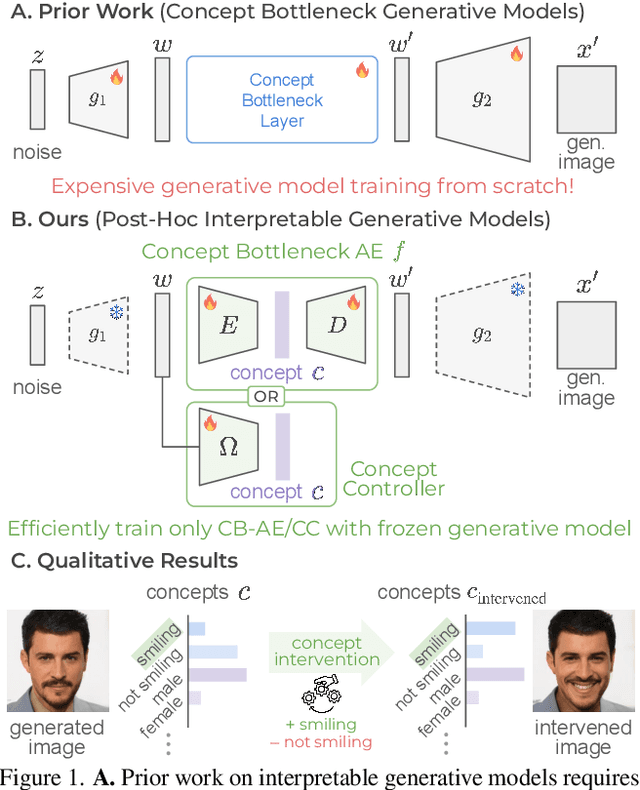



Concept bottleneck models (CBM) aim to produce inherently interpretable models that rely on human-understandable concepts for their predictions. However, existing approaches to design interpretable generative models based on CBMs are not yet efficient and scalable, as they require expensive generative model training from scratch as well as real images with labor-intensive concept supervision. To address these challenges, we present two novel and low-cost methods to build interpretable generative models through post-hoc techniques and we name our approaches: concept-bottleneck autoencoder (CB-AE) and concept controller (CC). Our proposed approaches enable efficient and scalable training without the need of real data and require only minimal to no concept supervision. Additionally, our methods generalize across modern generative model families including generative adversarial networks and diffusion models. We demonstrate the superior interpretability and steerability of our methods on numerous standard datasets like CelebA, CelebA-HQ, and CUB with large improvements (average ~25%) over the prior work, while being 4-15x faster to train. Finally, a large-scale user study is performed to validate the interpretability and steerability of our methods.
Concept Bottleneck Large Language Models
Dec 11, 2024



We introduce the Concept Bottleneck Large Language Model (CB-LLM), a pioneering approach to creating inherently interpretable Large Language Models (LLMs). Unlike traditional black-box LLMs that rely on post-hoc interpretation methods with limited neuron function insights, CB-LLM sets a new standard with its built-in interpretability, scalability, and ability to provide clear, accurate explanations. We investigate two essential tasks in the NLP domain: text classification and text generation. In text classification, CB-LLM narrows the performance gap with traditional black-box models and provides clear interpretability. In text generation, we show how interpretable neurons in CB-LLM can be used for concept detection and steering text generation. Our CB-LLMs enable greater interaction between humans and LLMs across a variety of tasks -- a feature notably absent in existing LLMs. Our code is available at https://github.com/Trustworthy-ML-Lab/CB-LLMs.
Concept Bottleneck Language Models For protein design
Nov 09, 2024



We introduce Concept Bottleneck Protein Language Models (CB-pLM), a generative masked language model with a layer where each neuron corresponds to an interpretable concept. Our architecture offers three key benefits: i) Control: We can intervene on concept values to precisely control the properties of generated proteins, achieving a 3 times larger change in desired concept values compared to baselines. ii) Interpretability: A linear mapping between concept values and predicted tokens allows transparent analysis of the model's decision-making process. iii) Debugging: This transparency facilitates easy debugging of trained models. Our models achieve pre-training perplexity and downstream task performance comparable to traditional masked protein language models, demonstrating that interpretability does not compromise performance. While adaptable to any language model, we focus on masked protein language models due to their importance in drug discovery and the ability to validate our model's capabilities through real-world experiments and expert knowledge. We scale our CB-pLM from 24 million to 3 billion parameters, making them the largest Concept Bottleneck Models trained and the first capable of generative language modeling.
Crafting Large Language Models for Enhanced Interpretability
Jul 05, 2024



We introduce the Concept Bottleneck Large Language Model (CB-LLM), a pioneering approach to creating inherently interpretable Large Language Models (LLMs). Unlike traditional black-box LLMs that rely on post-hoc interpretation methods with limited neuron function insights, CB-LLM sets a new standard with its built-in interpretability, scalability, and ability to provide clear, accurate explanations. This innovation not only advances transparency in language models but also enhances their effectiveness. Our unique Automatic Concept Correction (ACC) strategy successfully narrows the performance gap with conventional black-box LLMs, positioning CB-LLM as a model that combines the high accuracy of traditional LLMs with the added benefit of clear interpretability -- a feature markedly absent in existing LLMs.
Linear Explanations for Individual Neurons
May 10, 2024



In recent years many methods have been developed to understand the internal workings of neural networks, often by describing the function of individual neurons in the model. However, these methods typically only focus on explaining the very highest activations of a neuron. In this paper we show this is not sufficient, and that the highest activation range is only responsible for a very small percentage of the neuron's causal effect. In addition, inputs causing lower activations are often very different and can't be reliably predicted by only looking at high activations. We propose that neurons should instead be understood as a linear combination of concepts, and develop an efficient method for producing these linear explanations. In addition, we show how to automatically evaluate description quality using simulation, i.e. predicting neuron activations on unseen inputs in vision setting.