 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolving CNN Architectures: From Custom Designs to Deep Residual Models for Diverse Image Classification and Detection Tasks
Jan 03, 2026This paper presents a comparative study of a custom convolutional neural network (CNN) architecture against widely used pretrained and transfer learning CNN models across five real-world image datasets. The datasets span binary classification, fine-grained multiclass recognition, and object detection scenarios. We analyze how architectural factors, such as network depth, residual connections, and feature extraction strategies, influence classification and localization performance. The results show that deeper CNN architectures provide substantial performance gains on fine-grained multiclass datasets, while lightweight pretrained and transfer learning models remain highly effective for simpler binary classification tasks. Additionally, we extend the proposed architecture to an object detection setting, demonstrating its adaptability in identifying unauthorized auto-rickshaws in real-world traffic scenes. Building upon a systematic analysis of custom CNN architectures alongside pretrained and transfer learning models, this study provides practical guidance for selecting suitable network designs based on task complexity and resource constraints.
A Structured Bangla Dataset of Disease-Symptom Associations to Improve Diagnostic Accuracy
Jun 16, 2025Disease-symptom datasets are significant and in demand for medical research, disease diagnosis, clinical decision-making, and AI-driven health management applications. These datasets help identify symptom patterns associated with specific diseases, thus improving diagnostic accuracy and enabling early detection. The dataset presented in this study systematically compiles disease-symptom relationships from various online sources, medical literature, and publicly available health databases. The data was gathered through analyzing peer-reviewed medical articles, clinical case studies, and disease-symptom association reports. Only the verified medical sources were included in the dataset, while those from non-peer-reviewed and anecdotal sources were excluded. The dataset is structured in a tabular format, where the first column represents diseases, and the remaining columns represent symptoms. Each symptom cell contains a binary value (1 or 0), indicating whether a symptom is associated with a disease (1 for presence, 0 for absence). Thereby, this structured representation makes the dataset very useful for a wide range of applications, including machine learning-based disease prediction, clinical decision support systems, and epidemiological studies. Although there are some advancements in the field of disease-symptom datasets, there is a significant gap in structured datasets for the Bangla language. This dataset aims to bridge that gap by facilitating the development of multilingual medical informatics tools and improving disease prediction models for underrepresented linguistic communities. Further developments should include region-specific diseases and further fine-tuning of symptom associations for better diagnostic performance
Parkinson's Disease Freezing of Gait (FoG) Symptom Detection Using Machine Learning from Wearable Sensor Data
Jun 14, 2025Freezing of gait (FoG) is a special symptom found in patients with Parkinson's disease (PD). Patients who have FoG abruptly lose the capacity to walk as they normally would. Accelerometers worn by patients can record movement data during these episodes, and machine learning algorithms can be useful to categorize this information. Thus, the combination may be able to identify FoG in real time. In order to identify FoG events in accelerometer data, we introduce the Transformer Encoder-Bi-LSTM fusion model in this paper. The model's capability to differentiate between FoG episodes and normal movement was used to evaluate its performance, and on the Kaggle Parkinson's Freezing of Gait dataset, the proposed Transformer Encoder-Bi-LSTM fusion model produced 92.6% accuracy, 80.9% F1 score, and 52.06% in terms of mean average precision. The findings highlight how Deep Learning-based approaches may progress the field of FoG identification and help PD patients receive better treatments and management plans.
Deep Learning for Breast Cancer Detection: Comparative Analysis of ConvNeXT and EfficientNet
May 24, 2025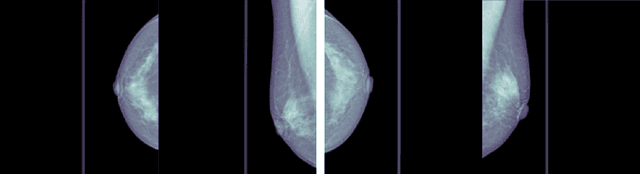
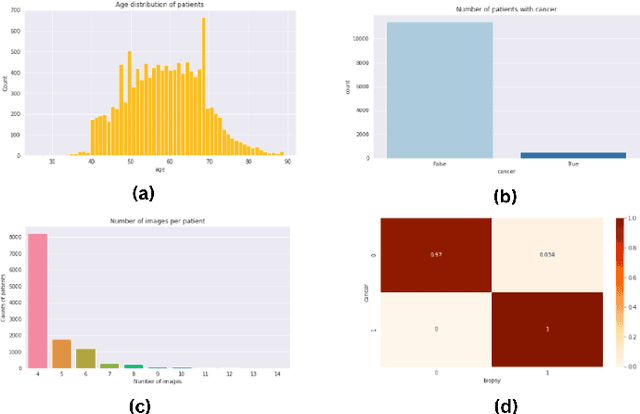
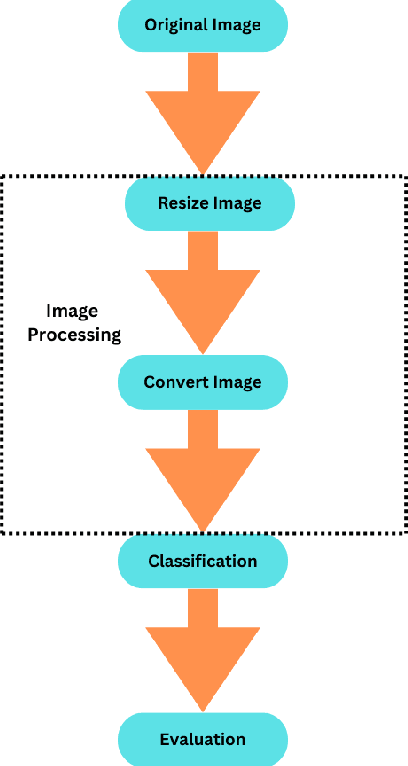
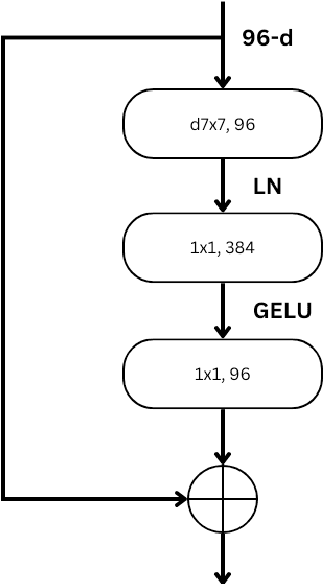
Breast cancer is the most commonly occurring cancer worldwide. This cancer caused 670,000 deaths globally in 2022, as reported by the WHO. Yet since health officials began routine mammography screening in age groups deemed at risk in the 1980s, breast cancer mortality has decreased by 40% in high-income nations. Every day, a greater and greater number of people are receiving a breast cancer diagnosis. Reducing cancer-related deaths requires early detection and treatment. This paper compares two convolutional neural networks called ConvNeXT and EfficientNet to predict the likelihood of cancer in mammograms from screening exams. Preprocessing of the images, classification, and performance evaluation are main parts of the whole procedure. Several evaluation metrics were used to compare and evaluate the performance of the models. The result shows that ConvNeXT generates better results with a 94.33% AUC score, 93.36% accuracy, and 95.13% F-score compared to EfficientNet with a 92.34% AUC score, 91.47% accuracy, and 93.06% F-score on RSNA screening mammography breast cancer dataset.
Unmasking Deep Fakes: Leveraging Deep Learning for Video Authenticity Detection
May 10, 2025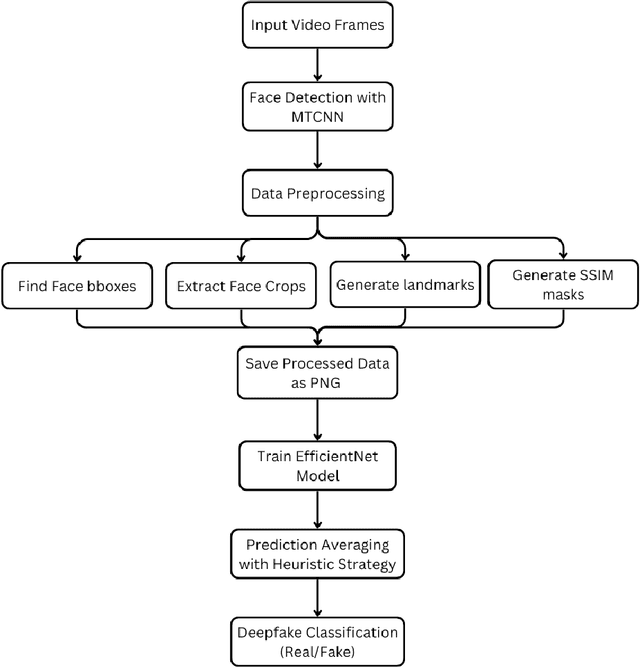

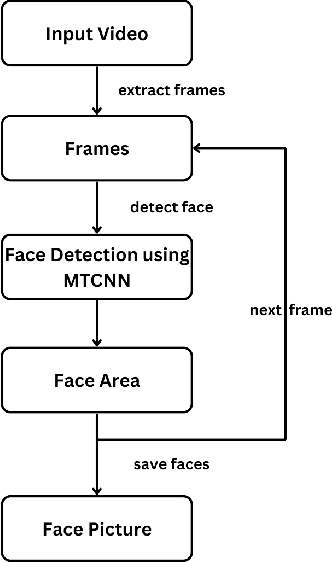

Deepfake videos, produced through advanced artificial intelligence methods now a days, pose a new challenge to the truthfulness of the digital media. As Deepfake becomes more convincing day by day, detecting them requires advanced methods capable of identifying subtle inconsistencies. The primary motivation of this paper is to recognize deepfake videos using deep learning techniques, specifically by using convolutional neural networks. Deep learning excels in pattern recognition, hence, makes it an ideal approach for detecting the intricate manipulations in deepfakes. In this paper, we consider using MTCNN as a face detector and EfficientNet-B5 as encoder model to predict if a video is deepfake or not. We utilize training and evaluation dataset from Kaggle DFDC. The results shows that our deepfake detection model acquired 42.78% log loss, 93.80% AUC and 86.82% F1 score on kaggle's DFDC dataset.
Automatic Vehicle Detection using DETR: A Transformer-Based Approach for Navigating Treacherous Roads
Feb 25, 2025Automatic Vehicle Detection (AVD) in diverse driving environments presents unique challenges due to varying lighting conditions, road types, and vehicle types. Traditional methods, such as YOLO and Faster R-CNN, often struggle to cope with these complexities. As computer vision evolves, combining Convolutional Neural Networks (CNNs) with Transformer-based approaches offers promising opportunities for improving detection accuracy and efficiency. This study is the first to experiment with Detection Transformer (DETR) for automatic vehicle detection in complex and varied settings. We employ a Collaborative Hybrid Assignments Training scheme, Co-DETR, to enhance feature learning and attention mechanisms in DETR. By leveraging versatile label assignment strategies and introducing multiple parallel auxiliary heads, we provide more effective supervision during training and extract positive coordinates to boost training efficiency. Through extensive experiments on DETR variants and YOLO models, conducted using the BadODD dataset, we demonstrate the advantages of our approach. Our method achieves superior results, and improved accuracy in diverse conditions, making it practical for real-world deployment. This work significantly advances autonomous navigation technology and opens new research avenues in object detection for autonomous vehicles. By integrating the strengths of CNNs and Transformers, we highlight the potential of DETR for robust and efficient vehicle detection in challenging driving environments.
Vision Eagle Attention: A New Lens for Advancing Image Classification
Nov 15, 2024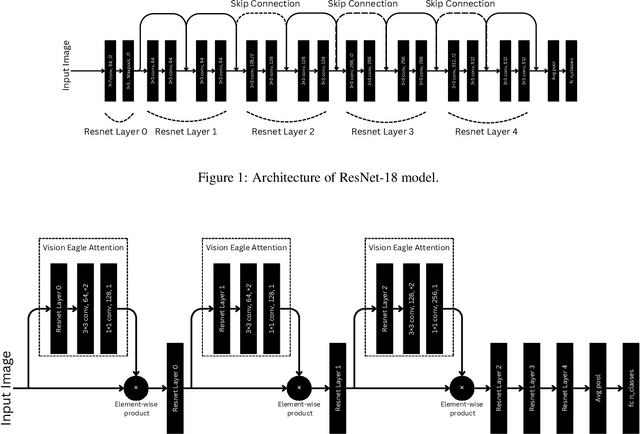

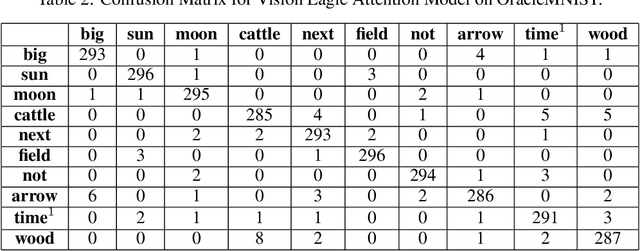

In computer vision tasks, the ability to focus on relevant regions within an image is crucial for improving model performance, particularly when key features are small, subtle, or spatially dispersed. Convolutional neural networks (CNNs) typically treat all regions of an image equally, which can lead to inefficient feature extraction. To address this challenge, I have introduced Vision Eagle Attention, a novel attention mechanism that enhances visual feature extraction using convolutional spatial attention. The model applies convolution to capture local spatial features and generates an attention map that selectively emphasizes the most informative regions of the image. This attention mechanism enables the model to focus on discriminative features while suppressing irrelevant background information. I have integrated Vision Eagle Attention into a lightweight ResNet-18 architecture, demonstrating that this combination results in an efficient and powerful model. I have evaluated the performance of the proposed model on three widely used benchmark datasets: FashionMNIST, Intel Image Classification, and OracleMNIST, with a primary focus on image classification. Experimental results show that the proposed approach improves classification accuracy. Additionally, this method has the potential to be extended to other vision tasks, such as object detection, segmentation, and visual tracking, offering a computationally efficient solution for a wide range of vision-based applications. Code is available at: https://github.com/MahmudulHasan11085/Vision-Eagle-Attention.git
Semi-Supervised Contrastive VAE for Disentanglement of Digital Pathology Images
Oct 02, 2024Despite the strong prediction power of deep learning models, their interpretability remains an important concern. Disentanglement models increase interpretability by decomposing the latent space into interpretable subspaces. In this paper, we propose the first disentanglement method for pathology images. We focus on the task of detecting tumor-infiltrating lymphocytes (TIL). We propose different ideas including cascading disentanglement, novel architecture, and reconstruction branches. We achieve superior performance on complex pathology images, thus improving the interpretability and even generalization power of TIL detection deep learning models. Our codes are available at https://github.com/Shauqi/SS-cVAE.
Ophthalmic Biomarker Detection with Parallel Prediction of Transformer and Convolutional Architecture
Sep 26, 2024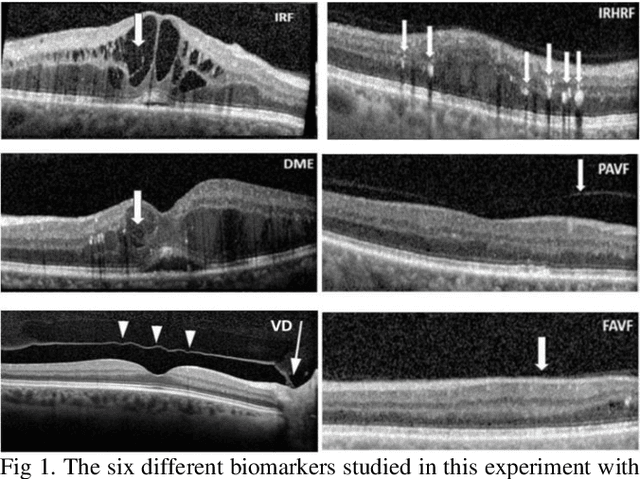
Ophthalmic diseases represent a significant global health issue, necessitating the use of advanced precise diagnostic tools. Optical Coherence Tomography (OCT) imagery which offers high-resolution cross-sectional images of the retina has become a pivotal imaging modality in ophthalmology. Traditionally physicians have manually detected various diseases and biomarkers from such diagnostic imagery. In recent times, deep learning techniques have been extensively used for medical diagnostic tasks enabling fast and precise diagnosis. This paper presents a novel approach for ophthalmic biomarker detection using an ensemble of Convolutional Neural Network (CNN) and Vision Transformer. While CNNs are good for feature extraction within the local context of the image, transformers are known for their ability to extract features from the global context of the image. Using an ensemble of both techniques allows us to harness the best of both worlds. Our method has been implemented on the OLIVES dataset to detect 6 major biomarkers from the OCT images and shows significant improvement of the macro averaged F1 score on the dataset.
Faster, Lighter, More Accurate: A Deep Learning Ensemble for Content Moderation
Sep 10, 2023



To address the increasing need for efficient and accurate content moderation, we propose an efficient and lightweight deep classification ensemble structure. Our approach is based on a combination of simple visual features, designed for high-accuracy classification of violent content with low false positives. Our ensemble architecture utilizes a set of lightweight models with narrowed-down color features, and we apply it to both images and videos. We evaluated our approach using a large dataset of explosion and blast contents and compared its performance to popular deep learning models such as ResNet-50. Our evaluation results demonstrate significant improvements in prediction accuracy, while benefiting from 7.64x faster inference and lower computation cost. While our approach is tailored to explosion detection, it can be applied to other similar content moderation and violence detection use cases as well. Based on our experiments, we propose a "think small, think many" philosophy in classification scenarios. We argue that transforming a single, large, monolithic deep model into a verification-based step model ensemble of multiple small, simple, and lightweight models with narrowed-down visual features can possibly lead to predictions with higher accuracy.