 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgescCBGM: Interpretable Single-Cell Counterfactual Editing
Jun 05, 2026Understanding cellular phenotypes and how they respond to perturbations is critical for disease biology and therapeutic design. Single-cell RNA sequencing enables characterization at cellular resolution, yet the combinatorial space of conditions makes exhaustive experimental mapping infeasible. We introduce single-cell Concept Bottleneck Generative Models (scCBGM), a framework for interpretable and precise counterfactual editing of individual cells. scCBGM adapts concept bottleneck architectures for single-cell data through decoder skip connections and a cross-covariance penalty that promotes disentanglement without dimensional constraints. We extend the framework to flow matching models, enabling concept-guided editing in both encoding-decoding and generation regimes. To enable rigorous evaluation, we develop a synthetic benchmark with ground-truth counterfactuals. Across multiple real datasets, scCBGM demonstrates superior performance in combinatorial generalization and counterfactual prediction, supported by cell-level validation on synthetic data and population-level benchmarks on real datasets.
Concept Bottleneck Language Models For protein design
Nov 09, 2024



We introduce Concept Bottleneck Protein Language Models (CB-pLM), a generative masked language model with a layer where each neuron corresponds to an interpretable concept. Our architecture offers three key benefits: i) Control: We can intervene on concept values to precisely control the properties of generated proteins, achieving a 3 times larger change in desired concept values compared to baselines. ii) Interpretability: A linear mapping between concept values and predicted tokens allows transparent analysis of the model's decision-making process. iii) Debugging: This transparency facilitates easy debugging of trained models. Our models achieve pre-training perplexity and downstream task performance comparable to traditional masked protein language models, demonstrating that interpretability does not compromise performance. While adaptable to any language model, we focus on masked protein language models due to their importance in drug discovery and the ability to validate our model's capabilities through real-world experiments and expert knowledge. We scale our CB-pLM from 24 million to 3 billion parameters, making them the largest Concept Bottleneck Models trained and the first capable of generative language modeling.
Interpretable Mixture of Experts for Structured Data
Jun 05, 2022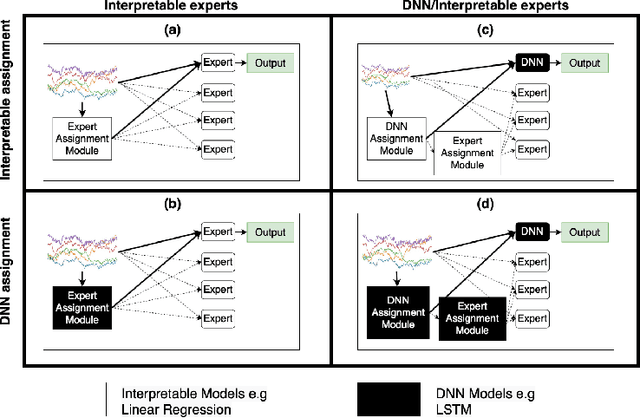
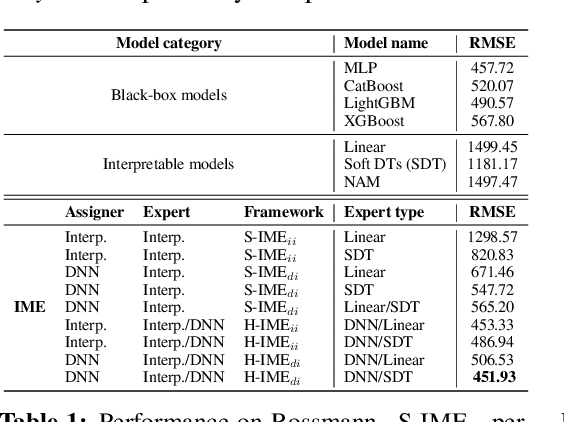
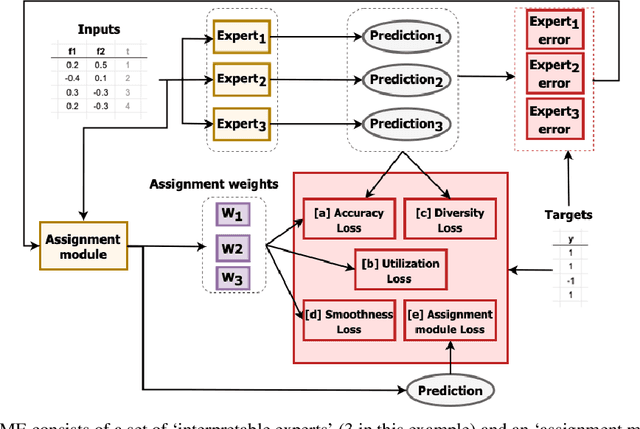
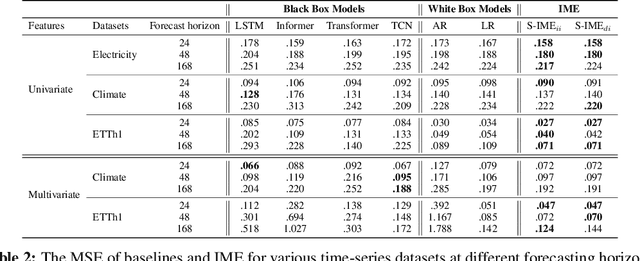
With the growth of machine learning for structured data, the need for reliable model explanations is essential, especially in high-stakes applications. We introduce a novel framework, Interpretable Mixture of Experts (IME), that provides interpretability for structured data while preserving accuracy. IME consists of an assignment module and a mixture of interpretable experts such as linear models where each sample is assigned to a single interpretable expert. This results in an inherently-interpretable architecture where the explanations produced by IME are the exact descriptions of how the prediction is computed. In addition to constituting a standalone inherently-interpretable architecture, an additional IME capability is that it can be integrated with existing Deep Neural Networks (DNNs) to offer interpretability to a subset of samples while maintaining the accuracy of the DNNs. Experiments on various structured datasets demonstrate that IME is more accurate than a single interpretable model and performs comparably to existing state-of-the-art deep learning models in terms of accuracy while providing faithful explanations.
Improving Deep Learning Interpretability by Saliency Guided Training
Nov 29, 2021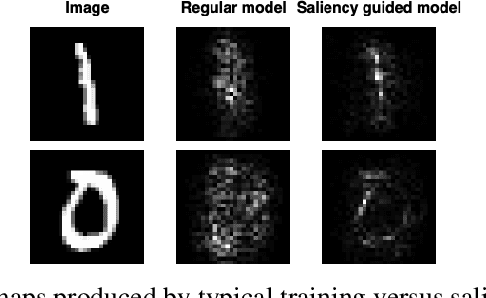
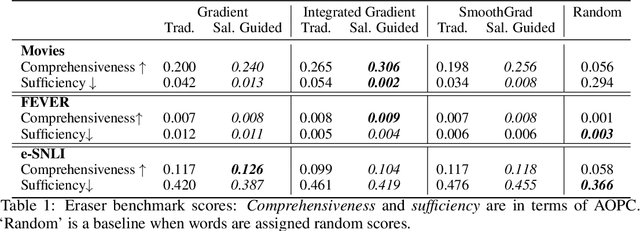
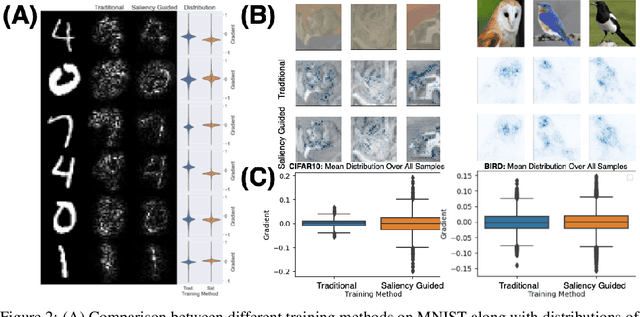
Saliency methods have been widely used to highlight important input features in model predictions. Most existing methods use backpropagation on a modified gradient function to generate saliency maps. Thus, noisy gradients can result in unfaithful feature attributions. In this paper, we tackle this issue and introduce a {\it saliency guided training}procedure for neural networks to reduce noisy gradients used in predictions while retaining the predictive performance of the model. Our saliency guided training procedure iteratively masks features with small and potentially noisy gradients while maximizing the similarity of model outputs for both masked and unmasked inputs. We apply the saliency guided training procedure to various synthetic and real data sets from computer vision, natural language processing, and time series across diverse neural architectures, including Recurrent Neural Networks, Convolutional Networks, and Transformers. Through qualitative and quantitative evaluations, we show that saliency guided training procedure significantly improves model interpretability across various domains while preserving its predictive performance.
Improving Multimodal Accuracy Through Modality Pre-training and Attention
Nov 11, 2020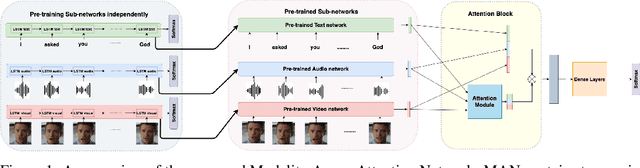
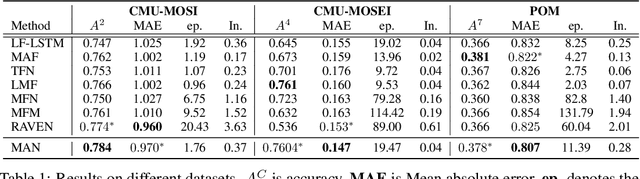
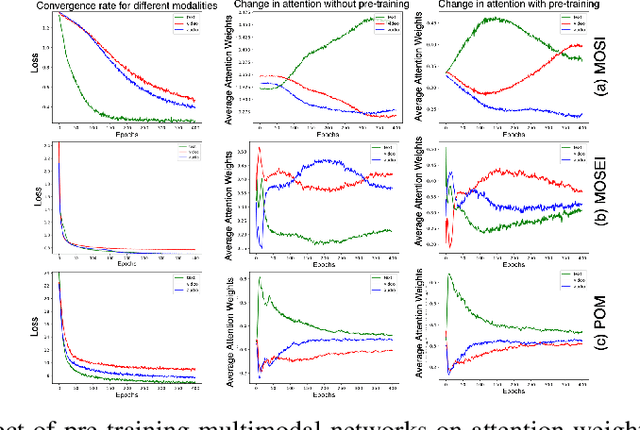

Training a multimodal network is challenging and it requires complex architectures to achieve reasonable performance. We show that one reason for this phenomena is the difference between the convergence rate of various modalities. We address this by pre-training modality-specific sub-networks in multimodal architectures independently before end-to-end training of the entire network. Furthermore, we show that the addition of an attention mechanism between sub-networks after pre-training helps identify the most important modality during ambiguous scenarios boosting the performance. We demonstrate that by performing these two tricks a simple network can achieve similar performance to a complicated architecture that is significantly more expensive to train on multiple tasks including sentiment analysis, emotion recognition, and speaker trait recognition.
Benchmarking Deep Learning Interpretability in Time Series Predictions
Oct 26, 2020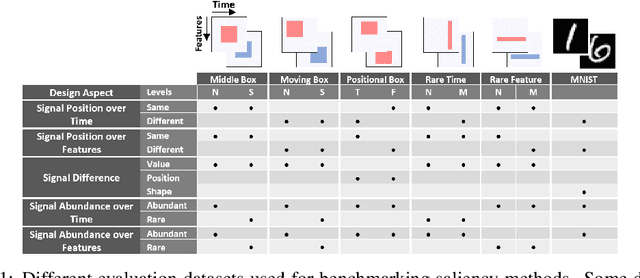
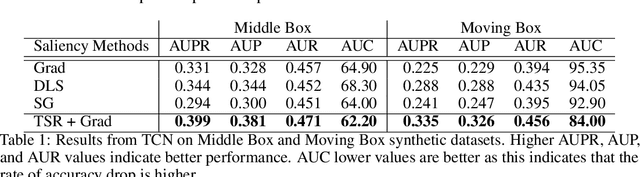
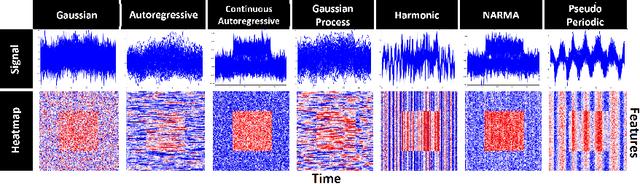

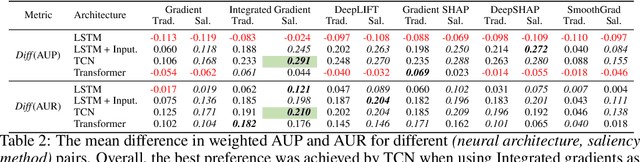
Saliency methods are used extensively to highlight the importance of input features in model predictions. These methods are mostly used in vision and language tasks, and their applications to time series data is relatively unexplored. In this paper, we set out to extensively compare the performance of various saliency-based interpretability methods across diverse neural architectures, including Recurrent Neural Network, Temporal Convolutional Networks, and Transformers in a new benchmark of synthetic time series data. We propose and report multiple metrics to empirically evaluate the performance of saliency methods for detecting feature importance over time using both precision (i.e., whether identified features contain meaningful signals) and recall (i.e., the number of features with signal identified as important). Through several experiments, we show that (i) in general, network architectures and saliency methods fail to reliably and accurately identify feature importance over time in time series data, (ii) this failure is mainly due to the conflation of time and feature domains, and (iii) the quality of saliency maps can be improved substantially by using our proposed two-step temporal saliency rescaling (TSR) approach that first calculates the importance of each time step before calculating the importance of each feature at a time step.
Input-Cell Attention Reduces Vanishing Saliency of Recurrent Neural Networks
Oct 27, 2019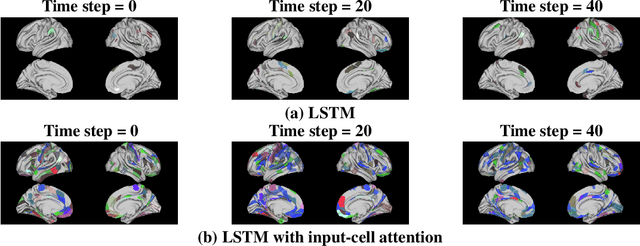
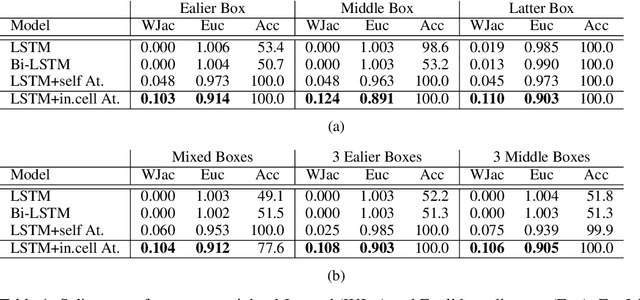
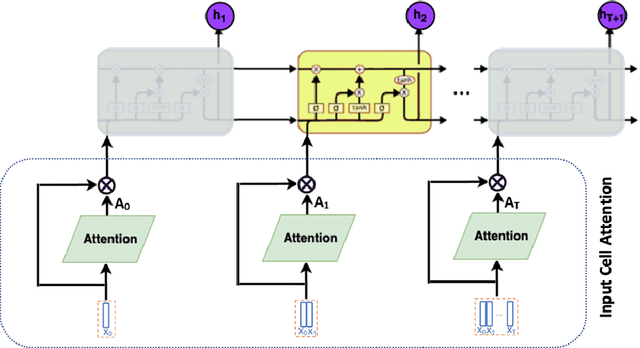
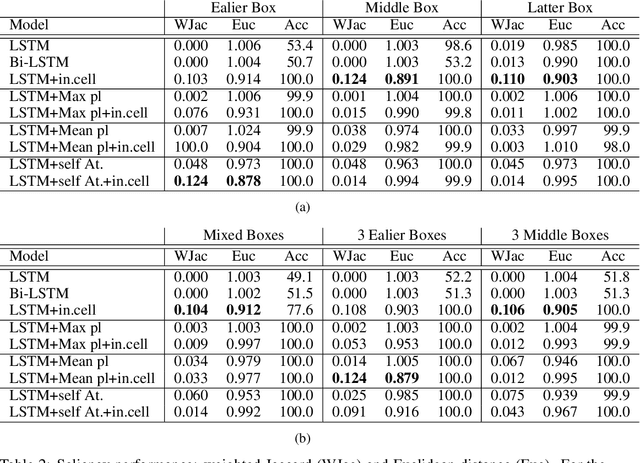
Recent efforts to improve the interpretability of deep neural networks use saliency to characterize the importance of input features to predictions made by models. Work on interpretability using saliency-based methods on Recurrent Neural Networks (RNNs) has mostly targeted language tasks, and their applicability to time series data is less understood. In this work we analyze saliency-based methods for RNNs, both classical and gated cell architectures. We show that RNN saliency vanishes over time, biasing detection of salient features only to later time steps and are, therefore, incapable of reliably detecting important features at arbitrary time intervals. To address this vanishing saliency problem, we propose a novel RNN cell structure (input-cell attention), which can extend any RNN cell architecture. At each time step, instead of only looking at the current input vector, input-cell attention uses a fixed-size matrix embedding, each row of the matrix attending to different inputs from current or previous time steps. Using synthetic data, we show that the saliency map produced by the input-cell attention RNN is able to faithfully detect important features regardless of their occurrence in time. We also apply the input-cell attention RNN on a neuroscience task analyzing functional Magnetic Resonance Imaging (fMRI) data for human subjects performing a variety of tasks. In this case, we use saliency to characterize brain regions (input features) for which activity is important to distinguish between tasks. We show that standard RNN architectures are only capable of detecting important brain regions in the last few time steps of the fMRI data, while the input-cell attention model is able to detect important brain region activity across time without latter time step biases.
Improving Long-Horizon Forecasts with Expectation-Biased LSTM Networks
Apr 18, 2018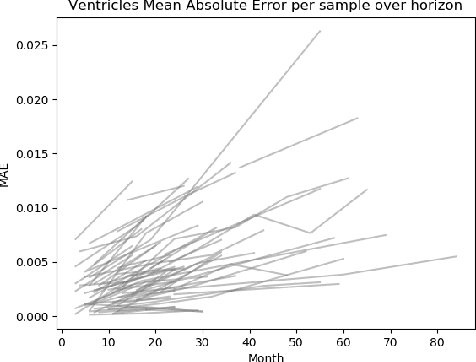
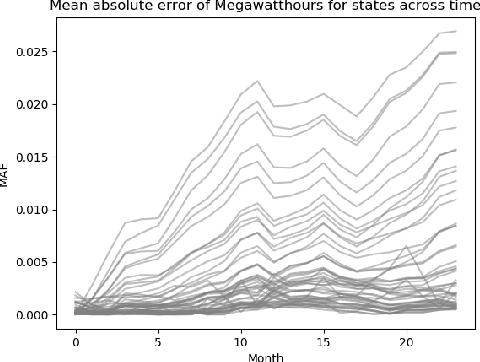
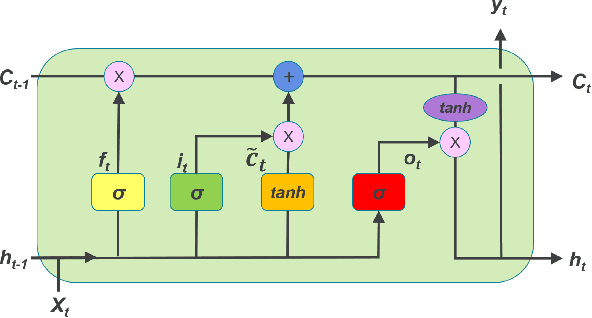
State-of-the-art forecasting methods using Recurrent Neural Net- works (RNN) based on Long-Short Term Memory (LSTM) cells have shown exceptional performance targeting short-horizon forecasts, e.g given a set of predictor features, forecast a target value for the next few time steps in the future. However, in many applica- tions, the performance of these methods decays as the forecasting horizon extends beyond these few time steps. This paper aims to explore the challenges of long-horizon forecasting using LSTM networks. Here, we illustrate the long-horizon forecasting problem in datasets from neuroscience and energy supply management. We then propose expectation-biasing, an approach motivated by the literature of Dynamic Belief Networks, as a solution to improve long-horizon forecasting using LSTMs. We propose two LSTM ar- chitectures along with two methods for expectation biasing that significantly outperforms standard practice.